坐实大数据资源调度框架之王,Yarn为何这么牛
摘要:Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为大数据的代名词。
本文分享自华为云社区《Yarn为何能坐实资源调度框架之王?》,作者: JavaEdge。
Hadoop主要组成:
- 分布式文件系统HDFS
- 分布式计算框架MapReduce
- 分布式集群资源调度框架Yarn
Yarn的出现伴随着Hadoop的发展,使Hadoop从一个单一的大数据计算引擎,成为一个集存储、计算、资源管理为一体的完整大数据平台,进而发展出自己的生态体系,成为大数据的代名词。
在MapReduce应用程序的启动过程中,最重要的就是把MapReduce程序分发到大数据集群的服务器,Hadoop 1中,这个过程主要是通过TaskTracker和JobTracker通信完成。
方案的缺点
服务器集群资源调度管理和MapReduce执行过程耦合在一起,如果想在当前集群中运行其他计算任务,比如Spark或者Storm,就无法统一使用集群中的资源。
Hadoop早期,大数据技术就只有Hadoop,这缺点不明显。但随大数据发展,各种新计算框架出现,我们不可能为每种计算框架部署一个服务器集群,而且就算能部署新集群,数据还是在原来集群的HDFS上。所以需要把MapReduce的资源管理和计算框架分开,这也是Hadoop2最主要变化:将Yarn从MapReduce中分离出来,成为一个独立的资源调度框架。
Yarn,Yet Another Resource Negotiator,另一种资源调度器。在Hadoop社区决定将资源管理从Hadoop1中分离出来,独立开发Yarn时,业界已有一些大数据资源管理产品,比如Mesos,所以Yarn开发者索性管自己的产品叫“另一种资源调度器”。比如Java的Ant就是“Another Neat Tool”缩写,另一种整理工具。
Yarn架构
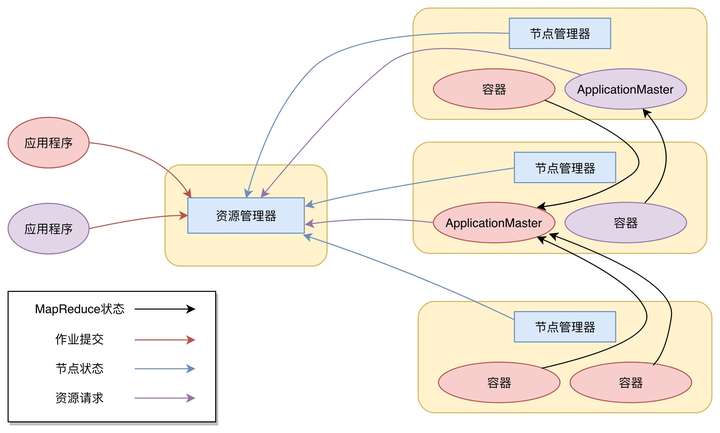
Yarn包括:
节点管理器(Node Manager)
NodeManager进程,负责具体服务器上的资源和任务管理,在集群的每一台计算服务器上都会启动,和HDFS的DataNode进程一起出现
资源管理器(Resource Manager)
ResourceManager进程,负责整个集群的资源调度管理,通常部署在独立的服务器
资源管理器包括两个主要组件:
调度器
就是个资源分配算法,根据Client应用程序提交的资源申请和当前服务器集群的资源状况进行资源分配。
Yarn内置的资源调度算法
包括Fair Scheduler、Capacity Scheduler等,也可以自行开发供Yarn调用。
Yarn进行资源分配的单位是容器(Container),每个容器包含了一定量的内存、CPU等计算资源,默认配置下,每个容器包含一个CPU核心。容器由NodeManager进程启动和管理,NodeManger进程会监控本节点上容器的运行状况并向ResourceManger进程汇报。
应用程序管理器
应用程序管理器负责应用程序的提交、监控应用程序运行状态等。应用程序启动后需要在集群中运行一个ApplicationMaster,ApplicationMaster也需要运行在容器里面。每个应用程序启动后都会先启动自己的ApplicationMaster,由ApplicationMaster根据应用程序的资源需求进一步向ResourceManager进程申请容器资源,得到容器以后就会分发自己的应用程序代码到容器上启动,进而开始分布式计算。
Yarn的工作流程
1、向Yarn提交应用程序,包括
- MapReduce ApplicationMaster
- 我们的MapReduce程序
- MapReduce Application启动命令
2、ResourceManager进程和NodeManager进程通信,根据集群资源,为用户程序分配第一个容器,并将MapReduce ApplicationMaster分发到这个容器,并在容器里启动MapReduce ApplicationMaster
3、MapReduce ApplicationMaster启动后立即向ResourceManager进程注册,并为自己的应用程序申请容器资源。
4、MapReduce ApplicationMaster申请到需要的容器后,立即和相应的NodeManager进程通信,将用户MapReduce程序分发到NodeManager进程所在服务器,并在容器中运行,运行的就是Map或者Reduce任务。
5、Map或者Reduce任务在运行期和MapReduce ApplicationMaster通信,汇报自己的运行状态,若运行结束,MapReduce ApplicationMaster向ResourceManager进程注销并释放所有的容器资源。
MapReduce若想在Yarn运行,需开发遵循Yarn规范的MapReduce ApplicationMaster,其他大数据计算框架也能开发遵循Yarn规范的ApplicationMaster,这样在一个Yarn集群中就能同时并发执行不同的大数据计算框架,实现资源的统一调度管理。
为何HDFS是系统,而MapReduce和Yarn是框架
框架遵循依赖倒转原则:高层模块不能依赖低层模块,它们应共同依赖一个抽象,这个抽象由高层模块定义,由低层模块实现。
高、低层模块的划分:调用链上,前面的是高层,后面的是低层。以Web应用为例,用户请求到Server后:
- 最先处理用户请求的是Web容器Tomcat,通过监听80端口,把HTTP二进制流封装成Request对象
- 然后Spring MVC框架,提取Request对象里的用户参数,根据请求的URL分发给相应的Model对象处理
- 最后应用程序代码处理用户请求
Tomcat相比Spring MVC就是高层模块,Spring MVC相比应用程序也是高层模块。虽然Tomcat会调用Spring MVC,因为Tomcat要把Request交给Spring MVC处理,但Tomcat并未依赖Spring MVC,那Tomcat如何做到不依赖Spring MVC,却能调用Spring MVC?
Tomcat和Spring MVC都依赖J2EE规范,Spring MVC实现了J2EE规范的HttpServlet抽象类,即DispatcherServlet,并配置在web.xml中。这样,Tomcat就能调用DispatcherServlet处理用户发来的请求。
同样Spring MVC也不需要依赖我们写的Java代码,而是通过依赖Spring MVC的配置文件或Annotation抽象,来调用我们的Java代码。所以,Tomcat或者Spring MVC都可以称作是框架,它们都遵循依赖倒转原则。
类似的,实现MapReduce编程接口、遵循MapReduce编程规范就能被MapReduce框架调用,在分布式集群中计算大规模数据;实现了Yarn的接口规范,比如Hadoop2的MapReduce,就能被Yarn调度管理,统一安排服务器资源。所以MapReduce和Yarn都是框架。
HDFS就不是框架,使用HDFS就是直接调用HDFS提供的API接口,HDFS作为底层模块被直接依赖。
总结
Yarn,大数据资源调度框架,调度的是大数据计算引擎本身,不像MapReduce或Spark编程,每个大数据应用开发者都需根据需求开发自己的MapReduce程序或者Spark程序。
大数据计算引擎所使用的Yarn模块,也早被这些计算引擎开发者做出来供使用。普通大数据开发者没有机会编写Yarn相关程序。
坐实大数据资源调度框架之王,Yarn为何这么牛的更多相关文章
- 大数据计算框架Hadoop, Spark和MPI
转自:https://www.cnblogs.com/reed/p/7730338.html 今天做题,其中一道是 请简要描述一下Hadoop, Spark, MPI三种计算框架的特点以及分别适用于什 ...
- Spark 介绍(基于内存计算的大数据并行计算框架)
Spark 介绍(基于内存计算的大数据并行计算框架) Hadoop与Spark 行业广泛使用Hadoop来分析他们的数据集.原因是Hadoop框架基于一个简单的编程模型(MapReduce),它支持 ...
- FusionInsight大数据开发---MapReduce与YARN应用开发
MapReduce MapReduce的基本定义及过程 搭建开发环境 代码实例及运行程序 MapReduce开发接口介绍 1. MapReduce的基本定义及过程 MapReduce是面向大数据并行处 ...
- 学习大数据基础框架hadoop需要什么基础
什么是大数据?进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB(1 ...
- 大数据之路week07--day04 (YARN,Hadoop的优化,combline,join思想,)
hadoop 的计算特点:将计算任务向数据靠拢,而不是将数据向计算靠拢. 特点:数据本地化,减少网络io. 首先需要知道,hadoop数据本地化是指的map任务,reduce任务并不具备数据本地化特征 ...
- 大数据系列4:Yarn以及MapReduce 2
系列文章: 大数据系列:一文初识Hdfs 大数据系列2:Hdfs的读写操作 大数据谢列3:Hdfs的HA实现 通过前文,我们对Hdfs的已经有了一定的了解,本文将继续之前的内容,介绍Yarn与Yarn ...
- bat坐拥大数据。数据挖掘/大数据给他们带来什么。
阿里巴巴CTO即阿里云负责人王坚博士说过一句话:云计算和大数据,你们都理解错了. 实际上,对于大数据究竟是什么业界并无共识.大数据并不是什么新鲜事物.信息革命带来的除了信息的更高效地生产.流通和消 ...
- 大数据BI框架知识点备注
将这段时间的一些基于大数据方案的BI知识点暂时做些规整,可能还存在较多问题,后续逐步完善修改. 数据模型: 1.星型模型和雪花模型,同样是将业务表拆分成事实表和纬度表:例如一个员工数据表,可以拆分为员 ...
- hadoop大数据基础框架技术详解
一.什么是大数据 进入本世纪以来,尤其是2010年之后,随着互联网特别是移动互联网的发展,数据的增长呈爆炸趋势,已经很难估计全世界的电子设备中存储的数据到底有多少,描述数据系统的数据量的计量单位从MB ...
随机推荐
- 统计&分析 EXCEL:count、counta、countblank、countif和countifs函数分享
一.count 计算区域中包含数字的单元格的个数以及参数列表中的数字的个数. 利用函数COUNT可以计算单元格区域或数字数组中数字字段的输入项个数. 示例: 1.我要是写成=COUNT(B1,D1), ...
- Java基础(补充)
为什么 Java 中只有值传递? 开始之前,我们先来搞懂下面这两个概念: 形参&实参 值传递&引用传递 形参&实参 方法的定义可能会用到 参数(有参的方法),参数在程序语言中分 ...
- HyBird App(混合应用)核心原理JSBridge
目录 app分类 HyBird App(混合应用) JSBridge介绍 优势及应用场景 JsBridge的核心 1.Web端调用Native端代码 1.1 拦截URL Schema 1.2 注入ap ...
- 半吊子菜鸟学Web开发5 -- PHP开发环境配置
本文参考自:http://blog.csdn.net/angon823/article/details/54415855 Ubuntu16.04 默认 apt-get install apache2 ...
- MVC与MVVM?
model-数据层 view-视图层 controller-控制层 MVC的目的是实现M和V的分离,单向通信,必须通过C来承上启下 MVVM中通过VM(vue中的实例化对象)的发布者-订阅者模式实现双 ...
- v-for key值?
不写key值会报warning, 和react的array渲染类似. 根据diff算法, 修改数组后, 写key值会复用, 不写会重新生成, 造成性能浪费或某些不必要的错误
- Grep 命令有什么用?如何忽略大小写?如何查找不含该串的行?
是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来. grep [stringSTRING] filename grep [^string] filename
- springboot 定时任务 session报错问题
一.自定义类 LocalVariable package com.lh.mes.base.thread; import java.util.Optional; public class LocalVa ...
- SynchronizedMap 和 ConcurrentHashMap 有什么区 别?
SynchronizedMap 一次锁住整张表来保证线程安全,所以每次只能有一个线程来 访为 map. ConcurrentHashMap 使用分段锁来保证在多线程下的性能. ConcurrentHa ...
- 面试问题之C++语言:说一下static关键字的作用
1.全局静态变量 在全局变量加上关键字static,全局变量就定义成一个全局静态变量,存放于静态存储区,在整个程序运行期间一直存在:未经初始化的全局静态变量会被自动初始化为0:全局静态变量在声明他的文 ...