MyCat2 分表分库
1、添加数据库、存储数据源
我们在读写分离那边已经生成过,不需要在执行,如果没有执行过,执行下面注解,我们这边重新创建一个数据库db1
/*+ mycat:createDatasource{ "name":"rwSepw", "url":"jdbc:mysql://192.168.200.51:3306/db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root", "password":"123"} */;
/*+ mycat:createDatasource{ "name":"rwSepr", "url":"jdbc:mysql://192.168.200.53:3306/db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root", "password":"123"} */;
create database db1;
2、添加集群配置
把新添加的数据源配置成集群
#在 mycat 终端输入
/*!
mycat:createCluster{"name":"c0","masters":["rwSepw"],"replicas":["rwSepr"]}
*/;
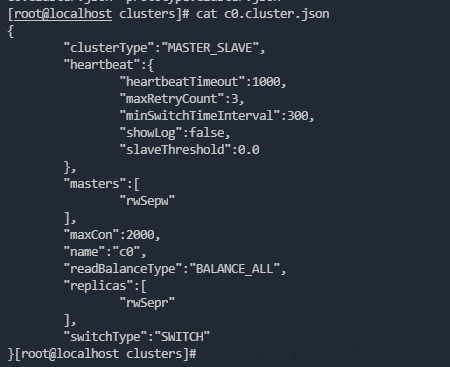
#可以查看集群配置信息
cd /usr/local/mycat/conf/clusters

注解生成如下结果
3、创建分片表(分库分表)
在 Mycat2数据客户端直接运行建表语句进行数据分片
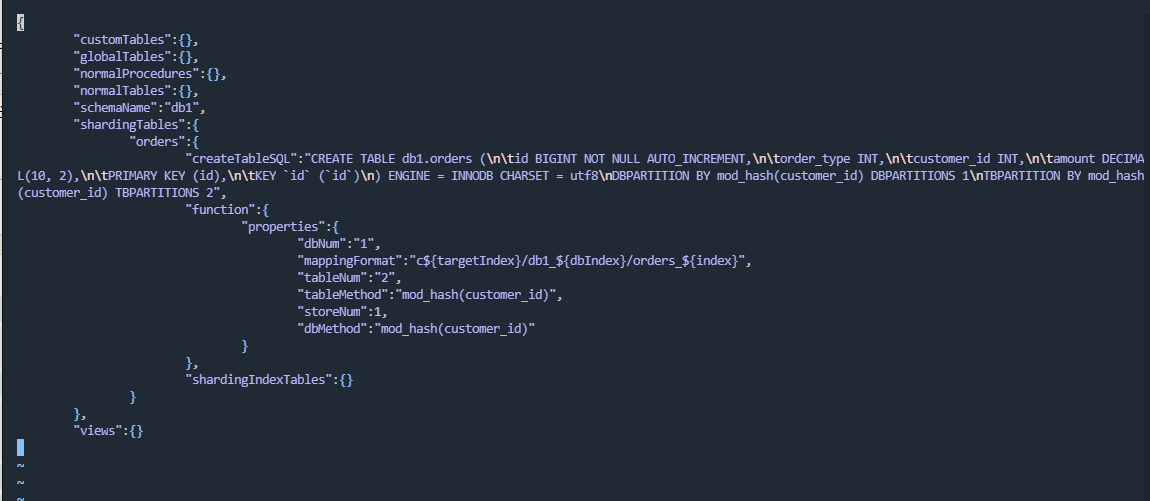
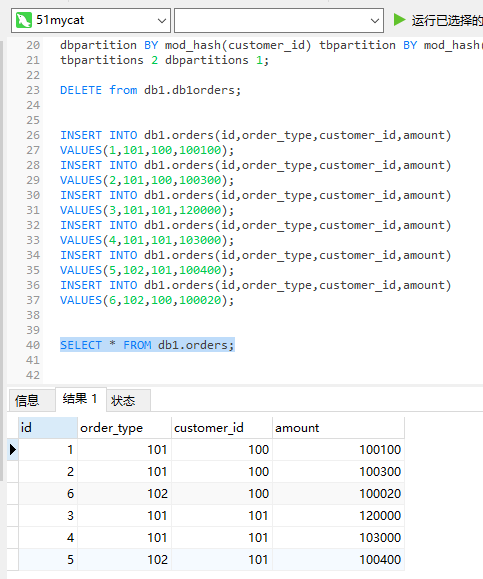
CREATE TABLE db1.orders(
id BIGINT NOT NULL AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id) tbpartitions 2 dbpartitions 1;
数据库分片规则,表分片规则,以及各分多少片 tbpartitions 表数量 dbpartitions 库数量
查看生成的配置信息:
vim /usr/local/mycat/conf/schemas/db1.schema.json
4、 查看数据库,插入数据
INSERT INTO db1.orders(id,order_type,customer_id,amount)
VALUES(1,101,100,100100);
INSERT INTO db1.orders(id,order_type,customer_id,amount)
VALUES(2,101,100,100300);
INSERT INTO db1.orders(id,order_type,customer_id,amount)
VALUES(3,101,101,120000);
INSERT INTO db1.orders(id,order_type,customer_id,amount)
VALUES(4,101,101,103000);
INSERT INTO db1.orders(id,order_type,customer_id,amount)
VALUES(5,102,101,100400);
INSERT INTO db1.orders(id,order_type,customer_id,amount)
VALUES(6,102,100,100020);
查看数据:
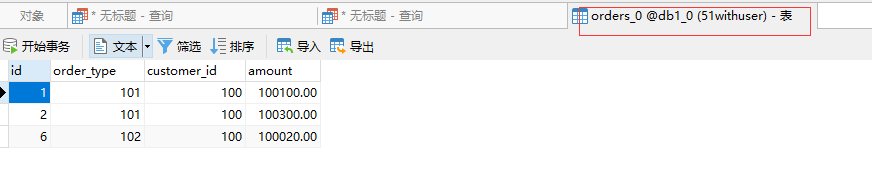
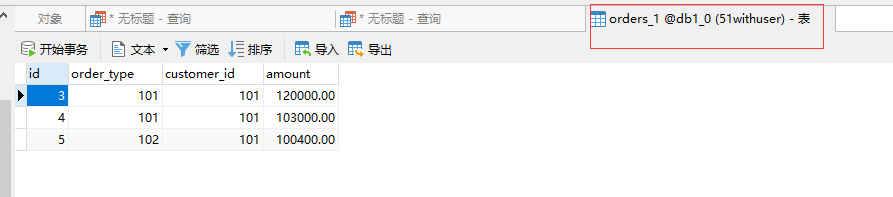
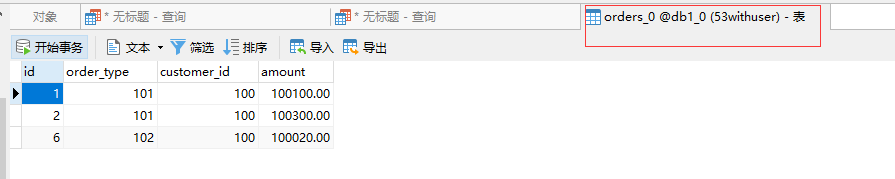
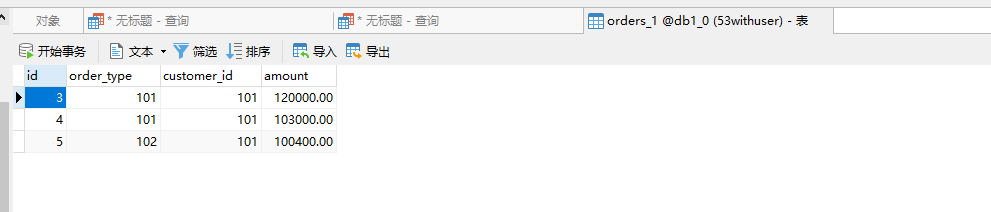
在 Mycat2数据客户端查询依然可以看到全部数据
5、创建 ER 表 ,在Mycat2数据客户端直接运行建表语句进行数据分片
CREATE TABLE db1.orders_detail(
`id` BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(order_id) tbpartition BY mod_hash(order_id)
tbpartitions 2 dbpartitions 1;
插入ER表数据
INSERT INTO db1.orders_detail(id,detail,order_id) VALUES(1,'detail1',1);
INSERT INTO db1.orders_detail(id,detail,order_id) VALUES(2,'detail1',2);
INSERT INTO db1.orders_detail(id,detail,order_id) VALUES(3,'detail1',3);
INSERT INTO db1.orders_detail(id,detail,order_id) VALUES(4,'detail1',4);
INSERT INTO db1.orders_detail(id,detail,order_id) VALUES(5,'detail1',5);
INSERT INTO db1.orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
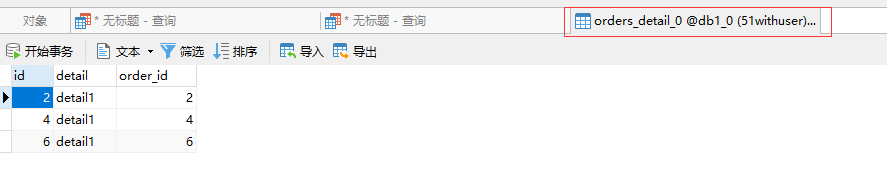

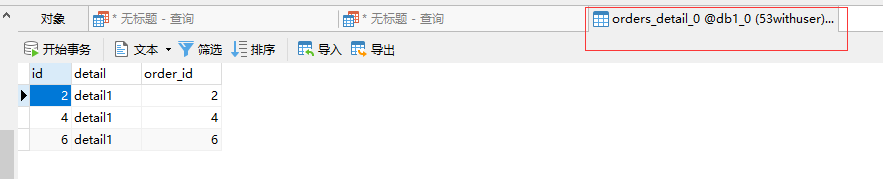
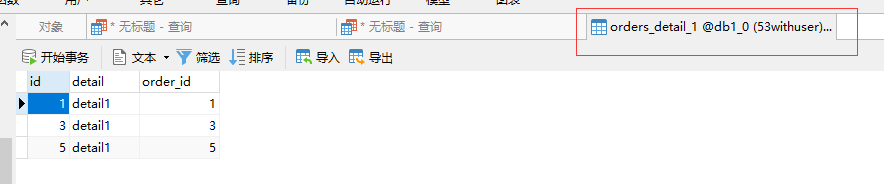
上述两表具有相同的分片算法,但是分片字段不相同Mycat2 在涉及这两个表的 join 分片字段等价关系的时候可以完成 join 的下推#Mycat2 无需指定 ER 表,是自动识别的,具体看分片算法的接口。
查看配置的表是否具有 ER 关系,使用
/*+ mycat:showErGroup{}*/
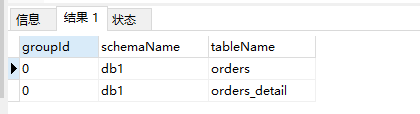
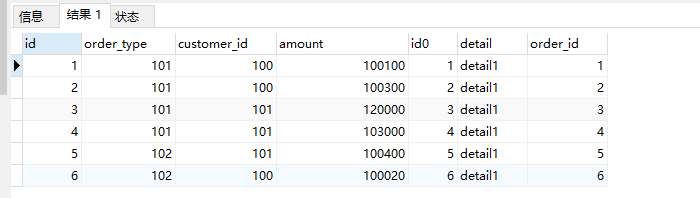
运行关联查询语句:
SELECT * FROM db1.orders o INNER JOIN db1.orders_detail od ON od.order_id=o.id;
MyCat2 分表分库的更多相关文章
- 学会数据库读写分离、分表分库——用Mycat,这一篇就够了!
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- .NETCore 下支持分表分库、读写分离的通用 Repository
首先声明这篇文章不是标题党,我说的这个类库是 FreeSql.Repository,它作为扩展库现实了通用仓储层功能,接口规范参考 abp vnext 定义,实现了基础的仓储层(CURD). 安装 d ...
- sharding sphere 分表分库 读写分离
sharding jdbc: sharding sphere 的 一部分,可以做到 分表分库,读写分离. 和 mycat 不同的 是 sharding jdbc 是 一个 jdbc 驱动 在 驱动这个 ...
- 总结下Mysql分表分库的策略及应用
上月前面试某公司,对于mysql分表的思路,当时简要的说了下hash算法分表,以及discuz分表的思路,但是对于新增数据自增id存放的设计思想回答的不是很好(笔试+面试整个过程算是OK过了,因与个人 ...
- 学会数据库读写分离、分表分库——用Mycat
系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理本身优化也是非常重要的.主从.热备.分表分库等都是系统发展迟早会遇到的技术问题问题.Mycat是一 ...
- (转)学会数据库读写分离、分表分库——用Mycat,这一篇就够了!
原文:https://www.cnblogs.com/joylee/p/7513038.html 系统开发中,数据库是非常重要的一个点.除了程序的本身的优化,如:SQL语句优化.代码优化,数据库的处理 ...
- Sharding-Jdbc实现分表分库
Sharding-Jdbc分表分库LogicTable数据分片的逻辑表,对于水平拆分的数据库(表),同一类表的总称.订单信息表拆分为2张表,分别是t_order_0.t_order_1,他们的逻辑表名 ...
- 使用MyCat分表分库原理分析
Mycat可以实现 读写分离 分表分库 主从复制是MySQL自带的哈~ 关于分片取模算法: 根据id进行取模 根据数据库集群的数量(或者说是表数量,mycat里面一个表对应一个库) 使用MyCat ...
- 由mysql分区想到的分表分库的方案
在分区分库分表前一定要了解分区分库分表的动机. 对实时性要求比较高的场景,使用数据库的分区分表分库. 对实时性要求不高的场景,可以考虑使用索引库(es/solr)或者大数据hadoop平台来解决(如数 ...
- Mycat分表分库
一.Mycat介绍 Mycat 是一个开源的分布式数据库系统,是一个实现了 MySQL 协议的的Server,前端用户可以把它看作是一个数据库代理,用 MySQL 客户端工具和命令行访问,而其后端可以 ...
随机推荐
- 认识一下 Mobx
我们是袋鼠云数栈 UED 团队,致力于打造优秀的一站式数据中台产品.我们始终保持工匠精神,探索前端道路,为社区积累并传播经验价值. 本文作者:霜序(掘金) 前言 在之前的文章中,我们讲述了 React ...
- 沁恒微(WCH)CH395/392配置使用,代码指南 网路接口芯片 CH395 CH392
CH395/CH392相关资料可以从官网下载具体连接可以看博客:WCH以太网相关芯片资料总结 里面是WCH官网相关信息的链接. 也可以去Gitee上下载:Gitee链接. STM32控制CH395的例 ...
- TiDB上百T数据拆分实践
背景 提高TiDB可用性,需要把多点已有上百T TiDB集群拆分出2套 挑战 1.现有需要拆分的12套TiDB集群的版本多(4.0.9.5.1.1.5.1.2都有),每个版本拆分方法存在不一样 2.其 ...
- kali开启ssh并开机自启
安装和启用SSH Kali默认是没有安装ssh和启用ssh的 我们需要先安装:apt install ssh 然后vim /etc/ssh/sshd_config (如果不需要启用Root登陆可以跳过 ...
- day07-Vue04
Vue04 12.Vue2 脚手架模块化开发 目前开发模式的问题: 开发效率低 不够规范 维护和升级,可读性比较差 12.1基本介绍 官网地址 什么是Vue Cli脚手架 12.2环境配置,搭建项目 ...
- 第一个shell
首先进入linux系统,打开命令行,输入命令vi test.sh创建一个shell测试脚本,键入i切换vi编辑器为输入模式,输入以下文本内容,键入:wq保存退出即可.下面第一行的#!是告诉系统其后路径 ...
- .NET周报【1月第3期 2023-01-20】
这应该是2023年农历新年前的最后一篇.NET周报,再次预祝大家新年快乐! 国内文章 看我是如何用C#编写一个小于8KB的贪吃蛇游戏的 https://www.cnblogs.com/InCerry/ ...
- 基于 VScode 搭建 Matlab 运行环境
插件 Matlab:代码高亮.语法检查.用户片段 matlab-formatter:代码格式化 Matlab Interactive Terminal:集成终端 配置 Matlab "fil ...
- Docker 基础 - 3
Web 服务器与应用 Nginx 我的Nginx Docker镜像 ## 设置继承自己创建的 sshd 镜像 FROM caseycui/ubuntu-sshd ## 维护者 LABEL mainta ...
- A+B Problem C++
前言继上次发表的A+B Problem C语言后,今天我们来学习一下A+B Problem C++ 正文什么是C++? C++既可以进行C语言的过程化程序设计,又可以进行以抽象数据类型为特点的基于对象 ...