tensorflow的断点续训
tensorflow的断点续训
2019-09-07
顾名思义,断点续训的意思是因为某些原因模型还没有训练完成就被中断,下一次训练可以在上一次训练的基础上继续训练而不用从头开始;这种方式对于你那些训练时间很长的模型来说非常友好。
如果要进行断点续训,那么得满足两个条件:
(1)本地保存了模型训练中的快照;(即断点数据保存)
(2)可以通过读取快照恢复模型训练的现场环境。(断点数据恢复)
这两个操作都用到了tensorflow中的train.Saver类。
1.tensorflow.trainn.Saver类
__init__(
var_list=None,
reshape=False,
sharded=False,
max_to_keep=5,
keep_checkpoint_every_n_hours=10000.0,
name=None,
restore_sequentially=False,
saver_def=None,
builder=None,
defer_build=False,
allow_empty=False,
write_version=tf.train.SaverDef.V2,
pad_step_number=False,
save_relative_paths=False,
filename=None
)
这里不对所有参数进行介绍,只介绍常用的参数
max_to_keep:允许保存的模型的个数,默认为5;当保存的个数超过5时,自动删除最旧的模型,以保证最多同时存在5个模型;如果设置为0或者None,则会对所有训练中的模型进行保存,但是这样除了多占硬盘外没什么意义。
其他的参数一般就使用默认值就可以了。
saver = tf.train.Saver(max_to_keep=10)
有机会再补充其他参数的用法。
2.断点数据的保存
使用saver对象的save方法即可保存模型:
save(
sess,
save_path,
global_step=None,
latest_filename=None,
meta_graph_suffix='meta',
write_meta_graph=True,
write_state=True,
strip_default_attrs=False,
save_debug_info=False
)
常用参数:
sess:需要保存的会话,一般就是我们程序中的sess;
save_path:保存模型的文件路径以及名称,例如“ckpt/my_model”,注意如果要保存在ckpt文件夹下,那么需要在ckpt后面加个斜杠/;
global_step:训练次数,saver会自动将这个值加入到保存的文件名字中。
saver.save(sess,"my_model",global_step=1)
saver.save(sess,"my_model",global_step=100)
saver.save(sess,"ckpt/my_model",global_step=1)
其中1,2,3行代码分别会:
1:在代码的路径下生成名为“my_model_1文件”;
2:在代码的路径下生成名为“my_model_100文件”;
3:在ckpt文件夹下生成名为“my_model_1文件”。
最常见的用法:
for epoch in range(n_iter):
'''
training process
'''
saver.save(sess,ckpt_dir+"model_name",global_step=epoch)
其中ckpt_dir是断点数据存放的路径。
3.断点数据的恢复
3.1 只加载参数,不加载图
需要先建立一个与之前相同的模型;然后再检查有没有断点数据,如果有,则进行恢复。
'''
模型图创建
'''
ckpt_dir = "ckpt/"
#创建Saver对象
saver = tf.train.Saver()
#如果有断点文件,读取最近的断点文件
ckpt = tf.train.latest_checkpoint(ckpt_dir) if ckpt != None:
saver.restore(sess,ckpt)
不需要提供模型的名字,tf.train.latest_checkpoint(ckpt_dir)会去ckpt_dir文件夹中自动寻找最新的模型文件。
这个方法要求模型图建立好之后才允许创建saver,然后进行变量恢复,否则会报错。
当我们基于checkpoint文件(ckpt)加载参数时,实际上我们使用Saver.restore取代了initializer的初始化。
3.2 图结构与参数都加载
不需要自己建立模型图了,全部靠加载:
import tensorflow as tf
#获取最新断点数据路径
ckpt = tf.train.latest_checkpoint("./ckpt/")
#加载图结构
saver = tf.train.import_meta_graph(ckpt+".meta") sess = tf.Session()
#加载参数
saver.restore(sess,ckpt)
#运行sess
sess.run(tf.get_default_graph().get_tensor_by_name("x:0"))

可以通过 tf.get_default_graph().get_tensor_by_name("x:0")获取模型节点,其中“x:0”是创建节点的时候节点的name。
4.模型文件解析
在程序训练过程中保存的模型文件如下图所示:
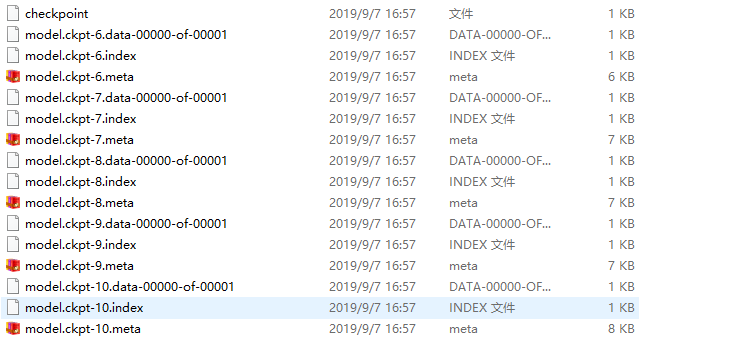
checkpoint文件会记录保存信息,通过它可以定位最新保存的模型;
.meta文件保存了当前图结构
.data文件保存了当前参数名和值
.index文件保存了辅助索引信息
至于文件名后面的数字表示的是模型训练的不同批次,我们一般只需要最新的那个;由于之前设置最多保存5个模型,所以批次号是从6开始的。
4.1 查看checkpoint
ckpt = tf.train.get_checkpoint_state("./ckpt/")
print(ckpt)
结果是文件的断点状态信息:
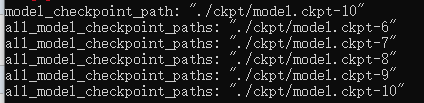
断点状态信息下有一个“model_checkpoint_path”属性,属性内容是最新的那个模型的路径,用str类型来表示;
ckpt.model_checkpoint_path

这个与tf.train.latest_checkpoint("./ckpt/")得出的结果是相同的,可以通过这个路径来加载模型参数。
4.2 通过data文件查看变量名和变量值
from tensorflow.python.tools.inspect_checkpoint import print_tensors_in_checkpoint_file
print_tensors_in_checkpoint_file("./ckpt/model.ckpt-10",None,True)
print_tensors_in_checkpoint_file中输入的第一个参数即上一节中获取到的模型路径;结果会以字典的形式展现出来。

4.3 通过meta文件加载图结构
saver = tf.train.import_meta_graph('./ckpt/model.ckpt-10.meta')
注意这里的参数是完整的路径加上meta文件的文件名,后面需要加上“.meta”。
返回的是一个saver对象,这个对象中包含了之前模型的图结构。
tensorflow的断点续训的更多相关文章
- Keras模型训练的断点续训、早停、效果可视化
训练:model.fit()函数 fit(x=None, y=None, batch_size=None, epochs=, verbose=, callbacks=None, validation_ ...
- curl断点续载
摘自http://blog.csdn.net/zmy12007/article/details/37157297 摘自http://www.linuxidc.com/Linux/2014-10/107 ...
- 关于视频断点续播和H5的本地存储
前段时间,需要在下实现一个视频的断点续播功能,呃,我不会呀,这就很尴尬了.然后呢,在下就想起了一个叫做localStorage的东西.这是个什么东西呢?在网上查阅了一些资料后,在下发现这是webSto ...
- scrapy爬虫之断点续爬和多个spider同时爬取
from scrapy.commands import ScrapyCommand from scrapy.utils.project import get_project_settings #断点续 ...
- 迁移学习——使用Tensorflow和VGG16预训模型进行预测
使用Tensorflow和VGG16预训模型进行预测 from:https://zhuanlan.zhihu.com/p/28997549 fast.ai的入门教程中使用了kaggle: dogs ...
- python3.6 单文件爬虫 断点续存 普通版 文件续存方式
# 导入必备的包 # 本文爬取的是顶点小说中的完美世界为列.文中的aa.text,bb.text为自己创建的text文件 import requests from bs4 import Beautif ...
- Electron 的断点续下载
最近用 Electron 做了个壁纸程序,需要断点续下载,在这里记录一下. HTTP断点下载相关的报文 Accept-Ranges 告诉客户端服务器是否支持断点续传,服务器返回 Content-Ran ...
- HTML 5 断点续上传
断点上传,java里面比较靠谱一点的,一般都会选用Flex.我承认,Flex只是摸了一下,不精通.HTML 5 有个Blob对象(File对象继承它),这个对象有个方法slice方法,可以对一个文件进 ...
- scrapy 断点续爬
第一步:安装berkeleydb数据库 第二部:pip install bsddb3 第三部:pip install scrapy-deltafetch 第四部: settings.py设置 SPID ...
- python下载mp4 同步和异步下载支持断点续下
Range 用于请求头中,指定第一个字节的位置和最后一个字节的位置,一般格式: Range:(unit=first byte pos)-[last byte pos] Range 头部的格式有以下几种 ...
随机推荐
- 为什么 A 能 ping 通 B,B 却不能 ping 通 A ?
有开发小哥咨询了一个问题,记录一下处理过程分享给有需要的朋友. 问题如下: A.B 两台开发服务器连接交换机,并且 A.B 两台服务器的 IP 地址设置为同一个网段,却发现 A 能 ping 通 B ...
- SignalR 的应用
一.应用场景: 在项目中有一个地方需要定时查询数据库是否有数据,如果有则显示在界面上. 二.可以使用ajax定时查询来做: var inter = window.setInterval(refresh ...
- es启动和停止命令
1.启动命令 使用elasticsearch用户来启动,进入bin目录(例:home/db_app/elasticsearch/elasticsearch-6.5.4/elasticsearch-cl ...
- base64 转图片
data:image+jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD//gA7Q1JFQVRPUjogZ2QtanBlZyB2MS4wICh1c2luZyBJSkcg% ...
- GSLB工作原理
参考文档: http://chongit.github.io/2015/04/15/GSLB%E6%A6%82%E8%A6%81%E5%92%8C%E5%AE%9E%E7%8E%B0%E5%8E%9F ...
- git push 时发生的error: failed to push some refs to
- 先再一个新建的一个文件夹里面git clone +你要克隆的远程仓库 - 然后把克隆下来的.git文件夹复制到你的本地仓库,然后再commit-git add, - git push 就可以提交成 ...
- js中常用的运算符
1. ?. 链接运算符 特性: 一旦遇到空置就会终止 例子: let name = obj?.name persion.getTip?.() // 没有getTip 方法则不会执行 2. ?? 空值合 ...
- kibana启动及导出PDF报错
kibana启动及导出PDF报错,可能是由于kibana需要的系统依赖没有安装 CentOS/RHEL系统需要安装以下依赖: ipa-gothic-fonts xorg-x11-fonts-100dp ...
- Rsync等传统文件同步方式已过时 如何寻找替代产品?
Rsync原本是在Linux系统下面的一个文件同步协议,随着技术的发展,它也有其它版本的,如Windows和AIX.HPUX下面都有相应的版本可以支持的.它有很多版本都是免费的,配置也不复杂,所以很多 ...
- SQL SERVER 多表联合修改
sql server中有时候会用到多表联合修改,下面是简单的多表修改的例子 UPDATE a SET a.a1 = b.b1 , a.a2 = b.b2 FROM A a, B b WHERE a.a ...