深入理解Kafka核心设计及原理(五):消息存储
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16127749.html
目录:
5.1文件目录布局
5.2消息压缩
5.3日志索引
5.4日志文件及索引文件分段触发条件
5.5日志清理
5.6 磁盘存储--页缓存/零拷贝技术
5.1文件目录布局
如果分区规则设置得合理, 那么所有的消息可以均匀地分布到不同的分区中, 这样就可以实现水平扩展。 不考虑多副本的情况, 一个分区对应一个日志(Log)。 为了防止Log过大,Kafka又引入了日志分段(LogSegment)的概念,将Log切分为多个LogS egment, 相当于一个巨型文件被平均分配为多个相对较小的文件, 这样也便于消息的维护和清理。 事实上, Log 和LogSegnient也不是纯粹物理意义上的概念, Log在物理上只以文件夹的形式存储, 而每个LogSegment对应于磁盘上的 一个日志文件 和两个索引文件, 以及可能的其他文件(比如以 " . txnindex"为后缀的事务索引文件)。
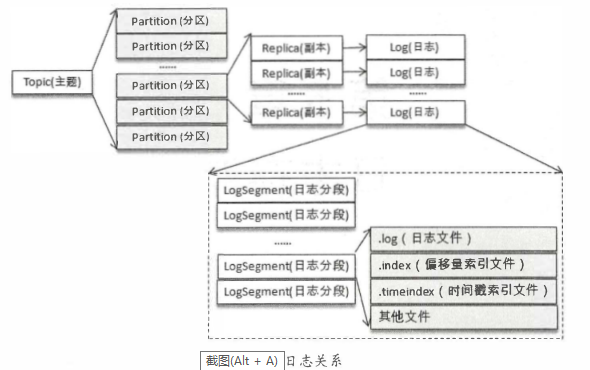
向Log中追加 消息时是顺序写入的, 只有最后 一 个LogSegment才能执行写入操作,在此之 前所有的LogSegment都 不能写入数据。
为了便于消息的检索, 每个LogSegment中的日志文件 (以 " . log"为文件后缀)都有对应的两个索引文件:偏移量 索引文件(以".index"为文件后缀)和时间戳索引文件(以". timeindex"为文件后缀) 。 每个ogSegment都有 一 个基准偏移量baseOffset, 用来表示当前LogSegment中第一 条消息的offset。 偏移量是一 个6 4位的长整型数, 日志文件和两个索引文件都是根据 基准偏移量(baseOffset)命名 的,名称固定为20 位数字, 没有达到的位数则用0填充。 比如第一 个LogSegment的基准偏移量为O, 对应的日志文件为00000000000000000000.log。
5.2消息压缩
常见的压缩算法是数据量越大压缩效果越好, 一 条消息通常不会太大,这就导致压缩效果并不是太好。 而Kafka实现的压缩方式是将多条消息 一起进行压缩,这样可以保证较好的压缩效果。 在 一般情况下,生产者发送 的压缩数据在broker中也是保待压缩状态进行存储的,消费者从服 务端获取的也是压缩的消息,消费者在处理消息之前才会解压消息,这样保待了端到端的压缩。
Kafka日志中使用哪种压缩方式是通过参数compression.type来配置的, 默认值为"producer", 表示保留生产者使用的压缩方式。这个参数还可以配置为"gz ip" "snappy" "lz4",分别对应GZ IP、 SNAPPY、 LZ 4这3种压缩算法。如果参数compression.type配置为"uncompressed" , 则表示不压缩。压缩率越小,压缩效果越好。
5.3日志索引
每个日志分段文件对应了两个索引文件,主要用来提高查找消息的效率。偏移量索引文件用来建立消息偏移量( offset )到物理地址之间的映射关系,方便快速定位消息所在的物理文件位置;时间戳索引文件则根据指定的时间戳( timestamp )来查找对应的偏移量小信息。
Kafka 中的索引文件以稀疏索引( sparse index )的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引 I页 。 每当写入一定量(由broker 端参数log.index.interval.bytes 指定,默认值为 4096 ,即 4KB )的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes的值,对应地可以增加或缩小索引项的密度。
Kafka 中的索引文件以稀疏索引( sparse index )的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引 I页 。 每当写入一定量(由broker 端参数log.index.interval.bytes 指定,默认值为 4096 ,即 4KB )的消息时,偏移量索引文件和时间戳索引文件分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes的值,对应地可以增加或缩小索引项的密度。
5.4日志文件及索引文件分段触发条件
日志分段文件达到一定的条件时需要进行切分,那么其对应的索引文件也需要进行切分。日志分段文件切分包含以下几个条件,满足其一 即可 。 (1) 当前日志分段文件的大小超过了broker 端参数 log.segment.bytes 配置的值。log.segment.bytes 参数的默认值为 1073741824 ,即 lGB 。 (2)当前日志分段中消息的最大时间戳与当前系统的时间戳的差值大于log.roll .ms或 log.roll.hours 参数配置的值。如果同时配置了 log.roll.ms 和 log.roll.hours 参数,那么 log.roll.ms 的优先级高 。 默认情况下,只配置了 log.ro ll.h ours 参数,其值为 168,即 7 天。 (3)偏移量索引文件或时间戳索引文件的大小达到 broker 端参数 log. index.size .max.bytes 配置的值。 log.index. size .max. bytes 的默认值为 10485760 ,即 l0MB 。 (4)追加的消息的偏移量与当前日志分段的偏移量之间的差值大于 Integer.MAX_VALUE,即要追加的消息的偏移量不能转变为相对偏移量( offset - baseOffset > Integer.MAX_VALUE )。
5.5日志清理
Kafka 将 消息存储在磁盘中,为了 控制磁盘占用空间的不断增加就需要对消息做一 定的清理操作。 Kafka 中 每 一个分区副本都对应 一个 Log, 而Log又可以分为多个日志分段,这样也便于日志的清理操作。 Kafka提供了两种日志清理策略。 (1)日志删除(LogRetention) : 按照一 定的保留策略直接删除不符合条件的日志分段。 (2)日志压缩 (LogCompaction) : 针对每个消息的key进行整合, 对千有相同 key的不同value 值, 只保留 最后 一个版本。 我们可以通过broker端参数log.cleanup.policy来设置 日志清理策略,此参数的默认值为"delete " , 即采用日志删除的清理策略。 如果要采用日志压缩的清理策略, 就需要将log.cleanup.po且cy设置为"compact", 并且还需要将log.cleaner. enable (默认值为true )设定为true。 通过将log.cleanup.policy参数 设置为"delete,compact" , 还可以同时支持日志删除和日志压缩两种策略。日志清理的粒度可以控制到主题级别, 比如log.cleanup.policy 对应的主题级别的参数为cleanup.policy
5.6 磁盘存储--页缓存/零拷贝技术
页缓存
页缓存是操作系统实现的一种主要的磁盘缓存, 以此用来减少对磁盘I/0 的操作。 具体来说, 就是把磁盘中的数据缓存到内存中, 把对磁盘的访间变为对内存的访问。 为了弥补性能上的差异, 现代操作系统越来越“ 激进地” 将内存作为磁盘缓存, 甚至会非常乐意将所有可用的内存用作磁盘缓存, 这样当内存回收时也几乎没有性能损失, 所有对于磁盘的读写也将经由统一的缓存。 当一个进程准备读取磁盘上的文件内容时, 操作系统会先查看待读取的数据所在的页(page)是否在页缓存(pagecache)中, 如果存在(命中)则直接返回数据, 从而避免了对物理磁盘的I/0操作;如果没有命中, 则操作系统会向磁盘发起读取请求并将读取的数据页存入页缓存, 之后再将数据返回给进程。 同样,如果 一个进程需要将数据写入磁盘, 那么操作系统也会检测数据对应的页是否在页缓存中, 如果不存在, 则会先在页缓存中添加相应的页, 最后将数据写入对应的页。 被修改过后的页也就变成了脏页, 操作系统会在合适的时间把脏页中的 数据写入磁盘, 以保持数据的一致性。
零拷贝
除了消息顺序追加、页缓存等技术,Kafka 还使用 零拷 贝( Zero-Copy )技术来进一步提升性能 。所谓的零拷贝是指将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手 。零拷贝大大提高了应用程序的性能,减少了内核和用户模式之间的上下文切换 。对 Linux操作系统而言,零拷贝技术依赖于底层的sendfile() 方法实现 。对应于Java 语言,Fi leChannal.transferTo()方法的底层实现就是 sendfile()方法 。
零拷贝技术通过 DMA (Direct Memory Access) 技术将文件内容复制到内核模式下的 Read Buffer 中。零拷贝是针对内核模式而言的, 数据在内核模式下实现了零拷贝。
深入理解Kafka核心设计及原理(五):消息存储的更多相关文章
- 深入理解Kafka核心设计及原理(三):消费者
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16114877.html 深入理解Kafka核心设计及原理(一):初识Kafka 深入理解Kafka核心设计及原 ...
- 深入理解Kafka核心设计及原理(四):主题管理
转载请注明出处:https://www.cnblogs.com/zjdxr-up/p/16124354.html 目录: 4.1创建主题 4.2 优先副本的选举 4.3 分区重分配 4.4 如何选择合 ...
- 深入理解Kafka核心设计及原理(二):生产者
转载请注明出处: 2.1Kafka生产者客户端架构 2.2 Kafka 进行消息生产发送代码示例及ProducerRecord对象 kafka进行消息生产发送代码示例: public class Ka ...
- 深入理解kafka设计原理
最近开研究kafka,下面分享一下kafka的设计原理.kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力. 1.持久性 k ...
- Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- 最全Kafka 设计与原理详解【2017.9全新】
一.Kafka简介 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何 ...
- [转]Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 1 2 1 2 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商 ...
- kafka之二:Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- kafka核心原理总结
新霸哥发现在新的技术发展时代,消息中间件也越来越受重视,很多的企业在招聘的过程中着重强调能够熟练使用消息中间件,所有做为一个软件开发爱好者,新霸哥在此提醒广大的软件开发朋友有时间多学习. 消息中间件利 ...
随机推荐
- ng-messages AngularJs 表单校验方式
最新研究了一下表单校验,直接上代码. <!DOCTYPE html><html ng-app='app'><head> <meta charset=" ...
- 在kali中安装两个版本的python
在kali中安装两个版本的python 在kali中已经预装了两个版本的python,但是没有装pip(>︿<). 这时使用python或者python3表示python3:使用pytho ...
- 使用MariaDB backup恢复主从
安装 yum install MariaDB-backup 备份命令 工具需要直接操作数据目录,需要在数据库服务器上执行 mariabackup --backup --target-dir=/data ...
- Java如何跳出当前的多重嵌套循环?
在Java中,要想跳出多重循环,可以在外面的循环语句前定义一个标号,然后在里层循环体的代码中使用带有标号的break 语句,即可跳出外层循环.例如, outer: for(int i=0;i<1 ...
- The Http request is not acceptable for the requested resource.
一.问题来源 最近给第三方做了一个我们系统的免密登陆,开发完成本地测试没有问题,但是第三方调用免密登陆接口并跳转之后报如下错误: The Http request is not acceptable ...
- 什么是 Netflix Feign?它的优点是什么?
Feign 是受到 Retrofit,JAXRS-2.0 和 WebSocket 启发的 java 客户端联编程序. Feign 的第一个目标是将约束分母的复杂性统一到 http apis,而不考虑其 ...
- 使用IDEA开发SpringBoot不加载application.yml配置文件的解决方案
1.如果启动项目不加载application.yml配置文件,那么请确认下是否应用了Resources为项目资源文件夹 2.如果项目起初是可以正常使用的,突然不知道改了什么,然后进行启动项目的时候不加 ...
- Java并发机制(2)--synchronized与Lock
本内容整理自:博客园-海 子-java并发编程系列-http://www.cnblogs.com/dolphin0520/category/602384.html 1.基础: 1.什么时候出现线程安全 ...
- vue集成ckeditor富文本框,怎么获取CKEditor实例?
CKEDITOR 版本5 ,vue集成形式 vue集成ckeditor富文本框,由于不是通过js创建的富文本对象,所以,无法取得实例对象,官方说明 官方在builds-->Getting and ...
- 007.iSCSI服务器CHAP双向认证配置
一 iSCSI和CHAP介绍 1.1 iSCSI 磁盘 iSCSI后端存储支持多种设备类型,主要有: 文件 单一分区(partition) 磁盘 数组 RAID LVM 本手册建议以裸磁盘vdb作为示 ...