44 答疑(三)--join的写法/Simple nested loop join的性能问题/Distinct和group by的性能/备库自增主键问题
44 答疑(三)
Join的写法
35节介绍了join执行顺序,加了straight_join,两个问题:
--1 如果用left join,左边的表一定是驱动表吗
--2 如果两个表的join包含多个条件的等值匹配,是都要写到on里面呢,还是只把一个写到on,把其他的条件写到where部分?
create table a(f1 int, f2 int, index(f1))engine=innodb;
create table b(f1 int, f2 int)engine=innodb;
insert into a values(1,1),(2,2),(3,3),(4,4),(5,5),(6,6);
insert into b values(3,3),(4,4),(5,5),(6,6),(7,7),(8,8);
表a和b都有两个字段f1和f2,不同的是表a的字段上有f1的索引,两种写法
select * from a left join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q1*/
select * from a left join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q2*/
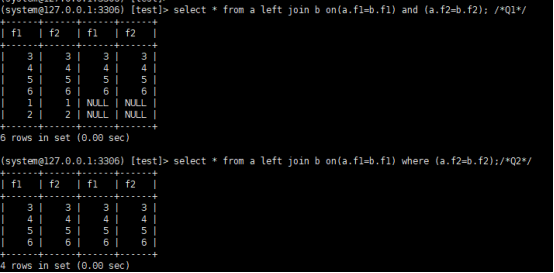
可以看到q1查询返回的数据集是6行,表a中没有满足匹配条件的记录,查询结果中也会返回,并把b的各个字段为null,语句q2返回4行,where是过滤条件,最后执行。

--驱动表是a,被驱动表是b
--由于表b的f1字段上没有索引,所以使用的是block nested loop(BNL)算法,具体执行流程
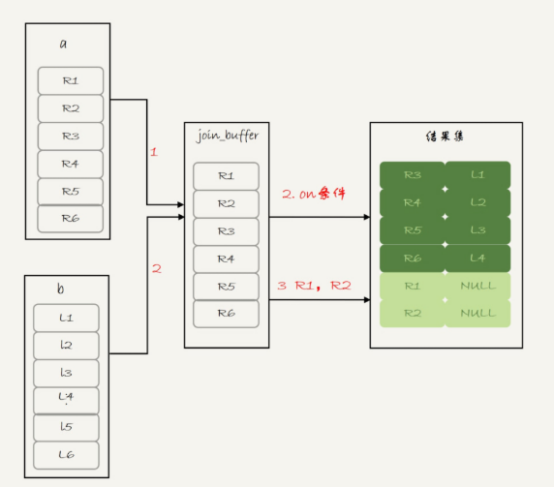
---1 把表a的内如读入join_buffer,这里select *,所有字段f1和f2放入了join_buffer
---2 顺序扫描表b,对于每一行数据,判断join条件(也就是a.f1=b.f1 and a.f2=b.f2)是否满足,满足条件的记录,作为结果集的一行返回,如果语句中有where条件,需要先判断where部分,满足条件后在返回
--3 表b扫描完成后,对于没有被匹配的表a的行,把剩余字段补上null,放入结果集中。
看q2的执行计划

这个语句以表b为驱动表,如果一个join语句的extra中扫描都没有写的话,表示使用的是index nested-loop join(NLJ)算法。Q2的执行流程
--顺序扫描表b,每一行用b.f1到a中去查,匹配到记录后判断a.f2=b.f2,满足条件的话就作为结果集的一部分返回。
在语句q2里面,where a.f2=b.f2表示,结果集不会包含b.f2=null的行,从语义上跟join一致,优化器改成了join,然后因为表a上f1有索引,就把b作为驱动表,a为被驱动表,使用nlj算法,使用show warnings可以看到优化器改写之后的语句,跟参数sql_mode有关。
在left join中,左边的表不一定是驱动表。
如果需要left join的语义,就不能把被驱动表的字段放在where条件里面做等值判断或者不等值判断,必须都写在on里面。
select * from a join b on(a.f1=b.f1) and (a.f2=b.f2); /*Q3*/
select * from a join b on(a.f1=b.f1) where (a.f2=b.f2);/*Q4*/
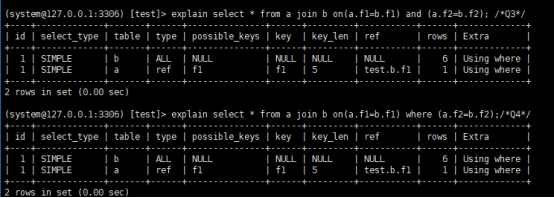
2个语句的执行计划是一样的。
Simple nested loop join的性能问题
35节中提到bnl算法和simple nested loop join算法都是需要判断M*N次(m,n分别是join的表的行数),但是在simple nested loop join算法的每轮判断都需要走全表扫描,因此性能上bnl算法执行起来会快很多。
BNL算法的执行逻辑:
--1首先,将驱动表的数据全部读入内存join_buffer中,这里join_buffer是无序数组
--2 然后,顺序遍历被驱动表的所有行,每一行数据都跟join_buffer中的数据进行匹配,匹配成功则作为结果集的一部分返回。
Simple nested loop join算法执行的逻辑是:顺序取出驱动表中的每一行数据,到被驱动表中做全表扫描匹配,匹配成功则作为结果集的一部分返回。
Simple nested loop join算法其实也是把数据读入内存里,然后按照条件进行判断,为什么性能差距胡这么大
--解释这个问题,需要用到mysql中索引结构和buffer pool的相关知识
--1 在对被驱动表做全表扫描的时候,如果数据没有在buffer pool中,就需要等待这部分数据从磁盘读入:从磁盘读取数据到内存,会影响正常业务的buffer pool命中率,
而且这个算法会对驱动表的数据做多次访问,更容易将这些数据页放到buffer pool的头部,
--2 即使被驱动表数据都在内存中,每次查找”下一个记录操作”,都是类似指针操作。而join_buffer中是数组,遍历的成本更低。
所以说,BNL算法的性能会更好些
Distinct和group by的性能
如果只需要去重,不需要执行聚合函数,distinct和group by那种效率更高?
select a from t group by a order by null;
select distinct a from t;
首先要说明,这种group by的写法,并不是sql标准写法,标准的group by语句是需要在select部分加一个聚合函数
select a,count(*) from t group by a order by null;
按照字段a分组,计算每组的a出现的次数,在这个结果里,由于做的是聚合计算,相同的a只出现一次。没有了count(*)之后,就不再需要执行”计算总数”的逻辑第一条语句就变成,
按照字段a做分组,相同的a的值只返回一行,而这就是distinct的语义,所以不需要执行聚合函数时,distinct和group by这两条语句的语义和执行流程是相同,因此性能也相同。
--1 创建一个临时表,临时表有一个字段a,并且这个字段a上创建一个唯一索引
--2 遍历表t,依次取出数据插入临时表中:
---如果发现唯一键冲突,就跳过
---否则插入成功
--3 遍历完成后,将临时表作为结果集返回给客户端。
备库自增主键问题
create table t(id int auto_increment primary key);
insert into t values(null);
在binlog_format=statement时,语句a先获取id=1,然后语句b获取id=2,b提交,写binlog,然后a在提交写binlog,如果在备库重放,是不是会发生语句b获取的id为1,语句a获取的id为2的情况?
通过解析binlog文件发现,在insert语句之前,有set insert_id=1,这条命令的意思,这个线程下一次需要用到自增值的时候,不论当前表的自增值是多少,固定用1这个值,所以如果b语句先提交,在binlog就是这样
SET INSERT_ID=2;
语句 B;
SET INSERT_ID=1;
语句 A;
所以,在备库执行的时候,自增主键的值是不会不一致的。
44 答疑(三)--join的写法/Simple nested loop join的性能问题/Distinct和group by的性能/备库自增主键问题的更多相关文章
- 浅谈SQL Server中的三种物理连接操作(Nested Loop Join、Merge Join、Hash Join)
简介 在SQL Server中,我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge J ...
- 1122MySQL性能优化之 Nested Loop Join和Block Nested-Loop Join(BNL)
转自http://blog.itpub.net/22664653/viewspace-1692317/ 一 介绍 相信许多开发/DBA在使用MySQL的过程中,对于MySQL处理多表关联的方式或者说 ...
- Oracle 表的连接方式(1)-----Nested loop join和 Sort merge join
关系数据库技术的精髓就是通过关系表进行规范化的数据存储,并通过各种表连接技术和各种类型的索引技术来进行信息的检索和处理. 表的三种关联方式: nested loop:从A表抽一条记录,遍历B表查找匹配 ...
- Merge join、Hash join、Nested loop join对比分析
简介 我们所常见的表与表之间的Inner Join,Outer Join都会被执行引擎根据所选的列,数据上是否有索引,所选数据的选择性转化为Loop Join,Merge Join,Hash Join ...
- join中级篇---------hash join & merge join & nested loop Join
嵌套循环连接(Nested Loop Join) 循环嵌套连接是最基本的连接,正如其名所示那样,需要进行循环嵌套,嵌套循环是三种方式中唯一支持不等式连接的方式,这种连接方式的过程可以简单的用下图展示: ...
- 三大表连接方式详解之Nested loop join和 Sort merge join
在早期版本,Oracle提供的是nested-loop join,两表连接就相当于二重循环,假定两表分别有m行和n行 如果内循环是全表扫描,时间复杂度就是O(m*n) 如果内循 ...
- 禁用nested loop join里的spool
禁用nested loop join里的spool 转载自: https://blogs.msdn.microsoft.com/psssql/2015/12/15/spool-operator-and ...
- SQL Server nested loop join 效率试验
从很多网页上都看到,SQL Server有三种Join的算法, nested loop join, merge join, hash join. 其中最常用的就是nested loop join. 在 ...
- oracle多表连接方式Hash Join Nested Loop Join Merge Join
在查看sql执行计划时,我们会发现表的连接方式有多种,本文对表的连接方式进行介绍以便更好看懂执行计划和理解sql执行原理. 一.连接方式: 嵌套循环(Nested Loops (NL) ...
随机推荐
- 解决stanfordnlp一直运行不报错也没有结果
最近学习stanfordnlp,当运行程序时,发现程序一直没有反应,上网查询说是内存不够,但是本地电脑是8g内存.后来重新下载了所需文件,问题解决.
- bootstrap table实现iview固定列的效果
因为bootstrap自带的固定列效果满足不了公司需求,所以借助fixed-table这个插件完成了iview固定列的效果 <!DOCTYPE html> <html lang=&q ...
- QKeyEvent
#include<QKeyEvent>键盘事件由两个重载函数,实现即可: void keyReleaseEvent(QKeyEvent *event); void keyPressEv ...
- Manjaro系统和软件安装记录
Linux桌面环境 ArchLinux官方wiki manjaro官方wiki pacman官方wiki 从www.distrowatch.com可以查看Linux发行版排行榜,可以看到manjar ...
- 超级POM
在一个有POM的文件夹下执行: mvn help:effective-pom 会输出一个超级POM文件,可以就该文件,进行分析.
- @transactional注解在什么情况下会失效,为什么?
一,特性: 1,一般在service里加@Transactional注解,不建议在接口上添加,加了此注解后此类会纳入spring事务管理中,每个业务方法执行时,都会开启一个事务,不过都是按照相同的管理 ...
- linux C++ 通讯架构(一)nginx安装、目录、进程模型
nginx是C语言开发的,号称并发处理百万级别的TCP连接,稳定,热部署(运行时升级),高度模块化设计,可以用C++开发. 一.安装和目录 1.1 前提 epoll,linux内核版本为2.6或以上 ...
- 【leetcode】1156. Swap For Longest Repeated Character Substring
题目如下: Given a string text, we are allowed to swap two of the characters in the string. Find the leng ...
- webstorm注册码,亲测2016.1.1版
打开webstorm,点击帮助,注册 注册时,在打开的License Activation窗口中选择“License server”,在输入框输入下面的网址: http://idea.iteblog. ...
- B/S上传文件夹
文件夹数据库处理逻辑 publicclass DbFolder { JSONObject root; public DbFolder() { this.root = new JSONObject(); ...