Java数据结构与算法(1):线性表
线性表是一种简单的数据类型,它是具有相同类型的n个数据元素组成的有限序列。形如如A0,A1,...,An-1。大小为0的表为空表,称Ai后继Ai-1,并称Ai-1前驱Ai。
printList打印出表元素,makeEmpty置空表,find返回某一项首次出现的位置,insert和remove一般是从表的某个位置插入和删除某个元素;而findKth则返回某个位置上的元素,next和previous会取一个位置作为参数返回前驱元和后继元的值。
表的数组实现
对表的所有操作都可以通过数组实现。数组的存储示意图如下:

这种存储结构的特点是:数据是连续的,随机访问速度快。printList以线性时间执行,findKth操作则话费常数时间。对于插入和删除来说效率是比较低下的,最坏情况下,在位置0的插入需要将所有元素向后移动一个位置。
基于数组的链表实现:
public class MyArrayList<T> implements Iterable<T>{
private static final int DEFAULT_CAPACITY=10;
private int size;
private T[] items;
public MyArrayList() {
doClear();
}
public void clear() {
doClear();
}
public int size() {
return size;
}
public boolean isEmpty() {
return size == 0;
}
public void trimToSize() {
ensureCapacity(size);
}
public boolean add(T x) {
add(size, x);
return true;
}
public void add(int idx, T x) {
if (items.length == size) {
ensureCapacity(size * 2 + 1);
}
for (int i = size; i > idx; i--) {
items[i] = items[i - 1];
}
items[idx] = x;
size++;
}
public T remove(int idx) {
T removedItem = items[idx];
for (int i = idx; i < size - 1; i++) {
items[i] = items[i + 1];
}
size--;
return removedItem;
}
private void doClear() {
size = 10;
ensureCapacity(DEFAULT_CAPACITY);
}
private void ensureCapacity(int newCapacity) {
if (newCapacity < size) {
return;
}
T[] old = items;
items = (T[]) new Object[newCapacity];
for (int i = 0; i < size; i++) {
items[i] = old[i];
}
}
public Iterator<T> iterator() {
return new ArrayListIterator();
}
private class ArrayListIterator implements Iterator<T> {
private int current = 0;
@Override
public boolean hasNext() {
return current < size;
}
@Override
public T next() {
if (!hasNext())
throw new NoSuchElementException();
return items[current++];
}
public void remove() {
MyArrayList.this.remove(--current);
}
}
}
单链表
当需要对表进行频繁的插入删除操作时,数组的实现方式就显得效率过低了。链表由一些列节点组成,这些节点不必在内存中相连。每一个节点均含有表元素和到包含该元素后继元的节点的链。单链表的存储示意图如下:

remove操作只需要移动next引用即可实现:

insert方法需要先添加一个节点,然后执行两次引用的调整:
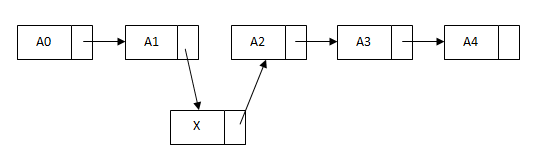
单链表的特点:节点的链接方向是单向的;相对于数组,单链表的随机访问速度较慢,添加、删除效率较高。
双向链表
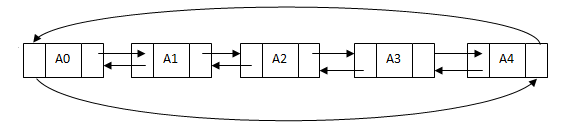
双向链表与单向链表结构相似,由数据元素和两个链组成,这两个链分别指向该节点的前驱和后继。一般构建为双向循环链表,即最后一个节点的next链指向链表的第一个元素,第一个节点的previous链指向链表的最后一个元素。存储结构如下:
双向链表删除:

双向链表的添加就是删除的一个逆过程,不再画图了。
双向链表实现:
public class DoubleLink<T> {
// 表头
private Node<T> head;
// 节点数
private int count;
private class Node<T> {
public Node prev; // 前节点
public Node next; // 后节点
public T value;
public Node(T value, Node prev, Node next) {
this.prev = prev;
this.next = next;
this.value = value;
}
}
public DoubleLink() {
// 创建表头
head = new Node<>(null, null, null);
head.prev = head.next = head;
count = 0;
}
// 节点数
public int size() {
return count;
}
// 判断表是否为空
public boolean isEmpty() {
return count == 0;
}
// 获取第index位置的节点
private Node<T> getNode(int index) {
if (index < 0 || index >= count) {
throw new IndexOutOfBoundsException();
}
// 正向查找
if (index <= count / 2) {
Node<T> node = head.next;
for (int i = 0; i < index; i++) {
node = node.next;
}
return node;
}
// 反向查找
Node<T> rnode = head.prev;
int rindex = count - index - 1;
for (int j = 0; j < rindex; j++) {
rnode = rnode.prev;
}
return rnode;
}
// 获取第index位置节点的值
public T get(int index) {
return getNode(index).value;
}
// 将节点插入到index位置
public void insert(int index, T t) {
if (index == 0) {
Node node = new Node(t, head, head.next);
head.next.prev = node;
head.next = node;
count++;
return;
}
Node<T> inode = getNode(index);
// 创建新节点
Node<T> newNode = new Node<>(t, inode.prev, inode);
inode.prev.next = newNode;
inode.next = newNode;
return;
}
// 删除节点
public Node<T> delete(int index) {
Node<T> delNode = getNode(index);
delNode.prev.next = delNode.next;
delNode.next.prev = delNode.prev;
count--;
return delNode;
}
}
Java数据结构与算法(1):线性表的更多相关文章
- Java数据结构和算法 - 哈希表
Q: 如何快速地存取员工的信息? A: 假设现在要写一个程序,存取一个公司的员工记录,这个小公司大约有1000个员工,每个员工记录需要1024个字节的存储空间,因此整个数据库的大小约为1MB.一般的计 ...
- 【数据结构与算法】线性表操作(C++)
#include <stdio.h> #define maxSize 100 //定义整型常量maxSize值为100 /*顺序表的结构体定义*/ typedef struct SqLis ...
- 【数据结构与算法】线性表操作(C语言)
#include <stdio.h> #include <stdlib.h> #define OK 1 #define NO 0 #define MAXSIZE 20 type ...
- Java数据结构和算法(一)线性结构
Java数据结构和算法(一)线性结构 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 线性表 是一种逻辑结构,相同数据类型的 ...
- Java数据结构和算法(一)线性结构之单链表
Java数据结构和算法(一)线性结构之单链表 prev current next -------------- -------------- -------------- | value | next ...
- 【Java数据结构学习笔记之二】Java数据结构与算法之栈(Stack)实现
本篇是java数据结构与算法的第2篇,从本篇开始我们将来了解栈的设计与实现,以下是本篇的相关知识点: 栈的抽象数据类型 顺序栈的设计与实现 链式栈的设计与实现 栈的应用 栈的抽象数据类型 栈是 ...
- java数据结构与算法之栈(Stack)设计与实现
本篇是java数据结构与算法的第4篇,从本篇开始我们将来了解栈的设计与实现,以下是本篇的相关知识点: 栈的抽象数据类型 顺序栈的设计与实现 链式栈的设计与实现 栈的应用 栈的抽象数据类型 栈是一种用于 ...
- Java数据结构和算法 - 高级排序
希尔排序 Q: 什么是希尔排序? A: 希尔排序因计算机科学家Donald L.Shell而得名,他在1959年发现了希尔排序算法. A: 希尔排序基于插入排序,但是增加了一个新的特性,大大地提高了插 ...
- Java数据结构和算法(一)散列表
Java数据结构和算法(一)散列表 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 散列表(Hash table) 也叫哈希表 ...
随机推荐
- 【官网】2019.5.19 CentOS8.0 最新进展
Contents CentOS 8 Rough Status Page General Steps Architectures Main architectures AltArch Current T ...
- JetBrains视图
三种视图模式:
- jdk8中几个核心的函数式接口笔记
1. Function接口 /** * function 接口测试 * function 函数只能接受一个参数,要接受两个参数,得使用BiFunction接口 */ public class Func ...
- install python+twisted+mysqldb+django on mac
一. install python 1) check install or not 在mac终端输入命令:which python 即可查看python的路径 2)未安装时,手动下载安装包 地址:ht ...
- Python自动化学习--批量执行.py用例
这段时间在摸索自动化,学到执行测试用例的时候发现,执行单用例的时候很简单,如果想多条用例执行的话就没那么简单了,经过几番查找,找到如下方法: unittest模块中的TestLoader类有一个dis ...
- uwsgi支持http长链接
http1.1支持长链接,而http1.0不支持,所以,在切换http版本号或者升级服务端版本时候,尤其要注意这个造成的影响. 当客户端以http1.1长链接方式连接服务端时,服务端如果不支持1.1, ...
- 10年前文章_使用opkg 管理软件更新
为避免调试过程中每次都要刷写flash, 可以使用opkg 管理工具来实现单个包更新 一.首先配置http 服务器,使之能访问生成的ipkg 格式的包,例如你的工作目录在/home/xxx/build ...
- 软件工程大作业(学生会管理系统)Web端个人总结报告
软件工程大作业(学生会管理系统)Web端个人总结报告 一.小组信息 1.所在小组:第二组 2.小组选题:学生会管理系统 3.项目源代码链接: Web端源代码:code 小程序端源代码:code APP ...
- Spring AOP注解配置demo
https://blog.csdn.net/yhl_jxy/article/details/78815636#commentBox
- 高并发-原子性-AtomicInteger
线程不安全: //请求总次数private static int totalCount = 10000;//最大并发数private static int totalCurrency = 100;// ...