ray-分布式计算框架-集群与异步Job管理
0. ray 简介
ray是开源分布式计算框架,为并行处理提供计算层,用于扩展AI与Python应用程序,是ML工作负载统一工具包
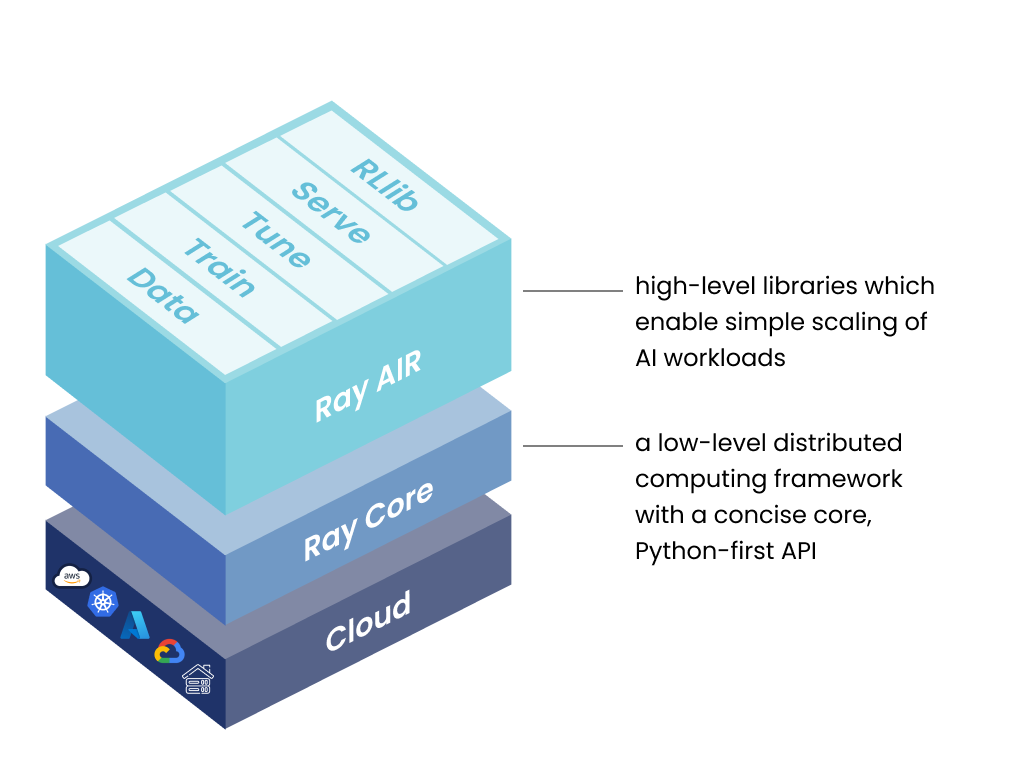
- Ray AI Runtime
ML应用程序库集
- Ray Core
通用分布式计算库
- Task -- Ray允许任意Python函数在单独的Python worker上运行,这些异步Python函数称为任务
- Actor -- 从函数扩展到类,是一个有状态的工作者,当一个Actor被创建,一个新的worker被创建,并且actor的方法被安排到那个特定的worker上,并且可以访问和修改那个worker的状态
- Object -- Task与Actor在对象上创建与计算,被称为远程对象,被存储在ray的分布式共享内存对象存储上,通过对象引用来引用远程对象。集群中每个节点都有一个对象存储,远程对象存储在何处(一个或多个节点上)与远程对象引用的持有者无关
- Placement Groups -- 允许用户跨多个节点原子性的保留资源组,以供后续Task与Actor使用
- Environment Dependencies -- 当Ray在远程机器上执行Task或Actor时,它们的依赖环境项(Python包、本地文件、环境变量)必须可供代码运行。解决环境依赖的方式有两种,一种是在集群启动前准备好对集群的依赖,另一种是在ray的运行时环境动态安装
- Ray cluster
一组连接到公共 Ray 头节点的工作节点,通过 kubeRay operator管理运行在k8s上的ray集群
- 关联链接
- Ray Doc: https://docs.ray.io/en/latest/ray-overview/index.html
- Ray Github: https://ray-project.github.io/kuberay/deploy/helm-cluster/
- Python raycluster 管理API: https://github.com/ray-project/kuberay/tree/master/clients/python-client
- Ray Job Python SDK Doc: https://docs.ray.io/en/latest/cluster/running-applications/job-submission/jobs-package-ref.html#ray-job-submission-sdk-ref
1. ray 集群管理
ray版本:2.3.0
- Kind 创建测试k8s集群
1主3从集群
# 配置文件 -- 一主两从(默认单主),文件名:k8s-3nodes.yaml
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane
- role: worker
- role: worker
创建k8s集群
kind create cluster --config k8s-3nodes.yaml
- KubeRay 部署ray集群
# helm方式安装
# 添加Charts仓库
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
# 安装default名称空间
# 安装 kubeRay operator
# 下载离线的chart包: helm pull kuberay/kuberay-operator --version 0.5.0
# 本地安装: helm install kuberay-operator
helm install kuberay-operator kuberay/kuberay-operator --version 0.5.0
# 创建ray示例集群,若通过sdk管理则跳过
# 下载离线的ray集群自定义资源:helm pull kuberay/ray-cluster --version 0.5.0
helm install raycluster kuberay/ray-cluster --version 0.5.0
# 获取ray集群对应的CR
kubectl get raycluster
# 查询pod的状态
kubectl get pods
# 转发svc 8265端口到本地8265端口
kubectl port-forward --address 0.0.0.0 svc/raycluster-kuberay-head-svc 8265:8265
# 登录ray head节点,并执行一个job
kubectl exec -it ${RAYCLUSTER_HEAD_POD} -- bash
python -c "import ray; ray.init(); print(ray.cluster_resources())" # (in Ray head Pod)
# 删除ray集群
helm uninstall raycluster
# 删除kubeRay
helm uninstall kuberay-operator
# 查询helm管理的资源
helm ls --all-namespaces
- Ray 集群管理
前置要求:
- 安装 KubeRay
- 安装 k8s sdk: pip install kubernetes
- 将python_client拷贝到PYTHONPATH路径下或者直接安装python_client, 该库路径为:https://github.com/ray-project/kuberay/tree/master/clients/python-client/python_client
from python_client import kuberay_cluster_api
from python_client.utils import kuberay_cluster_utils, kuberay_cluster_builder
def main():
# ray集群管理的api 获取集群列表、创建集群、更新集群、删除集群
kuberay_api = kuberay_cluster_api.RayClusterApi()
# CR 构建器,构建ray集群对应的字典格式的CR
cr_builder = kuberay_cluster_builder.ClusterBuilder()
# CR资源对象操作工具,更新cr资源
cluster_utils = kuberay_cluster_utils.ClusterUtils()
# 构建集群的CR,是一个字典对象,可以修改、删除、添加额外的属性
# 可以指定包含特定环境依赖的人ray镜像
cluster = (
cr_builder.build_meta(name="new-cluster1", labels={"demo-cluster": "yes"}) # 输入ray群名称、名称空间、资源标签、ray版本信息
.build_head(cpu_requests="0", memory_requests="0") # ray集群head信息: ray镜像名称、对应service类型、cpu memory的requests与limits、ray head启动参数
.build_worker(group_name="workers", cpu_requests="0", memory_requests="0") # ray集群worker信息: worker组名称、 ray镜像名称、ray启动命令、cpu memory的requests与limits、默认副本个数、最大与最小副本个数
.get_cluster()
)
# 检查CR是否构建成功
if not cr_builder.succeeded:
print("error building the cluster, aborting...")
return
# 创建ray集群
kuberay_api.create_ray_cluster(body=cluster)
# 更新ray集群CR中的worker副本集合
cluster_to_patch, succeeded = cluster_utils.update_worker_group_replicas(
cluster, group_name="workers", max_replicas=4, min_replicas=1, replicas=2
)
if succeeded:
# 更新ray集群
kuberay_api.patch_ray_cluster(
name=cluster_to_patch["metadata"]["name"], ray_patch=cluster_to_patch
)
# 在原来的集群的CR中的工作组添加新的工作组
cluster_to_patch, succeeded = cluster_utils.duplicate_worker_group(
cluster, group_name="workers", new_group_name="duplicate-workers"
)
if succeeded:
kuberay_api.patch_ray_cluster(
name=cluster_to_patch["metadata"]["name"], ray_patch=cluster_to_patch
)
# 列出所有创建的集群
kube_ray_list = kuberay_api.list_ray_clusters(k8s_namespace="default", label_selector='demo-cluster=yes')
if "items" in kube_ray_list:
for cluster in kube_ray_list["items"]:
print(cluster["metadata"]["name"], cluster["metadata"]["namespace"])
# 删除集群
if "items" in kube_ray_list:
for cluster in kube_ray_list["items"]:
print("deleting raycluster = {}".format(cluster["metadata"]["name"]))
# 通过指定名称删除ray集群
kuberay_api.delete_ray_cluster(
name=cluster["metadata"]["name"],
k8s_namespace=cluster["metadata"]["namespace"],
)
if __name__ == "__main__":
main()
2. ray Job 管理
前置: pip install -U "ray[default]"
- 创建一个job任务
# 文件名称: test_job.py
# python 标准库
import json
import ray
import sys
# 已经在ray节点安装的库
import redis
# 通过job提交时传递的模块依赖 runtime_env 配置 py_modules,通过 py_nodules传递过来就可以直接在job中导入
from test_module import test_1
import stk12
# 创建一个连接redeis对象,通过redis作为中转向job传递输入并获取job的输出
redis_cli = redis.Redis(host='192.168.6.205', port=6379, decode_responses=True)
# 通过redis获取传入过来的参数
input_params_value = None
if len(sys.argv) > 1:
input_params_key = sys.argv[1]
input_params_value = json.loads(redis_cli.get(input_params_key))
# 执行远程任务
@ray.remote
def hello_world(value):
return [v + 100 for v in value]
ray.init()
# 输出传递过来的参数
print("input_params_value:", input_params_value, type(input_params_key))
# 执行远程函数
result = ray.get(hello_world.remote(input_params_value))
# 获取输出key
output_key = input_params_key.split(":")[0] + ":output"
# 将输出结果放入redis
redis_cli.set(output_key, json.dumps(result))
# 测试传递过来的Python依赖库是否能正常导入
print(test_1.test_1())
print(stk12.__dir__())
- 创建测试自定义模块
# 模块路径: test_module/test_1.py
def test_1():
return "test_1"
- 创建一个job提交对象
import json
from ray.job_submission import JobSubmissionClient, JobStatus
import time
import uuid
import redis
# 上传un到ray集群供job使用的模块
import test_module
from agi import stk12
# 创建一个连接redeis对象
redis_cli = redis.Redis(host='192.168.6.205', port=6379, decode_responses=True)
# 创建一个client,指定远程ray集群的head地址
client = JobSubmissionClient("http://127.0.0.1:8265")
# 创建任务的ID
id = uuid.uuid4().hex
input_params_key = f"{id}:input"
input_params_value = [1, 2, 3, 4, 5]
# 将输入参数存入redis,供远程函数job使用
redis_cli.set(input_params_key, json.dumps(input_params_value))
# 提交一个ray job 是一个独立的ray应用程序
job_id = client.submit_job(
# 执行该job的入口脚本
entrypoint=f"python test_job.py {input_params_key}",
# 将本地文件上传到ray集群
runtime_env={
"working_dir": "./",
"py_modules": [test_module, stk12],
"env_vars": {"testenv": "test-1"}
},
# 自定义任务ID
submission_id=f"{id}"
)
# 输出job ID
print("job_id:", job_id)
def wait_until_status(job_id, status_to_wait_for, timeout_seconds=5):
"""轮询获取Job的状态,当完成时获取任务的的日志输出"""
start = time.time()
while time.time() - start <= timeout_seconds:
# 获取任务的状态
status = client.get_job_status(job_id)
print(f"status: {status}")
# 检查任务的状态
if status in status_to_wait_for:
break
time.sleep(1)
wait_until_status(job_id, {JobStatus.SUCCEEDED, JobStatus.STOPPED, JobStatus.FAILED})
# 输出job日志
logs = client.get_job_logs(job_id)
print(logs)
# 输出从job中获取的任务
output_key = job_id + ":output"
output_value = redis_cli.get(output_key)
print("output:", output_value)
- job 管理
from ray.job_submission import JobSubmissionClient, JobDetails, JobInfo, JobType, JobStatus
# 创建一个job提交客户端,如果管理多个ray集群的Job则切换或者创建多个连接ray head节点的客户端
job_cli = JobSubmissionClient("http://127.0.0.1:8265")
# Job信息,对应Job中submission_id属性
job_id = "b9ad6ff9ada445a29fb54307f1394594"
job_info = job_cli.get_job_info(job_id)
# 获取提交的所有job
jobs = job_cli.list_jobs()
for job in jobs:
# 获取job的状态
job_status = job_cli.get_job_status(job.submission_id)
print(f"job_id: {job.submission_id}, job_status: {job_status}")
# 输出job的json格式详情
print("job:", job.json())
# 停止Job
job_cli.stop_job(job_id)
# 删除 job
# job_cli.delete_job(job_id)
# 提交 Job
# job_cli.submit_job()
# 获取版本信息
print("version:", job_cli.get_version())
3. 产品场景
- 将周期、耗时任务异步化
镜像文件打包下载、文件同步、运维脚本、数据导出与同步、镜像同步、服务启停、TATC卫星项目中算法任务的执行、批量同类型任务的计算(如卫星项目中卫星轨迹的计算)、备份任务
- k8s中每个租户可以创建与删除自己的ray集群实例,在线IDE中将计算型任务交给ray来执行,不消耗IED所在环境的计算资源
ray-分布式计算框架-集群与异步Job管理的更多相关文章
- erlang集群IP及port管理
erlang集群是依靠epmd维护的,epmd是erlang集群节点间port映射的守护进程.负责维护集群内的节点连接.提供节点名称到IP地址及port的解析服务. epmd 自己定义port号 ep ...
- redis内存分配管理与集群环境下Session管理
##################内存管理############### 1.Redis的内存管理 .与memcache不同,没有实现自己的内存池 .在2..4以前,默认使用标准的内存分配函数(li ...
- redis 与java的连接 和集群环境下Session管理
redis 的安装与设置开机自启(https://www.cnblogs.com/zhulina-917/p/11746993.html) 第一步: a) 搭建环境 引入 jedis jar包 co ...
- CEPH-5:ceph集群基本概念与管理
ceph集群基本概念与管理 ceph集群基本概念 ceph集群整体结构图 名称 作用 osd 全称Object Storage Device,主要功能是存储数据.复制数据.平衡数据.恢复数据等.每个O ...
- java架构师负载均衡、高并发、nginx优化、tomcat集群、异步性能优化、Dubbo分布式、Redis持久化、ActiveMQ中间件、Netty互联网、spring大型分布式项目实战视频教程百度网盘
15套Java架构师详情 * { font-family: "Microsoft YaHei" !important } h1 { background-color: #006; ...
- hadoop-2.4.1集群搭建及zookeeper管理
准备 1.1修改主机名,设置IP与主机名的映射 [root@xuegod74 ~]# vim /etc/hosts 192.168.1.73 xuegod73 192.168.1.74 xuegod7 ...
- zookeeper 伪集群安装和 zkui管理UI配置
#=======================[VM机器,二进制安装] # 安装环境# OS System = Linux CNT7XZKPD02 4.4.190-1.el7.elrepo.x86_ ...
- ES系列十六、集群配置和维护管理
一.修改配置文件 1.节点配置 1.vim elasticsearch.yml # ======================== Elasticsearch Configuration ===== ...
- kubernetes有状态集群服务部署与管理
有状态集群服务的两个需求:一个是存储需求,另一个是集群需求.对存储需求,Kubernetes的解决方案是:Volume.Persistent Volume .对PV,除了手动创建PV池外,还可以通过S ...
- Spark Storage(一) 集群下的区块管理
Storage模块 在Spark中提及最多的是RDD,而RDD所交互的数据是通过Storage来实现和管理 Storage模块整体架构 1. 存储层 在Spark里,单节点的Storage的管理是通过 ...
随机推荐
- Windows安装使用Chocolatey 包软件管理(类似 rpm , yum, brew , apt-get 包管理器工具)
Windows也能像Linux或者Mac那样命令行安装管理软件了,,,真的太方便了 下载安装 使用window powershell 用管理员运行 Set-ExecutionPolicy Bypass ...
- 不同页面的 body设置
由于SPA页面的特性,传统的设置 body 背景色的方法并不通用. 解决方案:利用组件内的路由实现 第一种方式 // 实例创建之前 beforeCreate(){ document.querySele ...
- 1.java基本语法
一.数据和数据类型 (一)标识符:给变量.常量.方法类.对象等命名的符号 (二)变量和常量 1.变量:值在运行时可以改变的量: 每个变量属于特定的数据类型,使用前要先声明,然后赋值,初始化或赋值后才能 ...
- jmeter--操作
Jmeter响应断言--正则表达式判断纯数字 这样是匹配14位数字,如果响应是纯数字可以直接用上 jmeter 随机取一个值的方法 1.添加用户自定义变量 在要用到随机值的地方写入 ${__Ran ...
- NDVI最大值合成
这里有NDVI250m分辨率的数据,目标:合成年最大值数据 [Spatial Analyst工具]|[局部分析]|[像元统计数据]
- Windows 下TCP长连接保持连接状态TCP keepalive设置
TCP长连接建立完成后,我们通常需要检测网络的连接状态,以反馈给客户做响应的处理.通过设置TCP keepalive的属性,打开socket的keepalive属性,并设置发送底层心跳包的时间间隔.T ...
- JDK 7 HashMap 并发情况下的死锁问题
目录 问题描述 详细解释 问题描述 JDK7的 HashMap 解决冲突用的是链表,在插入链表的时候用的是头插法,每次在链表的头部插入新元素.resize() 的时候用的依然是头插,头插的话,如果某个 ...
- SpringBoot——常用配置
application.yml配置信息 spring: profiles: active: dev application: name: jwt-token-security # Jackson 配置 ...
- linux环境下部署mysql环境
一.部署步骤 1.将安装包上传到Linux服务器上(目录随意),然后解压缩 2.进入到解压后的目录下,分别执行以下命令安装四个包(严格按照顺序执行) rpm -ivh mysql-community- ...
- CSS必知必会
CSS概念 css的使用是让网页具有统一美观的页面,css层叠样式表,简称样式表,文件后缀名.css css的规则由两部分构成:选择器以及一条或者多条声明 选择器:通常是需要改变的HTML元素 声明: ...