【FAQ】P3. 为什么 torch.cuda.is_available() 是 False
为什么 torch.cuda.is_available() 是 False
torch.cuda.is_available(),这个指令的作用是看,你电脑的 GPU 能否被 PyTorch 调用。
如果返回的结果是 False,可以按照以下过程进行排查。
1、确认你的 GPU,是否支持 CUDA(是否支持被 PyTorch 调用)
首先,确定你的显卡型号,是否是 NVIDIA 显卡。可以从 任务管理器 或者 设备管理器来查看显卡的型号。

之后,去 官网 看,如果其中有你的显卡型号,则说明你的显卡是支持被 PyTorch 调用的。
(绝大多数的 NVIDIA 显卡都是支持的)
如果没有 NVIDIA 显卡的话,也没有关系。CPU 就已经足够了,而且你会在后面的教程看到,对于小型网络,CPU 速度更快(窃喜)
2、打开命令行,输入 nvidia-smi,查看自己的 Driver Version
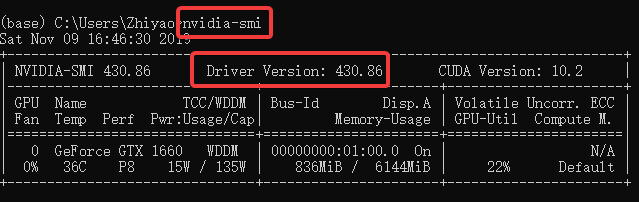
我们教程中安装的 PyTorch 1.3 + CUDA 9.2 版本,要求电脑的显卡驱动大于396.26。
像我截图中的驱动版本为430.86,大于396.26。
如果你的驱动版本小于396.26,请用各种驱动管理软件或者软件管家,去升级你的显卡驱动。当然,更推荐去官网,下载对应的最新驱动。
3、下载最新驱动。在 官方网站 选择相应的显卡型号,操作系统,其他默认。其中的 Notebooks 是指笔记本。
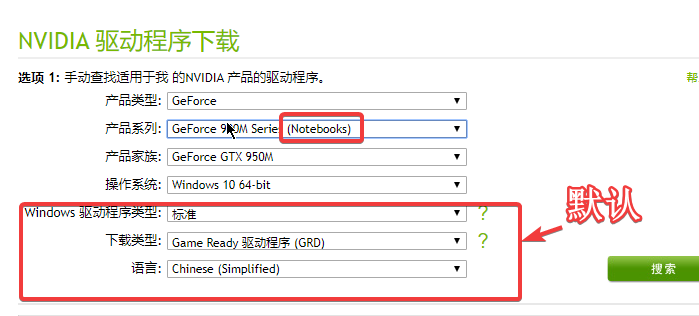
之后,点击搜索,下载最新驱动后,进行安装即可。
4、检查驱动版本。安装完最新的驱动后,可以再次在命令行窗口输入 nvidia-smi,查看最新的版本是否安装成功。
5、打开 Anaconda Prompt,输入 conda activate pytorch,再输入 python,进入 python 环境。
在 python 环境中,输入 import torch, 之后输入 torch.cuda.is_available,查看返回的结果是否是 True。
使用 Conda 下载 PyTorch 速度太慢了,怎么办?
1、(玄学办法) 早上下载安装,感觉早上的时候,下载的速度明显变快。
2、从本教程最顶端的百度云处,下载这两个文件。(这两个文件是适用于 pytorch1.3 + cuda9.2 + windows)
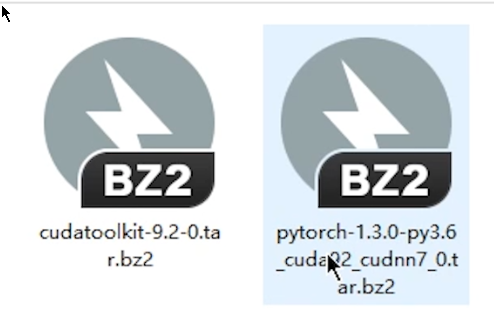
将这两个下载好的文件,放在 Anaconda 安装出的 pkgs 文件夹下。
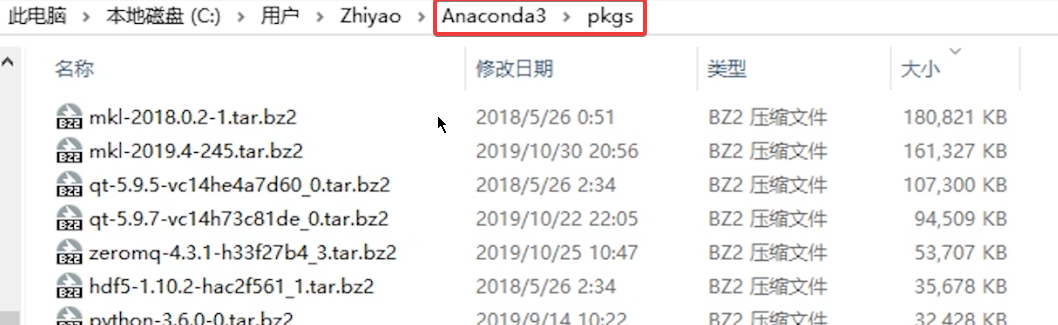
之后打开 Anaconda Prompt,输入 conda activate pytorch。
之后,输入以下指令:conda install --use-local pytorch-1.3.0-py3.6_cuda92_cudnn7_0.tar.bz2 和 conda install --use-local cudatoolkit-9.2-0.tar.bz2,即可使用下载的包进行安装。
我的大本营
寻找有趣或更有效率的事、工具和教程

【FAQ】P3. 为什么 torch.cuda.is_available() 是 False的更多相关文章
- pytorch,cuda8,torch.cuda.is_available return flase (ubuntu14)
因为ubuntu 系统是14.0的,安装pytorch1.0的时候,本身已经安装好了cuda8,在验证gpu的时候,torch.cuda.is_available()返回false 安装命令是: co ...
- torch.cuda.FloatTensor
Pytorch中的tensor又包括CPU上的数据类型和GPU上的数据类型,一般GPU上的Tensor是CPU上的Tensor加cuda()函数得到. 一般系统默认是torch.FloatTensor ...
- one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [3, 1280, 28, 28]], which is output 0 of LeakyReluBackward1, is at version 2;
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace o ...
- pytorch torch.Stroage();torch.cuda()
转自:https://ptorch.com/news/52.html torch.Storage是单个数据类型的连续的一维数组,每个torch.Tensor都具有相同数据类型的相应存储.他是torch ...
- [报错]-RuntimeError: Input type (torch.cuda.HalfTensor) and weight type (torch.cuda.FloatTensor) should be the same
RuntimeError: Input type (torch.cuda.HalfTensor) and weight type (torch.cuda.FloatTensor) should be ...
- 常见错误 RuntimeError: expected type torch.FloatTensor but got torch.cuda.FloatTensor
https://www.jianshu.com/p/0be7a375bdbe https://blog.csdn.net/qq_38410428/article/details/82973895 计算 ...
- pytorch------cpu与gpu load时相互转化 torch.load(map_location=)
将gpu改为cpu时,遇到一个报错: RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is ...
- 伤透了心的pytorch的cuda容器版
公司GPU的机器版本本比较低,找了好多不同的镜像都不行, 自己从anaconda开始制作也没有搞定(因为公司机器不可以直接上网), 哎,官网只有使用最新的NVIDIA驱动,安装起来才顺利. 最后,找到 ...
- 计算机视觉2-> 深度学习 | anaconda+cuda+pytorch环境配置
00 想说的 深度学习的环境我配置了两个阶段,暑假的时候在一个主攻视觉的实验室干活,闲暇时候就顺手想给自己的Ubuntu1804配置一个深度学习的环境.这会儿配到了anaconda+pytorch+c ...
随机推荐
- CentOS7安装codeblocks
1.yum -y install epel-release 2.yum clean all && yum makecache 3.yum -y install gtk2-devel c ...
- 多线程--future模式初体验
第一次使用多线程,虽然理解的不是很透彻,但是也值得记录下.用的是future模式. 创建个线程池:private ExecutorService cachedThreadPool = Executor ...
- java+struts上传文件夹文件
这里只写后端的代码,基本的思想就是,前端将文件分片,然后每次访问上传接口的时候,向后端传入参数:当前为第几块文件,和分片总数 下面直接贴代码吧,一些难懂的我大部分都加上注释了: 上传文件实体类: 看得 ...
- 小样本学习Few-shot learning
One-shot learning Zero-shot learning Multi-shot learning Sparse Fine-grained Fine-tune 背景:CVPR 2018收 ...
- 突破css选择器的局限,实现一个css地址选择器?
首先看一个效果,注意地址栏的变化 然后思考一下,用css如何实现? css选择器的局限 选择器是css中的一大特色,用于选择需要添加样式的元素. 选择器的种类有很多,比如 元素选择器 p {color ...
- Pyhton实用的format()格式化函数
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能. 基本语法是通过 {} 和 : 来代替以前的 % . format 函数可以接受不限个参数 ...
- Oracle数据库用户的密码过期问题处理
SQL> select username, user_id, account_status,expiry_date, profile from dba_users where username ...
- python对象的引用
1 利用 * 星号生成二维及二维以上的list时,特别要注意有的量引用是相同的.如果后面要给list赋值,最好不要这样生成list. 可以先这样生成,再打印输出后,粘贴到程序中重新赋值. a = [[ ...
- python学习笔记:(一)基础语法
一.编码 默认情况下,python3采用的是utf-8,所有字符串都是unicode字符串.如果有其他需要的时候,可以修改为其他的. 如:# _*_ coding:gb2312 _*_ 二.标识符 标 ...
- 虚拟化 RemoteApp 远程接入 源码 免费
远程接入 RemoteApp 虚拟化 源码 免费 1.终端安装与配置: 此远程接入组件的运行原理与瑞友天翼.异速连.CTBS等市面上常见的远程接入产品一样,是透过Windows的终端服务来实现的,速度 ...