scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium
今日内容概要
- scrapy架构和目录介绍
- scrapy解析数据
- setting中相关配置
- 全站爬取cnblgos文章
- 存储数据
- 爬虫中间件和下载中间件
- 加代理,加header,集成selenium
内容详细
1、scrapy架构和目录介绍
# pip3 install scrapy
# 创建项目:scrapy startproject cnblogs_spider 等同于django创建项目
# 创建爬虫:scrapy genspider cnblogs www.cnblogs.com 等同于创建app
本质就是在spiders文件夹下创建一个py文件,写入一些代码
# 运行爬虫:scrapy crawl 爬虫名
1.1 项目目录介绍
cnblogs_spider # 项目名字
-cnblogs_spider # 项目下一级文件夹
--spiders # 项目下二级文件夹,下面放了一个个爬虫文件
---__init__.py
---cnblogs.py # 创建的一个个的爬虫文件
-__init__.py
-items.py # 模型类写了一些字段---》类似于django的models
-middlewares.py # 中间件:爬虫中间件和下载中间件
-pipelines.py # 管道:存储数据的代码写在这
-settings.py # 项目的配置文件
-scrapy.cfg # 项目上线需要用到,不用管
# 重点:
咱们以后主要是在cnblogs.py 爬虫文件中写爬取和解析的逻辑,pipelines.py写存储
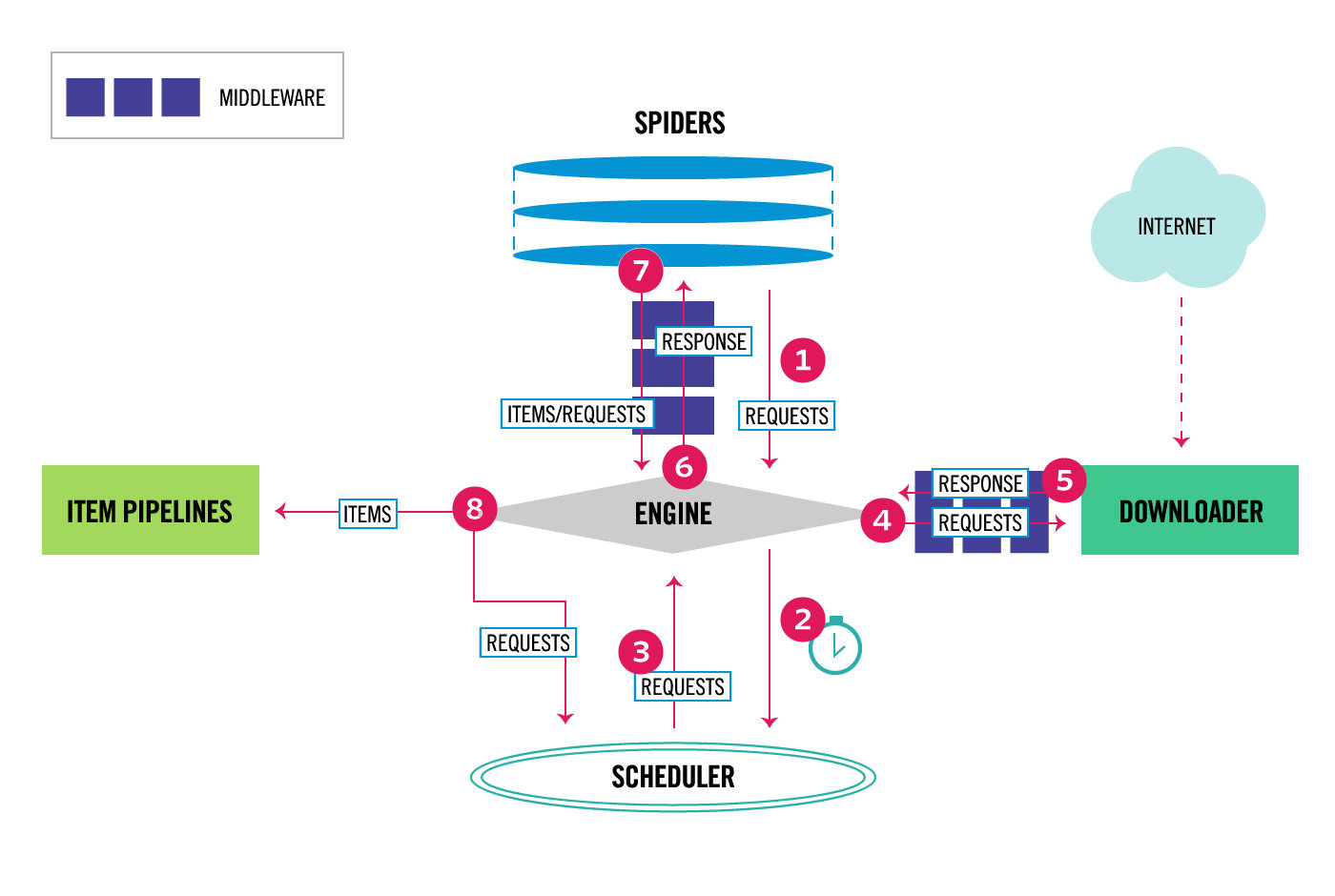
1.2 scrapy架构
# 引擎(EGINE)-->大总管,负责全部的数据流向--》内置的,咱们不需要写
引擎负责控制系统所有组件之间的数据流,并在某些动作发生时触发事件
# 调度器(SCHEDULER)---》对要爬取的地址进行排队,去重
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回
可以想像成一个URL的优先级队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
# 下载器(DOWLOADER)--》真正负责下载---》高效的异步模型
用于下载网页内容, 并将网页内容返回给EGINE,下载器是建立在twisted这个高效的异步模型上的
# 爬虫(SPIDERS)--》咱们重点写的地方,解析响应,从响应中提取要保存的数据和下一次爬取的地址
SPIDERS是开发人员自定义的类,用来解析responses,并且提取items,或者发送新的请求
# 项目管道(ITEM PIPLINES)---》存储数据的逻辑---》可以存到文件,redis,mysql。。。
在items被提取后负责处理它们,主要包括清理、验证、持久化(比如存到数据库)等操作
# 下载器中间件(Downloader Middlewares)--》用的多
位于Scrapy引擎和下载器之间,主要用来处理从EGINE传到DOWLOADER的请求request(加请求头,加cookie,加代理),已经从DOWNLOADER传到EGINE的响应response进行一些处理
# 爬虫中间件(Spider Middlewares)---》用的少
位于EGINE和SPIDERS之间,主要工作是处理SPIDERS的输入(即responses)和输出(即requests)
1.3 py文件直接运行爬虫
# 在项目根目录下创建一个运行脚本
# 右键运行它就可以运行爬虫,不需要每次都敲命令
from scrapy import cmdline
# cmdline.execute(['scrapy', 'crawl', 'cnblogs', '--nolog']) # 不打印日志
cmdline.execute(['scrapy', 'crawl', 'cnblogs']) # 打印日志
2、scrapy解析数据
################################### 重点
1 response对象有css方法和xpath方法
css中写css选择器
xpath中写xpath选择
2 重点1:
xpath取文本内容
'.//a[contains(@class,"link-title")]/text()'
xpath取属性
'.//a[contains(@class,"link-title")]/@href'
css取文本
'a.link-title::text'
css取属性
'img.image-scale::attr(src)'
3 重点2:
.extract_first() 取一个
.extract() 取所有
3、setting中相关配置
3.1 基本配置
# 两套配置,内置一套,用户一套
ROBOTSTXT_OBEY = False # 是否遵循爬虫协议,如果写了它,一般网站都不让爬,基本写成false
USER_AGENT = '浏览器头' # 爬虫请求头中USER_AGENT是什么,做成浏览器的样子
LOG_LEVEL='ERROR' # 日志级别改成ERROR,以后错误日志会打印,普通日志不打印
#---------#####-------
SPIDER_MIDDLEWARES=[] # 爬虫中间件,可以写多个
DOWNLOADER_MIDDLEWARES=[] # 下载中间件类,配置在这,可以配多个
ITEM_PIPELINES=[] # 保存数据,会执行到的类,类内部写保存逻辑
3.2 提高爬虫效率
# 1 增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100
# 2 降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = 'INFO'
# 3 禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
# 4 禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
# 5 减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 10 超时时间为10s
4、全站爬取cnblgos文章
# 只爬了首页---》下一页,文章详情页没有爬取
# 文章--》文章对象(标题,作者,摘要,详情。。。)---》把整站都爬取完成
4.1 request和response对象传递参数
# 在request中通过meta传递
yield Request(url=article_url,callback=self.parse_detail,meta={'item':item})
# 在response中通过meta取出
item=response.meta.get('item')
4.2 解析出下一页地址并继续爬取
# 使用
yield Request(url=article_url,callback=self.parse_detail,meta={'item':item})
yield Request(url=next_url)
5、存储数据
# 关于mysql出现Data too long for column的解决方案 打开my.ini,将其中sql-mode节中的STRICT_TRANS_TABLES这个属性去掉;
pipelines.py:
import pymysql
class CnblogsSpiderPipeline:
# 所有的保存都用一个连接,最后存完把连接关闭,爬虫一启动打开数据库连接,爬虫关闭,关闭数据库连接
def open_spider(self, spider):
print("我开了")
self.conn = pymysql.connect(
user='root',
password="123",
host='127.0.0.1',
database='cnblogs',
port=3306,
autocommit=True # 自动提交
)
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
# 每个文章都会一次次的触发该方法的执行,在这里写保存逻辑
print('pipline:', item['title'])
# self.cursor.execute('insert into article (title,`desc`,detail,author_name,author_img) values (%s,%s,%s,%s,%s)',
# args=[item['title'], item['desc'], item['detail'], item['author_name'],
# item['author_img'], ])
return item
def close_spider(self, spider):
print('我关了')
self.cursor.close()
self.conn.close()
class CnblogsSpiderFilePipeline:
def process_item(self, item, spider):
return item
6、爬虫中间件和下载中间件
# 爬虫和下载中间件要使用,需要在配置文件中:
SPIDER_MIDDLEWARES = {
'crawl_cnblogs.middlewares.CrawlCnblogsSpiderMiddleware': 5,
}
DOWNLOADER_MIDDLEWARES = {
'crawl_cnblogs.middlewares.CrawlCnblogsDownloaderMiddleware': 5,
}
7、加代理,加header,集成selenium
# 在下载中间件的process_reqeust方法中
# 1 加cookie
# request.cookies['name']='lqz'
# request.cookies= {}
# 2 修改header
# request.headers['Auth']='asdfasdfasdfasdf'
# request.headers['USER-AGENT']='ssss'
# 3 加代理
request.meta['proxy']='http://103.130.172.34:8080'
# 4 fake_useragent模块,可以随机生成user-aget
from fake_useragent import UserAgent
ua = UserAgent()
print(ua.ie) #随机打印ie浏览器任意版本
print(ua.firefox) #随机打印firefox浏览器任意版本
print(ua.chrome) #随机打印chrome浏览器任意版本
print(ua.random) #随机打印任意厂家的浏览器
scrapy架构与目录介绍、scrapy解析数据、配置相关、全站爬取cnblogs数据、存储数据、爬虫中间件、加代理、加header、集成selenium的更多相关文章
- Scrapy实战篇(八)之Scrapy对接selenium爬取京东商城商品数据
本篇目标:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据. 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据 ...
- scrapy爬取cnblogs文章列表
scrapy爬取cnblogs文章 目标任务 安装爬虫 创建爬虫 编写 items.py 编写 spiders/cnblogs.py 编写 pipelines.py 编写 settings.py 运行 ...
- 爬虫---scrapy全站爬取
全站爬取1 基于管道的持久化存储 数据解析(爬虫类) 将解析的数据封装到item类型的对象中(爬虫类) 将item提交给管道, yield item(爬虫类) 在管道类的process_item中接手 ...
- Python爬虫入门教程 42-100 爬取儿歌多多APP数据-手机APP爬虫部分
1. 儿歌多多APP简单分析 今天是手机APP数据爬取的第一篇案例博客,我找到了一个儿歌多多APP,没有加固,没有加壳,没有加密参数,对新手来说,比较友好,咱就拿它练练手,熟悉一下Fiddler和夜神 ...
- 利用python爬取58同城简历数据
利用python爬取58同城简历数据 利用python爬取58同城简历数据 最近接到一个工作,需要获取58同城上面的简历信息(http://gz.58.com/qzyewu/).最开始想到是用pyth ...
- 爬虫黑科技,我是怎么爬取indeed的职位数据的
最近在学习nodejs爬虫技术,学了request模块,所以想着写一个自己的爬虫项目,研究了半天,最后选定indeed作为目标网站,通过爬取indeed的职位数据,然后开发一个自己的职位搜索引擎,目前 ...
- 简单又强大的pandas爬虫 利用pandas库的read_html()方法爬取网页表格型数据
文章目录 一.简介 二.原理 三.爬取实战 实例1 实例2 一.简介 一般的爬虫套路无非是发送请求.获取响应.解析网页.提取数据.保存数据等步骤.构造请求主要用到requests库,定位提取数据用的比 ...
- Python网页解析库:用requests-html爬取网页
Python网页解析库:用requests-html爬取网页 1. 开始 Python 中可以进行网页解析的库有很多,常见的有 BeautifulSoup 和 lxml 等.在网上玩爬虫的文章通常都是 ...
- 使用Selenium爬取网站表格类数据
本文转载自一下网站:Python爬虫(5):Selenium 爬取东方财富网股票财务报表 https://www.makcyun.top/web_scraping_withpython5.html 需 ...
随机推荐
- JVM的基础知识
一.JVM的基础知识 1.JVM内存结构: 1.JVM堆内存结构: 2.JVM内存分配: 3.Java的堆机构和垃圾回收: 4.Jvm堆内存配置参数: 5.JVM新生代概念和配置: 6.JVM老生代概 ...
- 学习GlusterFS(四)
基于 GlusterFS 实现 Docker 集群的分布式存储 以 Docker 为代表的容器技术在云计算领域正扮演着越来越重要的角色,甚至一度被认为是虚拟化技术的替代品.企业级的容器应用常常需要将重 ...
- SpringCloud个人笔记-02-Feign初体验
项目结构 sb_cloud_product <?xml version="1.0" encoding="UTF-8"?> <project x ...
- dll反编译(修改引用文件、修改代码)再生成dll
问题描述 我们在日常开发中经常会遇到,想要对dll文件做修改的操作,但苦于没有源代码,只能想想其他办法 解决问题 办法就是通过几个工具来反编译.正向编译.修改属性 反编译.正编译 参考https:// ...
- Java/C++实现模板方法模式---数据库操作
对数据库的操作一般包括连接.打开.使用.关闭等步骤,在数据库操作模板类中我们定义了connDB().openDB().useDB().closeDB()四个方法分别对应这四个步骤.对于不同类型的数据库 ...
- Python raise...from... 是啥?
调试程序时看某些库的源代码,发现有如下代码读不懂,不理解后面这个from干什么用的. try: ... except KeyError: raise **Error('') from None try ...
- 免费的天气API
高德地图天气 天气查询-API文档 请求示例: { "status": "1", "count": "1", " ...
- 动态代理-JDK
代理模式:假设一个场景,你的公司是一位软件公司,你是一位软件工程师,显然客户带着需求不会去找你谈,而是去找商务谈,此时商务就代表公司. 商务的作用:商务可以谈判:也有可能在开发软件之前就谈失败,此时商 ...
- 讲解CPU之NUMA硬件体系以及机制(lscpu查看相关信息)
先看看从系统层面反映出来的numa cpu信息.采样机器为实体机.80核.128内存. [root@ht2 src]# lscpu Architecture: x86_64 #x86架构下的64位 C ...
- 一个程序的执行时间可以使用time+命令形式来获得
编写程序testtime.c #include <stdio.h> //这个头一定要加 #include<time.h> main() { time_t timep; time ...