跟我读CVPR 2022论文:基于场景文字知识挖掘的细粒度图像识别算法
摘要:本文通过场景文字从人类知识库(Wikipedia)中挖掘其背后丰富的上下文语义信息,并结合视觉信息来共同推理图像内容。
本文分享自华为云社区《[CVPR 2022] 基于场景文字知识挖掘的细粒度图像识别算法》,作者: 谷雨润一麦。
本文简要介绍CVPR 2022录用的论文“Knowledge Mining with Scene Text for Fine-Grained Recognition”的主要工作。该论文旨在利用场景文本的线索来提升细粒度图像识别的性能。本文通过场景文字从人类知识库(Wikipedia)中挖掘其背后丰富的上下文语义信息,并结合视觉信息来共同推理图像内容。数据集和代码已开源,下载地址见文末。

研究背景
文字是人类传达信息、知识和情感的重要载体,其蕴含了丰富的语义信息。利用文字的语义信息,可以更好地理解图像中的内容。和文档文本不同,场景文字具有稀疏性,通常以少许关键词的形式存在于自然环境中,通过稀疏的关键词,机器难以获取精准的语义。然而,人类能够较为充分地理解稀疏的场景文字,其原因在于,人类具有大量的外部知识库,能够通过知识库来弥补稀疏的场景文字所带来的语义损失。
如图1所示:该数据集是关于细粒度图像分类任务,旨在区分图像中的瓶子属于哪种饮品或酒类。图中3张图像均属于soda类饮品,尽管(a)(b)两案例的瓶子具有不同的视觉属性(不同材质、形状),但是关键词soda提供了极具区分力的线索来告知样本属于soda饮品。尽管案例(c)同样属于soda类饮品,但是其附属的场景文本的表面信息无法提供明显的线索。表格(d)中列出了案例(c)中的场景文字在Wikipedia中的描述,Wikipedia告知我们,场景文本leninade代表某种品牌,其属于soda类饮品。因此,挖掘场景文本背后丰富的语义信息能够进一步弥补场景文本的语义损失,从而更为准确地理解图像中的目标。

- Bottle数据集中的案例,3张图像均属于soda类别
方法简述
算法框架:如图2所示,网络框架由视觉特征分支、知识提取分支和知识增强分支、视觉-知识注意力模块和分类器构成。算法输入包括3部分:图像,图像中包含的场景文本实例,外部知识库。其中场景文本实例通过已有的文字识别器从输入图像中获取,外部知识库采用了Wikipedia。知识提取分支提取场景文本实例背后的语义信息(知识特征),知识增强分支融合场景文本实例和挖掘出的知识特征。随后,视觉-知识注意力模块融合视觉和知识特征,并将其输入给分类器进行分类。
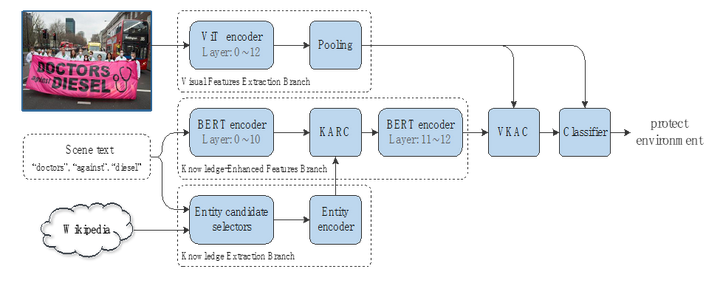
算法框架图,由视觉特征分支、知识提取分支和知识增强分支、视觉-知识注意力模块(VKAC)和分类器构成。
知识提取分支:该分支由实体候选选择器和实体编码器构成。在知识库中,同一关键词能够表示多个实体,比如apple可表示fruit apple,也可表示company apple。实体候选选择器预先在大量语料库上统计单词在所有可能实体上的概率分布,根据概率分布选取前10个候选实体,并将其输入给实体编码器进行特征编码。实体编码器在Wikipedia的数据库上进行预训练,预训练任务旨在通过Wikipedia上实体的描述来预测该页面的标题(实体名称)。通过此任务的学习,实体名称对于的特征编码了该词条的上下文信息。
知识增强特征分支:该分支主要由bert[1]构成,在bert的第10层后插入知识注意力模块(KARC),该模块融合了文本实例特征和知识特征后,接着输入给bert剩余的层。Bert第12层输出的特征给VKAC模块。KARC的网络结构如图3所示。
视觉-知识注意力模块:并非所有的场景文本或知识对理解图像有积极作用,为选取和图像内容相关的场景文本和知识来加强对图像的理解。该模块以图像全局特征作为访问特征,从增强的知识特征中选取相关的知识特征来加强视觉特征。其网络结构由注意力模型构成。
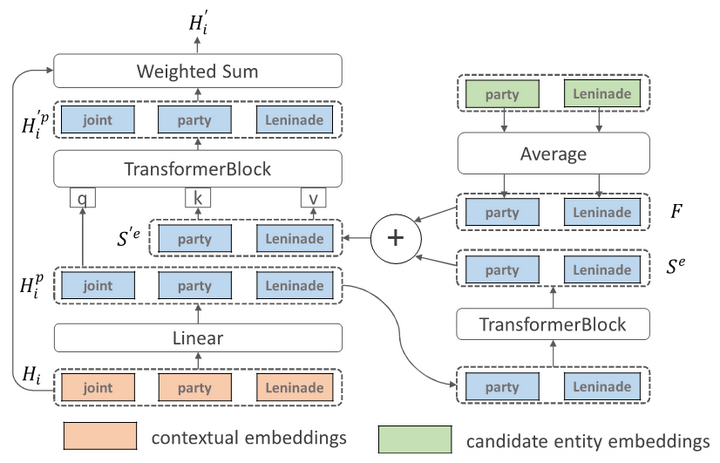
知识注意力模块(KARC),橙色和绿色模块是模块的两种输入
实验结果
为研究场景文本背后的知识对图像识别的帮助,我们收集了一个关于人群活动的数据集。该数据集中的类别主要分为游行示威和日常人群密集活动两大类,细分为21类。数据集案例如图4所示。

人群活动数据集样例
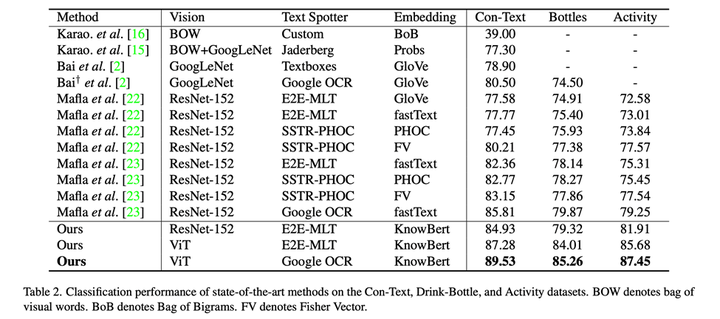
和SOTA对比:在公开数据集Con-Text、Bottles以及我们收集的Activity数据集上,在使用resnet50[3]和E2E-MLT[4]作为视觉特征提取器和文字提取器时,我们方法能在同等情况下取得最佳结果。当使用ViT和Google OCR时,其模型性能结果能进一步提升。
视觉、文本、知识特征对识别的影响:可以看出,文本的表面语义(Glove,fastText)在视觉网络为Resne50[3]的时候,能对识别性能有较大提升。当视觉网络为ViT[2]时,提升极其有限。如图5所示,Resnet50关注于主要于视觉目标具有区分力的区域,而ViT能同时关注在视觉目标和场景文字上。因此,再使用场景文字的表语含义难以对ViT有较大促进作用。而挖掘文本的背后语义后,能进一步提升ViT作为视觉backbone的模型的性能。
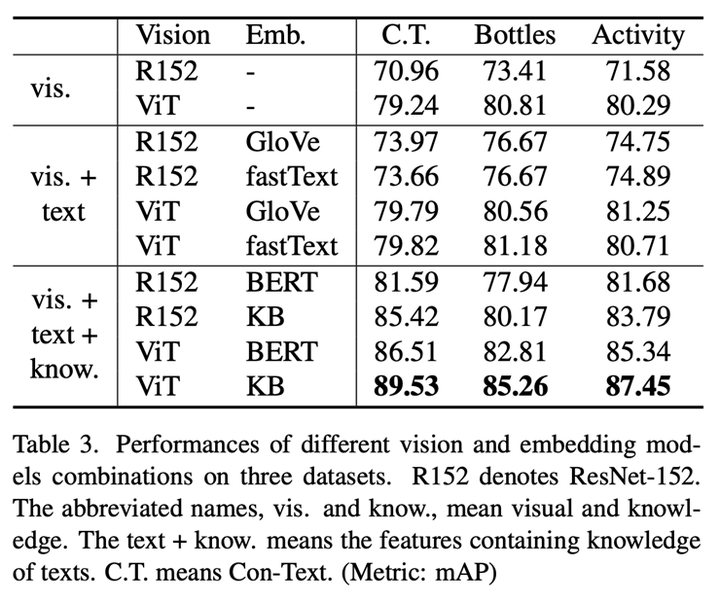

上下两行分别为resnet50和ViT模型的注意力热图
总结与结论
本文提出了一种通过挖掘场景文本背后语义来增强分类模型理解图像内容的方法,该方法的核心是利用场景文字作为关键词,到wikipedia知识库中检索出相关的知识,并获取其特征表达,和图像视觉特征进行融合理解,而并非仅仅利用场景文字的表面语义信息。得益于挖掘场景文本背后的知识,该方法能够更好地理解文字语义并不非常直观的内容。实验表明,该方法在3个数据集上均取得了最佳结果。
相关资源
论文地址:https://arxiv.org/pdf/2203.14215.pdf
数据集和代码链接:https://github.com/lanfeng4659/KnowledgeMiningWithSceneText
参考文献
[1] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[2] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[3] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[4] Bušta M, Patel Y, Matas J. E2e-mlt-an unconstrained end-to-end method for multi-language scene text[C]//Asian Conference on Computer Vision. Springer, Cham, 2018: 127-143.
跟我读CVPR 2022论文:基于场景文字知识挖掘的细粒度图像识别算法的更多相关文章
- CVPR 2022数据集汇总|包含目标检测、多模态等方向
前言 本文收集汇总了目前CVPR 2022已放出的一些数据集资源. 转载自极市平台 欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结.最新技术跟踪.经典论文解读.CV招聘信息. M5Produc ...
- CVPR 2013 关于图像/场景分类(classification)的文章paper list
CVPR 2013 关于图像/场景分类(classification)的文章paper list 八14by 小军 这个搜罗了cvpr2013有关于classification的相关文章,自己得m ...
- 浅析点对点(End-to-End)的场景文字识别(图片文字)
一.背景 随着智能手机的广泛普及和移动互联网的迅速发展,通过手机等移动终端的摄像头获取.检索和分享资讯已经逐步成为一种生活方式.基于摄像头的 (Camera-based)的应用更加强调对拍摄场景的理解 ...
- 基于局部敏感哈希的协同过滤算法之simHash算法
搜集了快一个月的资料,虽然不完全懂,但还是先慢慢写着吧,说不定就有思路了呢. 开源的最大好处是会让作者对脏乱臭的代码有羞耻感. 当一个做推荐系统的部门开始重视[数据清理,数据标柱,效果评测,数据统计, ...
- 20155206赵飞 基于《Arm试验箱的国密算法应用》课程设计个人报告
20155206赵飞 基于<Arm试验箱的国密算法应用>课程设计个人报告 课程设计中承担的任务 完成试验箱测试功能1,2,3 . 1:LED闪烁实验 一.实验目的 学习GPIO原理 ...
- 2015520吴思其 基于《Arm试验箱的国密算法应用》课程设计个人报告
20155200吴思其 基于<Arm试验箱的国密算法应用>课程设计个人报告 课程设计中承担的任务 完成试验箱测试功能4,5,6以及SM3加密实验的实现 测试四 GPIO0按键中断实验 实验 ...
- Android应用开发进阶篇-场景文字识别
因为研究生毕业项目须要完毕一个基于移动终端的场景文字识别系统.尽管离毕业尚早,但出于兴趣的缘故,近一段抽时间完毕了这样一套系统. 主要的架构例如以下: client:Android应用实现拍摄场景图片 ...
- Faster-RCNN用于场景文字检测训练测试过程记录(转)
[训练测试过程记录]Faster-RCNN用于场景文字检测 原创 2017年11月06日 20:09:00 标签: 609 编辑 删除 写在前面:github上面的Text-Detection-wit ...
- 基于均值坐标(Mean-Value Coordinates)的图像融合算法的具体实现
目录 1. 概述 2. 实现 2.1. 准备 2.2. 核心 2.2.1. 均值坐标(Mean-Value Coordinates) 2.2.2. ROI边界栅格化 2.2.3. 核心实现 2.2.4 ...
随机推荐
- Spark—GraphX编程指南
Spark系列面试题 Spark面试题(一) Spark面试题(二) Spark面试题(三) Spark面试题(四) Spark面试题(五)--数据倾斜调优 Spark面试题(六)--Spark资源调 ...
- Java如何使用实时流式计算处理?
我是3y,一年CRUD经验用十年的markdown程序员常年被誉为职业八股文选手 最近如果拉过austin项目代码的同学,可能就会发现多了一个austin-stream模块.其实并不会意外,因为这一 ...
- 解释JDBC抽象和DAO模块?
通过使用JDBC抽象和DAO模块,保证数据库代码的简洁,并能避免数据库资源错误关闭导致的问题,它在各种不同的数据库的错误信息之上,提供了一个统一的异常访问层.它还利用Spring的AOP 模块给Spr ...
- composer安装报错
问题报错:Fatal error: Declaration of Fxp\Composer\AssetPlugin\Repository\AbstractAssetsRepository::searc ...
- java-LinkedMap
输入一组数,输出是按每个出现的频率,比如1,3,3,4,5,9,9,9,3,3,输出为3,3,3,3,9,9,9,1,4,5如果频率一样就按原顺序输出. package com.lyb.array;i ...
- Leetcode26——删除有序数组中的重复项(双指针法)
Leetcode26--删除有序数组中的重复项(双指针法) 1. 题目简述 给你一个升序排列的数组 nums ,请你原地 删除重复出现的元素,使每个元素只出现一次 ,返回删除后数组的新长度.元素的相对 ...
- leetcode_两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标. 你可以假设每种输入只会对应一个答案.但是,数组中同 ...
- I2C总线完全版——I2C总线的结构、工作时序与模拟编程
I2C总线的结构.工作时序与模拟编程 I2C总线的结构.工作时序与模拟编程I2C总线(Inter Integrated Circuit)是飞利浦公司于上个世纪80年代开发的一种"电路板级&q ...
- 单片机ram和rom的区别
单片机运行时需要调用某个程序/函数/固定数据时就需要读取ROM,然后在RAM中执行这些程序/函数的功能,所产生的临时数据也都存在RAM内,断电后这些临时数据就丢失了.ROM:(Read Only Me ...
- 5_终值定理和稳态误差_Final Value Theorem & Steady State Error