MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search——百度下一代搜索广告系统
简介
传统的广告最终的呈现需要经过召回与排序两个阶段,百度的搜索架构则采用三层漏斗状,如图1所示。最上面的一层用于筛选出和用户查询最相关的一部分广告,将整个候选广告集从亿级降到千级;下面两层是排序阶段,需要结合具体的业务,对召回的广告进行最终的排序、展示。三层结构相较于两层结构更多的是从计算资源与业务目标上的考量。
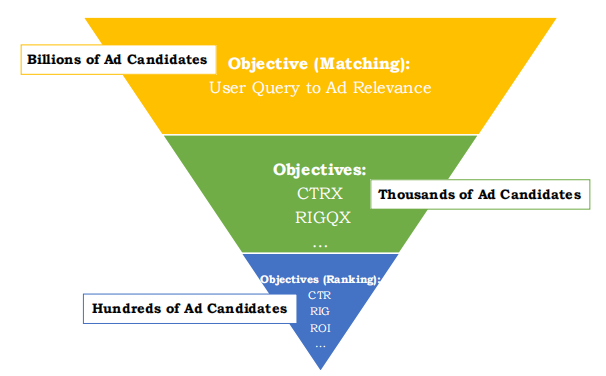
图1 传统两阶段排序模式
然而这种“召回——排序”模式存在的主要问题是:召回阶段的优化目标和排序阶段的优化目标是不一样的,这就可能导致召回的样本不具备太多商业价值。针对这一问题,百度团队提出在召回阶段兼顾排序阶段的目标(如CTR、ROI),从而将两阶段模式融合成一个阶段。
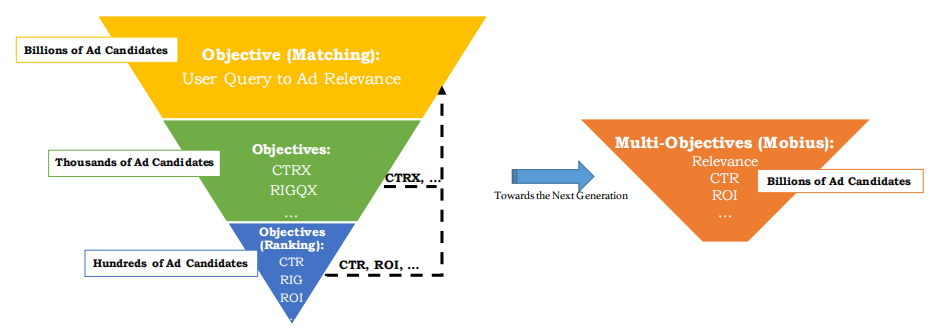
图2 百度Mobius一阶段召回模式(在召回层考虑排序层的目标)
总体而言,该论文的创新之处有两点:
- 在召回层保证相关性的同时引入了CPM等业务指标作为召回的依据;
- 将以往的CTR预估模型融合到召回层中,提出一种全新的多目标商业召回系统架构。
问题建模
传统两阶段广告排序模型的召回层注重召回结果的相关性,用公式表达为:
\]
召回阶段的优化目标和排序阶段的优化目标不一样,这可能导致召回的样本不具备太多商业价值。因此百度的解决方案是将两阶段模式融合成一个阶段,在召回阶段同时兼顾排序阶段的优化目标,问题建模为:
\]
\]
如何在数以亿计的样本中兼顾召回的相关性和排序阶段的CTR、CPM等目标?一个直观的方案是在召回阶段引入排序阶段的模型,但是如果不加改动地直接使用排序模型会导致一些问题。我们知道,排序阶段的样本是召回阶段筛选出的与用户查询较为相关的一部分样本,然后经过排序后一部分样本会获得较高的CTR值,这是没问题的。然而直接在海量数据上进行排序,会导致与用户查询不相关的样本仍有很高的CTR,但这部分样本用户并不关心。

图3 直接将排序模型迁移到召回层会使本来不相关的query-ad pair有较高的CTR
为了解决这一问题,需要在排序之前让排序模型能够区分相关性低的样本。
模型架构
召回阶段需要计算样本与给定查询的相关性,在进行排序之前,先用召回模型计算query和id的相关性,把相关性较低的<query,ad>对筛选出来,该模块称为“Relevance Judger”。模型主要分为两个部分,数据增强模块和CTR建模模块,整体架构如下图所示。
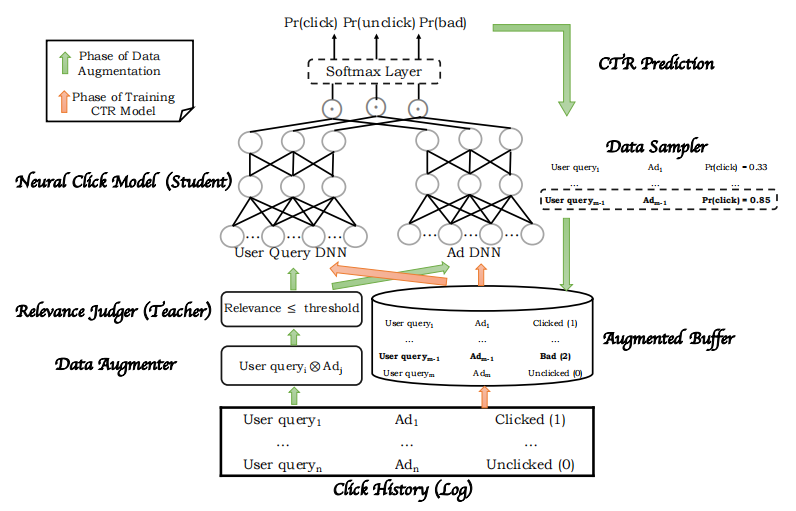
图4 百度Mobius模型架构
输入是一个batch的<query,ad>对,在进行后续处理之前,需要拆分成两个集合——query集和ad集;
Data Augmenter模块对上一步拆分的query集和ad集做笛卡尔积,假设query集有m个元素,ad集有n个元素,则该模块会输出m*n个元素,包含很多虚拟的<query, ad>对;
接着通过Relevance Judger把相关性低于指定阈值的<query, ad>对筛选出来,然后送入到点击率预估网络中计算其CTR;
Data Sampler模块根据CTR值采样出一部分CTR值较高的样本,称为bad case。将该部分数据和一开始输入的<query, ad>对混合,最后送入到CTR预估网络中。与一般CTR预估模型的二分类(点击/不点击)输出不同的是,该架构的输出还包括bad case情况,是一个三分类问题。
总的来说,该架构训练网络,使其能够将与用户查询相关性低但是CTR高的ad标记为bad case。利用相关性召回模型 ( teacher ) 来“教”会CTR模型 ( student ) 哪些样本是badcase,所以这里首先利用相关性模型对构造的query-ad pair进行相关性打分,并从中筛选出来相关性较低的样本交给CTR模型进行预测,根据预测的PCTR值从中选出低相关性高PCTR的样本作为badcase ( 这类样本在原始CTR样本中是不存在的,是为了让CTR模型学会哪些是badcase而构建出来的,原始的CTR模型是不需要关注相关性的,只需要关注CTR )。
线上召回
离线训练好模型以后,可以通过图4中的User Query DNN和Ad DNN获得用户查询的Embedding和广告的Embedding,给定一个query embedding,需要找到若干和该查询相关的广告,然而在全体样本集里面一个一个查找可能的ad embedding在上线阶段是不可行的。因此百度采用ANN(近似最近邻)技术加速筛选过程。
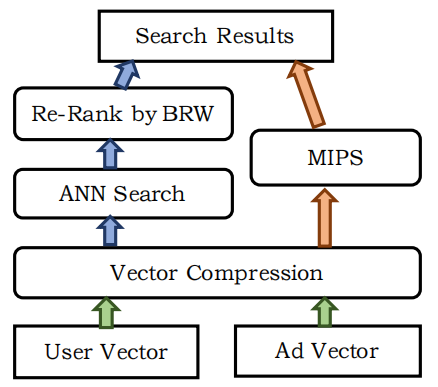
为了最终排序结果的精确性,通常在排序之前要考虑业务相关权重信息,而ANN方案是先召回在考虑业务权重进行精排,MIPS则是将业务指标改写进了相似度计算的公式中,也就是在检索的过程中就考虑商业指标。
MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search——百度下一代搜索广告系统的更多相关文章
- 广告召回 Query-Ad Matching
小结: 1.最为基础的召回链路就是要保证召回层的相关性,但是相关性高的广告并不一定具有很高的商业价值,所以开始尝试将一些商业化业务指标作为召回的依据 百度凤巢新一代广告召回系统--"莫比乌斯 ...
- 【Android 应用开发】GitHub 优秀的 Android 开源项目
原文地址为http://www.trinea.cn/android/android-open-source-projects-view/,作者Trinea 主要介绍那些不错个性化的View,包括Lis ...
- ElasticSearch 简单的 搜索 聚合 分析
一. 搜索1.DSL搜索 全部数据没有任何条件 GET /shop/goods/_search { "query": { "match_all": {} } } ...
- 【转】淘宝技术牛p博客整理
转自:http://blog.csdn.NET/zdp072/article/details/19574793 淘宝技术委员会是由淘宝技术部高级技术人员组成的一个组织,共分为Java分会.C/C++分 ...
- elasticsearch从入门到出门-03-多种搜索
1.query string search 2.query DSL 3.query filter 4.full-text search 5.phrase search 6.highlight sear ...
- Authorization in Cloud Applications using AD Groups
If you're a developer of a SaaS application that allows business users to create and share content – ...
- 计算广告(5)----query意图识别
目录: 一.简介: 1.用户意图识别概念 2.用户意图识别难点 3.用户意图识别分类 4.意图识别方法: (1)基于规则 (2)基于穷举 (3)基于分类模型 二.意图识别具体做法: 1.数据集 2.数 ...
- AD域渗透总结
域渗透总结 学习并做了一段时间域网络渗透,给我直观的感受就是思路问题和耐心,这个不像技术研究,需要对一个点进行研究,而是遇到问题后要从多个方面思考,寻找"捷径"思路,只要思路正确, ...
- 搜索引擎Query Rewrite
中心词抽取项目总结 B2B国际站Query重写.ppt 达观数据搜索引擎的Query自动纠错技术和架构详解 Natural Language Processing Simrank++ Query re ...
- Query DSL for elasticsearch Query
Query DSL Query DSL (资料来自: http://www.elasticsearch.cn/guide/reference/query-dsl/) http://elasticsea ...
随机推荐
- 光纤加速卡第410篇:基于XCVU9P+ C6678的40G光纤的加速卡 光纤的加速卡 无线通信
光纤加速卡第410篇:基于XCVU9P+ C6678的40G光纤的加速卡 光纤的加速卡 无线通信 基于XCVU9P+ C6678的40G光纤的加速卡 一.板卡概述 二.技术指标 • 板卡为自定义 ...
- [资料] 设计原理图资料保存:FMC210-1路1Gsps AD、1路2.5Gsps DA的FMC子卡解决方案
FMC210-1路1Gsps AD.1路2.5Gsps DA的FMC子卡 一.板卡概述 FMC-1AD2DA是北京太速科技自主研发的一款1路1G AD采集.1路2.5G DA回放的FMC子卡.板卡采用 ...
- C#新语法
C#新语法 NET6新特性以及C#新语法 1.顶级语句(C#9.0) (1):直接在C#文件中直接编写入口方法的代码,不用类,不用Main.经典写法仍然支持,反编译可以查看到,编译器依旧为我们生成了一 ...
- react框架-this指向问题
主要使用红框中的内容 import React, { Component } from 'react' export default class app extends Component { ...
- vscode提交修改的时候报错:无法推送 refs 到远端。您可以试着运行“拉取”功能,整合您的更改
vscode提交修改的时候报错:无法推送 refs 到远端.您可以试着运行"拉取"功能,整合您的更改, git操作命令行 git pull origin yourbranch - ...
- 莫凡Python之keras 2
莫凡Python 2 kearsregressionpython Classifier 分类 使用 mnist 数据集,这是0-9的图片数据,我们使用神经网络去识别这些图片.显示图片上的数据 本质上是 ...
- 认识jmeter(一)
1.官网下载: https://jmeter.apache.org/download_jmeter.cgi 下载后解压: 2.安装 免安装,解压后,bin目录下双击jmeter.bat,会直接打开 会 ...
- IDEA配置新学
文件太大导致IDEA不把该文件当成Java类看待 解决方式: 打开本地IDEA的bin目录,找到idea.properties文件,进入进行设置: idea.max.intellisense.file ...
- vue接口
前端的接口与后端进行对接,根据后台的接口字段与前端的字段对应 这是前端的定义方法,下面是一个方法定义的默认值下标 接下来就是提交的方法里面进行对接,再将ruleForm重新定义,然后进入接口进行存储 ...
- react-signature-canvas 签名功能
基于移动端需要扫码签名的功能,这里记录一下. 1.使用 react-signature-canvas 插件,npm i react-signature-canvas --save 2.此功能签名后生成 ...