【大数据面试】【框架】Shuffle优化、内存参数配置、Yarn工作机制、调度器使用
三、MapReduce
1、Shuffle及其优化☆
Shuffle是Map方法之后,Reduce方法之前,混洗的过程
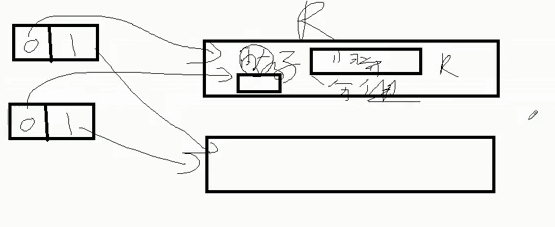
Map-->getPartition(标记数据的分区)-->对应的环形缓冲区(一侧存数据,一侧存索引,默认大小为100M,达到80%时进行反向溢写以提高空间利用率)
(溢写前需要对数据进行排序,默认快排,对key的索引排序,按照字典顺序排)(会产生大量的溢写文件)
【如何对溢写文件进行排序】:按照指定分区进行归并排序
优化:
环形缓冲区调整为200m,反向溢写的比例达到90+%,减少溢写的个数
溢写前进行一次combiner求和,默认一次归并10个,调大其数值(服务器性能可以,不会OOM内存溢出)
对数据进行压缩
【哪些地方能够对数据进行压缩?如何压缩】
Map输入输出端、Reduce的输出端
Map输入:数据量超过128M时,看是否有必要对数据切片,lzo、bzip2支持切片(数据量大时)
Map输出:快的是snappy、lzo
Reduce的输出端:看数据的最终流向(下一个MR看是否支持切片)(永久保存考虑压缩比最高)
【100个分区的数据,默认一次拉取5个,增大每批次拉取的个数,和reduce阶段的内存】
2、NodeManager的默认内存
企业服务器默认内存是128G
NodeManager的默认内存:8G【通常需要调整】
Map Task
Reduce Task
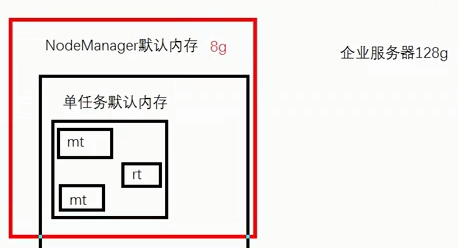
16G的任务,OOM
默认不配置就是8G内存,生产环境下需要配置到90-100G左右,给其他服务器资源留10G左右
3、配置单任务的默认内存
单任务的默认内存:8G
如果有1G/1T/10T的数据
如何调整其内存
估计,128M数据,对应1G内存
1G数据,对应8G内存左右
2G数据量,对应16G内存左右
4、其他默认
Map Task:1G
Reduce Task:1G
如果数据量是128M,不用调整
如果数据量大,且不支持切片,如500M,就需要根据比例调整,配置4G的内存
进入reduce的数据量比较大,适当增大内存
5、配置参数的等级优先级
defaul==》site.xml==》Idea的配置文件==》代码
6、Hadoop命令行如何提交文件
maven打包
hadoop jar wc.jar Class类名 输入路径 输出路径
7、内存设置

8、其他
Spark Shuffle和Hadoop Shuffle的区别
各讲一下其原理
四、Yarn
1、Yarn工作机制(笔试题)【客户端和集群】
客户端
集群:ResourceManager
集群模式(xml是参数的等级,切片影响MapTask的个数)
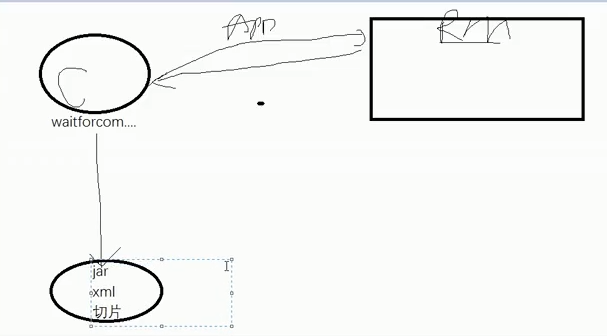
任务在队列中排队,nodemanager接收并执行任务
ApplicationMasterr负责执行,内部container容器拉取指定分区数据
Map按照分区存储在磁盘上-》reduce阶段,拉取完指定数据后释放
2、Yarn的调度器(与生产环境相关)
常见调度器:FIFO、容量、公平调度器
默认调度器是?Apache和CDH
FIFO调度器:支持单队列、先进先出(生产环境不会用)
容量调度器(Apache消耗资源少):支持多个队列,优先保证先进来的资源执行
公平调度器(CDH,占用资源多,需要内存大):保证所有任务公平享有资源,每个任务都分配2G,新进入任务,其他任务释放一定资源。保证每个任务公平享有资源
3、生产环境下如何选择
如果对并发度要求比较高,选择公平调度器,要求服务器性能必须好【大公司】
中小公司一般使用容量调度器,集群服务器资源不太充裕
4、容量调度器默认几个队列
默认只有一个default队列
5、生产环境下如何创建队列
两种方式
可以按照框架:hive/spark/flink放入指定的队列中【企业不常用】
也可以按照业务模块划分:登录队列、注册、购物车、下单、业务部门1、业务部门2
原因:怕新员工写递归死循环代码,导致所有资源全部耗尽
切记,不要使用rm -rf /*
也可以对任务队列划分优先级,集群资源不够用,只留重点资源的执行,对其他资源进行降级
【大数据面试】【框架】Shuffle优化、内存参数配置、Yarn工作机制、调度器使用的更多相关文章
- MySQL性能优化-内存参数配置
Mysql对于内存的使用,可以分为两类,一类是我们无法通过配置参数来配置的,如Mysql服务器运行.解析.查询以及内部管理所消耗的内存:另一类如缓冲池所用的内存等. Mysql内存参数的配置及重要,设 ...
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词. 本文分享自华为云社区<Yarn为何能坐实资源调度框架之王?>,作者: Java ...
- SQL命令语句进行大数据查询如何进行优化
SQL 大数据查询如何进行优化? 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索 2.应尽量避免在 where 子句中对字段进行 null 值 ...
- 大数据应用日志采集之Scribe 安装配置指南
大数据应用日志采集之Scribe 安装配置指南 大数据应用日志采集之Scribe 安装配置指南 1.概述 Scribe是Facebook开源的日志收集系统,在Facebook内部已经得到大量的应用.它 ...
- JAVA JVM常见内存参数配置简析
JVM常见内存参数配置简析 常见参数 -Xms .-Xmx.-XX:newSize.-XX:MaxnewSize.-Xmn(-XX:newSize.-XX:MaxnewSize) 简析 1.-Xm ...
- mongodb 3.2配置内存缓存大小为MB/MongoDB 3.x内存限制配置
mongodb 3.2配置内存缓存大小为MB/MongoDB 3.x内存限制配置 转载自勤奋的小青蛙 mongodb占用内存非常高,这是因为官方为了提升存储的效率,设计就这么设计的. 但是大部分的个人 ...
- 一条SQL在内存结构与后台进程工作机制
oracle服务器由数据库以及实例组成,数据库由数据文件,控制文件等物理文件组成,实例是由内存结构+后台进程组成,实例又可以看做连接数据库的方式,在我看来就好比一家公司,实例就是一个决策的办公室,大大 ...
随机推荐
- 延申三大问题中的第二个问题处理---收集查看k8s中pod的控制台日志
1.不使用logstash 2.步骤: 2.1 先获取一个文件的日志 2.2 再获取多个文件的日志 2.3 批量获取文件日志 pod日志文件路径 [root@worker hkd-eureka]# p ...
- 使用docker-compose部署WordPress项目
创建空文件夹 假设新建一个名为 wordpress 的文件夹,然后进入这个文件夹. 创建 docker-compose.yml 文件 docker-compose.yml 文件将开启一个 wordpr ...
- 01_Typora学习
Typora学习 使用Typora 编辑器 一. 标题 一个#后加空格表示一级标题(快捷键Ctrl+1) 两个#后加空格表示二级标题(快捷键Ctrl+2) 以此类推,目前最多到六级标题(快捷键Ctrl ...
- PHP全栈开发(八):CSS Ⅴ 超链接 style
CSS里面有专门针对超链接的选择器,也就是他们: a:link - 正常,未访问过的链接 a:visited - 用户已访问过的链接 a:hover - 当用户鼠标放在链接上时 a:active - ...
- hibernate validation 手动参数校验 不经过spring
/** * 校验工具类 * @author wdmcygah * */ public class ValidationUtils { private static Validator validato ...
- 微光互联 TX800-U 扫码器无法输出中文到光标的问题
问题背景 某检测场有一批扫码器,购于微光互联,型号 TX800-U,用于在不同办理窗口间扫描纸质材料上的二维码,简化录入过程.扫码器通过 USB 接入 PC 系统 (windows),自动安装驱动,接 ...
- 2022年最新最详细的tomcat安装教程和常见问的解决
文章目录 1.官网直接下载 1.1.jdk的版本和tomcat版本应该相对应或者兼容 1.2. 在官网找对应的tomcat版本进行下载 1.3 .根据电脑版本下载64-bit windows zip( ...
- Transformer 结构分析
self-attetion 1. 输入 \[X = EmbeddingLookup(X) + PositionalEncoding \\ X.shape == (batch\_size, seq\_l ...
- 野火 STM32MP157 开发板内核和设备树的编译烧写
一.环境 编译环境:Ubuntu 版本:18.4.6 交叉编译工具:arm-linux-gnueabihf-gcc 版本:7.4.1 开发板:STM32MP157 pro 烧写方式:STM32Cube ...
- Vue3的新特性
总概 1) 性能提升 打包大小减少 41% 初次渲染快 55%,更新渲染快 133% 内存减少 54% 使用 Proxy 代替 defineProperty 实现数据响应式 重写虚拟 DOM 的实现和 ...