C++11实现的数据库连接池
它什么是?
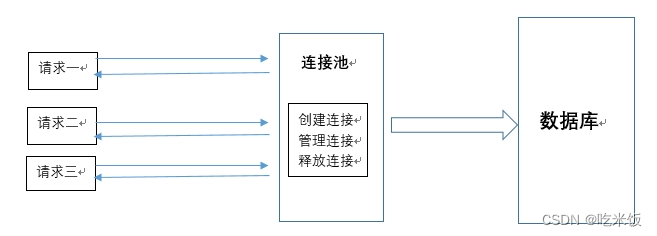
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个;类似的还有线程池。
为什么要用?
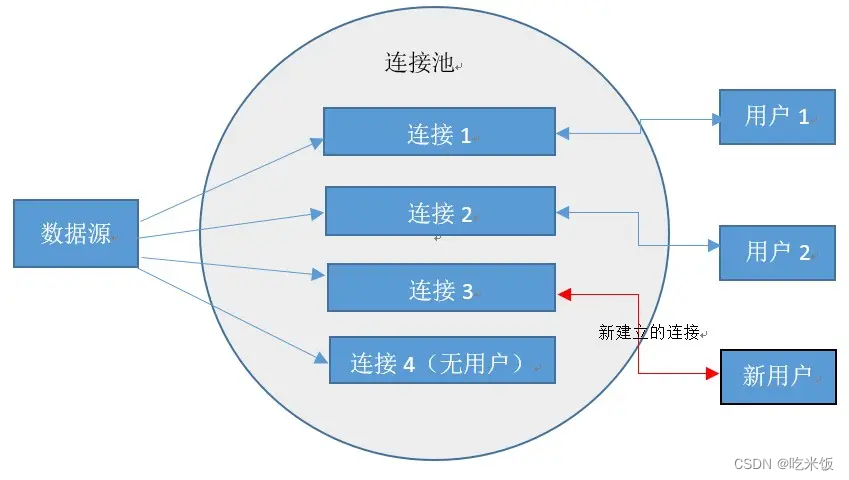
一个数据库连接对象均对应一个物理数据库连接,每次操作都打开一个物理连接,使用完都关闭连接,这样造成系统的性能低下。各种池化技术的使用原因都是类似的,也就是单独操作比较浪费系统资源,利用池提前准备一些资源,在需要时可以重复使用这些预先准备的资源,从而减少系统开销,实现资源重复利用。
有什么区别?
下面以访问MySQL为例,执行一个SQL命令,如果不使用连接池,需要经过哪些流程:
- 建立通信连接的 TCP 三次握手
- MySQL认证的三次握手
- 真正的SQL执行
- MySQL的关闭
- 断开通信连接的 TCP 四次挥手
如果使用了连接池第一次访问的时候,需要建立连接。 但是之后的访问,均会复用之前创建的连接,直接执行SQL语句。
Github
Connection.h
//
// Created by Cmf on 2022/8/24.
//
#ifndef CLUSTERCHATSERVER_CONNECTION_H
#define CLUSTERCHATSERVER_CONNECTION_H
#include <mysql/mysql.h>
#include <chrono>
#include <string>
#include "Log.hpp"
class Connection {
public:
Connection();
~Connection();
bool Connect(const std::string &ip, const uint16_t port, const std::string &user, const std::string &pwd,
const std::string &db);
bool Update(const std::string &sql);
MYSQL_RES *Query(const std::string &sql);
void RefreshAliveTime();
long long GetAliveTime() const;
private:
MYSQL *_conn;
std::chrono::time_point<std::chrono::steady_clock> _aliveTime;
};
#endif //CLUSTERCHATSERVER_CONNECTION_H
Connection.cpp
//
// Created by Cmf on 2022/8/24.
//
#include "Connection.h"
Connection::Connection() {
_conn = mysql_init(nullptr);
mysql_set_character_set(_conn, "utf8");//设置编码格式维utf8
}
Connection::~Connection() {
if (_conn != nullptr) {
mysql_close(_conn);
}
}
bool Connection::Connect(const std::string &ip, const uint16_t port, const std::string &user, const std::string &pwd,
const std::string &db) {
_conn = mysql_real_connect(_conn, ip.c_str(), user.c_str(), pwd.c_str(), db.c_str(), port, nullptr, 0);
if (_conn == nullptr) {
LOG_ERROR("MySQL Connect Error")
return false;
}
return true;
}
bool Connection::Update(const std::string &sql) {
if (mysql_query(_conn, sql.c_str()) != 0) {
LOG_INFO("SQL %s 更新失败:%d", sql.c_str(), mysql_error(_conn));
return false;
}
return true;
}
MYSQL_RES *Connection::Query(const std::string &sql) {
if (mysql_query(_conn, sql.c_str()) != 0) {
LOG_INFO("SQL %s 查询失败:%d", sql.c_str(), mysql_error(_conn));
return nullptr;
}
return mysql_use_result(_conn);
}
void Connection::RefreshAliveTime() {
_aliveTime = std::chrono::steady_clock::now();
}
long long Connection::GetAliveTime() const {
return std::chrono::duration_cast<std::chrono::microseconds>(std::chrono::steady_clock::now() - _aliveTime).count();
}
ConnectionPool.h
//
// Created by Cmf on 2022/8/24.
//
#ifndef CLUSTERCHATSERVER_COMMOMCONNECTIONPOOL_H
#define CLUSTERCHATSERVER_COMMOMCONNECTIONPOOL_H
#include "noncopyable.hpp"
#include <memory>
#include <queue>
#include <mutex>
#include <atomic>
#include <thread>
#include <condition_variable>
#include "Connection.h"
class ConnectionPool : private noncopyable {
public:
static ConnectionPool& GetConnectionPool(); //获取连接池对象实例
//给外部提供接口,从连接池中获取一个可用的空闲连接
std::shared_ptr<Connection> GetConnection();//智能指针自动管理连接的释放
~ConnectionPool();
private:
ConnectionPool();
bool LoadConfigFile();
//运行在独立的线程中,专门负责生产新连接
void ProduceConnectionTask();
//扫描超过maxIdleTime时间的空闲连接,进行对于的连接回收
void ScannerConnectionTask();
void AddConnection();
private:
std::string _ip;
uint16_t _port;
std::string _user;
std::string _pwd;
std::string _db;
size_t _minSize; //初始链接数量
size_t _maxSize; //最大连接数量
size_t _maxIdleTime;//最大空闲时间
size_t _connectionTimeout;//超时时间
std::queue<Connection *> _connectionQueue;//存储连接队列
std::mutex _mtx; //维护连接队列的线程安全互斥锁
std::atomic_int _connectionCount;//记录连接所创建的connection连接的总数量
std::condition_variable _cv;//设置条件变量,用于连接生产线程和连接消费线程的通信
};
#endif //CLUSTERCHATSERVER_COMMOMCONNECTIONPOOL_H
ConnectionPool.cpp
//
// Created by Cmf on 2022/8/24.
//
#include <fstream>
#include "ConnectionPool.h"
#include "json.hpp"
using json = nlohmann::json;
ConnectionPool &ConnectionPool::GetConnectionPool() {
static ConnectionPool pool;
return pool;
}
std::shared_ptr<Connection> ConnectionPool::GetConnection() {
std::unique_lock<std::mutex> lock(_mtx);
while (_connectionQueue.empty()) { //连接为空,就阻塞等待_connectionTimeout时间,如果时间过了,还没唤醒
if (std::cv_status::timeout == _cv.wait_for(lock, std::chrono::microseconds(_connectionTimeout))) {
if (_connectionQueue.empty()) { //就可能还是为空
continue;
}
}
}
//对于使用完成的连接,不能直接销毁该连接,而是需要将该连接归还给连接池的队列,供之后的其他消费者使用,于是我们使用智能指针,自定义其析构函数,完成放回的操作:
std::shared_ptr<Connection> res(_connectionQueue.front(), [&](Connection *conn) {
std::unique_lock<std::mutex> locker(_mtx);
conn->RefreshAliveTime();
_connectionQueue.push(conn);
});
_connectionQueue.pop();
_cv.notify_all();
return res;
}
ConnectionPool::ConnectionPool() {
if (!LoadConfigFile()) {
LOG_ERROR("JSON Config Error");
return;
}
//创建初始数量的连接
for (int i = 0; i < _minSize; ++i) {
AddConnection();
}
//启动一个新的线程,作为连接的生产者 linux thread => pthread_create
std::thread produce(std::bind(&ConnectionPool::ProduceConnectionTask, this));
produce.detach();//守护线程,主线程结束了,这个线程就结束了
//启动一个新的定时线程,扫描超过maxIdleTime时间的空闲连接,进行对于的连接回收
std::thread scanner(std::bind(&ConnectionPool::ScannerConnectionTask, this));
scanner.detach();
}
ConnectionPool::~ConnectionPool() {
while (!_connectionQueue.empty()) {
Connection *ptr = _connectionQueue.front();
_connectionQueue.pop();
delete ptr;
}
}
bool ConnectionPool::LoadConfigFile() {
std::ifstream ifs("../../config/dbconf.json");
json js;
ifs >> js;
std::cout << js << std::endl;
if (!js.is_object()) {
LOG_ERROR("JSON is NOT Object");
return false;
}
if (!js["ip"].is_string() ||
!js["port"].is_number() ||
!js["user"].is_string() ||
!js["pwd"].is_string() ||
!js["db"].is_string() ||
!js["minSize"].is_number() ||
!js["maxSize"].is_number() ||
!js["maxIdleTime"].is_number() ||
!js["timeout"].is_number()) {
LOG_ERROR("JSON The data type does not match");
return false;
}
_ip = js["ip"].get<std::string>();
_port = js["port"].get<uint16_t>();
_user = js["user"].get<std::string>();
_pwd = js["pwd"].get<std::string>();
_db = js["db"].get<std::string>();
_minSize = js["minSize"].get<size_t>();
_maxSize = js["maxSize"].get<size_t>();
_maxIdleTime = js["maxIdleTime"].get<size_t>();
_connectionTimeout = js["timeout"].get<size_t>();
return true;
}
void ConnectionPool::ProduceConnectionTask() {
while (true) {
std::unique_lock<std::mutex> lock(_mtx);
while (_connectionQueue.size() >= _minSize) {
_cv.wait(lock);
}
if (_connectionCount < _maxSize) {
AddConnection();
}
_cv.notify_all();
}
}
void ConnectionPool::ScannerConnectionTask() {
while (true) {
std::this_thread::sleep_for(std::chrono::seconds(_maxIdleTime));
std::unique_lock<std::mutex> lock(_mtx);
while (_connectionCount > _minSize) {
Connection *ptr = _connectionQueue.front();//队头的时间没超过,那后面的时间就都没超过
if (ptr->GetAliveTime() >= _maxIdleTime * 1000) {
_connectionQueue.pop();
--_connectionCount;
delete ptr;
} else {
break;
}
}
}
}
void ConnectionPool::AddConnection() {
Connection *conn = new Connection();
conn->Connect(_ip, _port, _user, _pwd, _db);
conn->RefreshAliveTime();
_connectionQueue.push(conn);
++_connectionCount;
}
C++11实现的数据库连接池的更多相关文章
- 基于C++11的数据库连接池实现
0.注意 该篇文章为了让大家尽快看到效果,代码放置比较靠前,看代码前务必看下第4部分的基础知识. 1.数据库连接池 1.1 是什么? 数据库连接池负责分配.管理和释放数据库连接,属于池化机制的一种,类 ...
- JDBC(11)—数据库连接池
在实际开发过程中,特别是在web应用系统中,如果程序直接访问数据库中的数据,每一次数据访问请求丢必须经历建立数据库连接.打开数据库.存取数据和关闭数据库连接.而连接并打开数据库是一件既消费资源又费时的 ...
- java web学习总结(十六) -------------------数据库连接池
一.应用程序直接获取数据库连接的缺点 用户每次请求都需要向数据库获得链接,而数据库创建连接通常需要消耗相对较大的资源,创建时间也较长.假设网站一天10万访问量,数据库服务器就需要创建10万次连接,极大 ...
- JDBC 数据库连接池 小结
原文:http://www.cnblogs.com/lihuiyy/archive/2012/02/14/2351768.html 当对数据库的访问不是很频繁时,可以在每次访问数据库时建立一个连接,用 ...
- 数据库连接池之Proxool使用
如果想要搭建一个高效的网站,链接池是必须用到的一部分.而连接池的选择是多种多样的.就现在的软件开发界而言,最为多用的是DBCP, c3p0, 和 proxool.而hibernate推荐使用的是c3p ...
- c3p0数据库连接池死锁问题
项目进行压力测试的时候,运行大概1小时候,后台抛出以下异常: Nov 9, 2012 1:41:59 AM com.mchange.v2.async.ThreadPoolAsynchronousRun ...
- paip.提升性能----数据库连接池以及线程池以及对象池
paip.提升性能----数据库连接池以及线程池以及对象池 目录:数据库连接池c3po,线程池ExecutorService:Jakartacommons-pool对象池 作者Attilax 艾龙, ...
- java数据库连接池性能对比
这个测试的目的是验证当前常用数据库连接池的性能. testcase Connection conn = dataSource.getConnection(); PreparedStatement st ...
- MVC设计模式((javaWEB)在数据库连接池下,实现对数据库中的数据增删改查操作)
设计功能的实现: ----没有业务层,直接由Servlet调用DAO,所以也没有事务操作,所以从DAO中直接获取connection对象 ----采用MVC设计模式 ----采用到的技术 .MVC设计 ...
随机推荐
- 在 Traefik Proxy 2.5 中使用/开发私有插件(Traefik 官方博客)
Traefik Proxy 在设计上是一个模块化路由器,允许您将中间件放入您的路由中,并在请求到达预期的后端服务目的地之前对其进行修改. Traefik 内置了许多这样的中间件,还允许您以插件的形式加 ...
- 开发工具-SVG占位图片
更新日志 2022年6月10日 初始化链接. https://toolb.cn/imageholder
- 14.Nginx搭建及优化
Nginx搭建及优化 目录 Nginx搭建及优化 Nginx服务基础 概述 Nginx和Apache的优缺点比较 编译安装Nginx服务 添加Nginx系统服务 Nginx服务配置文件 nginx服务 ...
- 重学ES系列之字符串方面的处理
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- SAP APO-需求计划
需求计划可以对市场中的产品进行预测. 需求计划过程的输出就是需求计划,它考虑了影响需求的所有因素. 需求计划流程定义了需求计划周期中的活动. 由于需求计划过程以循环的形式进行,因此可以重复某些活动. ...
- static关键字续、继承、重写、多态
static关键字 1.对于实例变量,每个java对象都拥有自己的一份,存储在堆内存当中,在构造方法执行的时候初始化. 2.所有对象都拥有同一个属性时,并且值相同,建议声明为static变量. 3.静 ...
- Pytorch Dataloader加速
在进行多卡训练的时候,经常会出现GPU利用率上不来的情况,无法发挥硬件的最大实力. 造成这种现象最有可能的原因是,CPU生成数据的能力,已经跟不上GPU处理数据的能力. 方法一 常见的方法为修改Dat ...
- 基于 Github Actions 自动部署 Hexo 博客
前言 前不久使用了 Hexo 搭建独立博客,我是部署在我的腾讯云轻量应用服务器上的,每次都需要 hexo deploy 然后打包.上传.解压和刷新 CDN,非常麻烦.我的服务器配置也不高 2C2G 无 ...
- 相约 DTCC 2021 | Tapdata 受邀分享:如何打造面向 TP 业务的数据平台架构
2021第十二届中国数据库技术大会(DTCC)将于2021年10月18-20日,在北京国际会议中心举行,Tapdata 创始人唐建法受邀分享:如何打造面向 TP 业务的数据平台架构. 演讲时间 ...
- do-while循环和三种循环的区别
循环语句3--do...while do...while循环格式 初始化表达式① do{ 循环体③ 步进表达式④ }while(布尔表达式②); 执行流程 执行顺序:①③④>②③④>②③④ ...