HAWQ技术总结
HAWQ技术总结:
1、 官网: http://hawq.incubator.apache.org/
2、 特性
2.1 sql支持完善
ANSI SQL标准,OLAP扩展,标准JDBC/ODBC支持。
2.2 具有MPP的性能。
2.3 支持外部数据整合。
HAWQ能够访问HDFS上的Json文件、Hive、HBase等外部数据。
2.4 支持ACID事务。
这是很多现有基于SqlonHadoop引擎无法做到的,能够好的保证数据一致性。
3、 优缺点:
优点:
* sql支持度好:目前能支持SQL99,SQL2003标准
* 支持事务。
* 支持insert
缺点:
* 基于GreenPlum实现,技术实现复杂,包含多个组件。比如对于外部数据源,需要通过PXF单独进行处理;
* C++实现,对内存的控制比较复杂,如果出现segmentfault直接导致当前node挂掉。
* 安装配置复杂;
4、 关键技术:
4.1 系统架构与关键组件
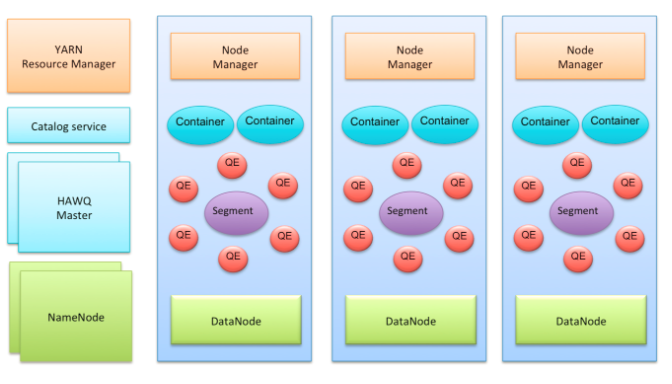
HAWQ集群的主要组件。其中有几个Master节点:包括HAWQ master节点,HDFS master节点NameNode,YARN master节点ResourceManager。每个Slave节点上部署有HDFS DataNode,YARN NodeManager以及一个HAWQ Segment。HAWQ Segment在执行查询的时候会启动多个QE (Query Executor, 查询执行器)。
查询执行器运行在资源容器里。在这个架构下,节点可以动态的加入集群,并且不需要数据重分布。当一个节点加入集群时,它会向HAWQ++ Master节点发送心跳,然后就可以接收未来查询了。
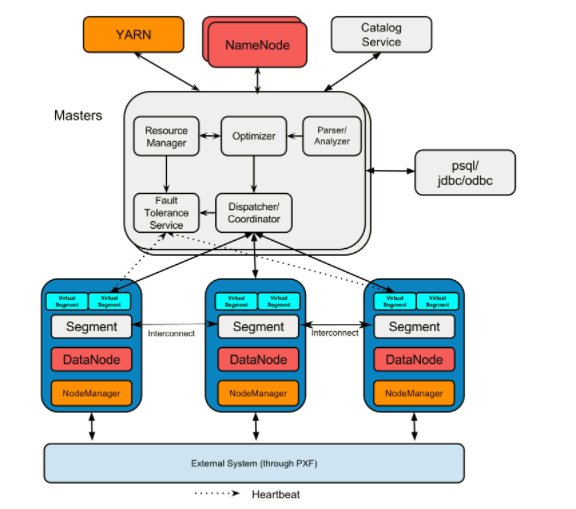
上图是HAWQ master节点内部架构图。可以看到在HAWQ的 Master节点内部有如下重要组件:查询解析器,优化器,资源代理,资源管理器,HDFS元数据缓存,容错服务,查询派遣器和元数据服务。在Slave节点上安装有一个物理Segment,在查询执行时,针对一个查询,弹性执行引擎会启动多个虚拟Segment同时执行查询,节点间数据交换通过Interconnect(高速互联网络,基于UDP)进行。如果一个查询启动了1000个虚拟Segment,意思是这个查询被均匀的分成了1000份任务,这些任务会并行执行。
其中,资源管理器通过资源代理向全局资源管理器(比如YARN)动态申请资源,并缓存资源。在不需要的时候返回资源。缓存资源的主要原因是减少HAWQ与yarn之间的交互代价。因为HAWQ是支持ms级查询。如果每一个查询都向资源管理器申请资源的话,性能会受到影响。位置信息存储在HDFS NameNode上。如果每个查询都访问HDFS NameNode会造成NameNode的瓶颈。所以在HAWQ Master节点上建立了HDFS元数据缓存。查询派遣器则是在优化完查询以后,蒋计划派遣到各个节点上执行,并协调查询执行。
4.2 PXF扩展框架
HAWQ通过名为Pivotal eXtension Framework(PXF)的模块提供数据联合功能。除了常见的数据联合功能外,PXF还利用SQL on Hadoop提供可扩展的功能,PXF提供框架API 使得开发人员能够数据堆栈开发新的连接器,从而增强强数据引擎的松散耦合。
4.3 GPORCA查询优化器
在分区查询、子查询、去重聚合、insert上改进优化。
5、 Benchmark
完全支持TPC-DS.
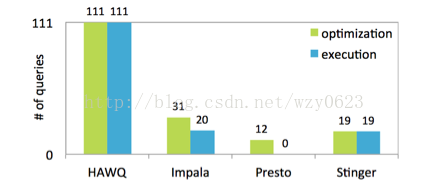
图中所示的基准测试是通过TPC-DS中的99个模板生成的111个查询来执行的。图中显示了4种基于SQL-on-Hadoop常见系统的合规等级,绿色和蓝色分别表示:每个系统可以优化的查询个数;可以完成执行并返回查询结果的查询个数。从图中可以看到,HAWQ完成了所有查询
HAWQ技术总结的更多相关文章
- HAWQ技术解析(八) —— 大表分区
一.HAWQ中的分区表 与大多数关系数据库一样,HAWQ也支持分区表.这里所说的分区表是指HAWQ的内部分区表,外部分区表在后面"外部数据"篇讨论. 在数据仓库应用中 ...
- HAWQ技术解析(十八) —— 问题排查
(原文地址:http://hawq.incubator.apache.org/docs/userguide/2.1.0.0-incubating/troubleshooting/Troubleshoo ...
- HAWQ技术解析(四) —— 启动停止
前面已经完毕了HAWQ的安装部署,也了解了HAWQ的系统架构与主要组件,以下開始使用它. HAWQ作为Hadoop上的一个服务提供给用户,与其他全部服务一样.最主要的操作就是启动.停止 ...
- HAWQ取代传统数仓实践(十八)——层次维度
一.层次维度简介 大多数维度都具有一个或多个层次.例如,示例数据仓库中的日期维度就有一个四级层次:年.季度.月和日.这些级别用date_dim表里的列表示.日期维度是一个单路径层次,因为除了年-季度- ...
- 利用Flume将MySQL表数据准实时抽取到HDFS
转自:http://blog.csdn.net/wzy0623/article/details/73650053 一.为什么要用到Flume 在以前搭建HAWQ数据仓库实验环境时,我使用Sqoop抽取 ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- HAWQ取代传统数仓实践(九)——维度表技术之退化维度
退化维度技术减少维度的数量,简化维度数据仓库模式.简单的模式比复杂的更容易理解,也有更好的查询性能. 有时,维度表中除了业务主键外没有其它内容.例如,在本销售订单示例中,订单维度表除了订 ...
- HAWQ取代传统数仓实践(十七)——事实表技术之累积度量
累积度量指的是聚合从序列内第一个元素到当前元素的数据,例如统计从每年的一月到当前月份的累积销售额.本篇说明如何在销售订单示例中实现累积月销售数量和金额,并对数据仓库模式.初始装载.定期装载做相应地修改 ...
- HAWQ取代传统数仓实践(十五)——事实表技术之无事实的事实表
一.无事实事实表简介 在多维数据仓库建模中,有一种事实表叫做"无事实的事实表".普通事实表中,通常会保存若干维度外键和多个数字型度量,度量是事实表的关键所在.然而在无事实的事实表中 ...
随机推荐
- Vue-Quill-Editor 富文本编辑器
通俗来说:富文本,就是比较丰富的文本编辑器.普通的框只能输入文字,而富文本还能给文字加颜色样式等. 富文本编辑器有很多,例如:KindEditor.Ueditor.但并不原生支持vue 但是我们今天要 ...
- RF分层测试
这一节来介绍分层的概念,在编写自动化测试时经常会遇到重复的操作,分层的概念就是把重复的操作封装成 “用户关键字”,这样就可以减少冗余. 百度搜索实例 同样以百度搜索为例,当我们多个用例都是使用百度搜索 ...
- AVCaptureSession拍照,摄像,载图总结
AVCaptureSession [IOS开发]拍照,摄像,载图总结 1 建立Session 2 添加 input 3 添加output 4 开始捕捉 5 为用户显示当前录制状态 6 捕捉 7 ...
- php 操作分表代码
//哈希分表 function get_hash_table($table, $userid) { $str = crc32($userid); if ($str < 0) { $hash = ...
- LVS集群的ipvsadm命令用法
准备一台Linux服务器,安装ipvsadm软件包,练习使用ipvsadm命令,实现如下功能: - 使用命令添加基于TCP一些的集群服务 - 在集群中添加若干台后端真实服务器 - 实现同一客户端访问, ...
- .net core Consul
创建API项目修改Program public class Program { public static void Main(string[] args) { CreateWebHostBuilde ...
- 「版本升级」界面控件Kendo UI正式发布R2 2019|附下载
通过70多个可自定义的UI组件,Kendo UI可以创建数据丰富的桌面.平板和移动Web应用程序.通过响应式的布局.强大的数据绑定.跨浏览器兼容性和即时使用的主题,Kendo UI将开发时间加快了50 ...
- spring security基本知识(三) 过滤详细说明
在我们前面的文章Spring Security 初识(一)中,我们看到了一个最简单的 Spring Security 配置,会要求所有的请求都要经过认证.但是,这并不是我们想要的,我们通常想自定义应用 ...
- man du
DU(1) User Commands/用户命令 DU(1) NAME/名字 du - estimat ...
- R语言-变量命名规则
1.大原则:只有字母(区分大小写).数字.“_”(下划线).“.”(英文句号)可以出现. 2.数字.下划线不能开头. 3.英文句号开头不能紧接数字. 就这么简单!