强化学习-学习笔记8 | Q-learning
上一篇笔记认识了Sarsa,可以用来训练动作价值函数\(Q_\pi\);本篇来学习Q-Learning,这是另一种 TD 算法,用来学习 最优动作价值函数 Q-star,这就是之前价值学习中用来训练 DQN 的算法。
8. Q-learning
承接上一篇的疑惑,对比一下两个算法。
8.1 Sarsa VS Q-Learning
这两个都是 TD 算法,但是解决的问题不同。
Sarsa
- Sarsa 训练动作价值函数 \(Q_\pi(s,a)\);
- TD target:\(y_t = r_t + \gamma \cdot {Q_\pi(s_{t+1},a_{t+1})}\)
- 价值网络是 \(Q_\pi\) 的函数近似,Actor-Critic 方法中,用 Sarsa 更新价值网络(Critic)
Q-Learning
Q-learning 是训练最优动作价值函数 \(Q^*(s,a)\)
TD target :\(y_t = r_t + \gamma \cdot {\mathop{max}\limits_{a}Q^*(s_{t+1},a_{t+1})}\),对 Q 求最大化
注意这里就是区别。
用Q-learning 训练DQN
个人总结区别在于Sarsa动作是随机采样的,而Q-learning是取期望最大值
下面推导 Q-Learning 算法。
8.2 Derive TD target
注意Q-learning 和 Sarsa 的 TD target 有区别。
之前 Sarsa 证明了这个等式:\(Q_\pi({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot Q_\pi({S_{t+1}},{A_{t+1}})]\)
等式的意思是,\(Q_\pi\) 可以写成 奖励 以及 \(Q_\pi\) 对下一时刻做出的估计;
等式两端都有 Q,并且对于所有的 \(\pi\) 都成立。
所以把最优策略记作 \(\pi^*\),上述公式对其也成立,有:
\(Q_{\pi^*}({s_t},{a_t}) = \mathbb{E}[{R_t} + \gamma \cdot Q_{\pi^*}({S_{t+1}},{A_{t+1}})]\)
通常把\(Q_{\pi^*}\) 记作 \(Q^*\),都可以表示最优动作价值函数,于是便得到:
\(Q^*({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot Q^*({S_{t+1}},{A_{t+1}})]\)
处理右侧 期望中的 \(Q^*\),将其写成最大化形式:
因为\(A_{t+1} = \mathop{argmax}\limits_{a} Q^*({S_{t+1}},{a})\) ,A一定是最大化 \(Q^*\)的那个动作
解释:
给定状态\(S_{t+1}\),Q* 会给所有动作打分,agent 会执行分值最高的动作。
因此 \(Q^*({S_{t+1}},{A_{t+1}}) = \mathop{max}\limits_{a} Q^*({S_{t+1}},{a})\),\(A_{t+1}\) 是最优动作,可以最大化 \(Q^*\);
带入期望得到:\(Q^({s_t},{a_t})=\mathbb{E}[{R_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({S_{t+1}},{a})]\)
左边是 t 时刻的预测,等于右边的期望,期望中有最大化;期望不好求,用蒙特卡洛近似。用 \(r_t \ s_{t+1}\) 代替 \(R_t \ S_{t+1}\);
做蒙特卡洛近似:\(\approx {r_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},{a})\)称为TD target \(y_t\)。
此处 \(y_t\) 有一部分真实的观测,所以比左侧 Q-star 完全的猜测要靠谱,所以尽量要让左侧 Q-star 接近 \(y_t\)。
8.3 算法过程
a. 表格形式
- 观测一个transition \(({s_t},{a_t},{r_t},{s_{t+1}})\)
- 用 \(s_{t+1} \ r_t\) 计算 TD target:\({r_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},{a})\)
- Q-star 就是下图这样的表格:
找到状态 \(s_{t+1}\) 对应的行,找出最大元素,就是 \(Q^*\) 关于 a 的最大值。
- 计算 TD error: \(\delta_t = Q^*({s_t},{a_t}) - y_t\)
- 更新\(Q^*({s_t},{a_t}) \leftarrow Q^*({s_t},{a_t}) - \alpha \cdot \delta_t\),更新\((s_{t},a_t)\)位置,让Q-star 值更接近 \(y_t\)
b. DQN形式
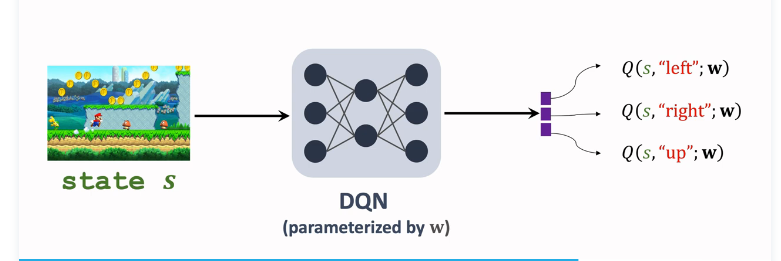
DQN \(Q^*({s},{a};w)\)近似 $Q^*({s},{a}) $,输入是当前状态 s,输出是对所有动作的打分;
接下来选择最大化价值的动作 \({a_t}= \mathop{argmax}\limits_{{a}} Q^*({S_{t+1}},{a},w)\),让 agent 执行 \(a_t\);用收集到的 transitions 学习训练参数 w,让DQN 的打分 q 更准确;
用 Q-learning 训练DQN的过程:
- 观测一个transition \(({s_t},{a_t},{r_t},{s_{t+1}})\)
- TD target: \({r_t} + \gamma \cdot \mathop{max}\limits_{a} Q^*({s_{t+1}},{a};w)\)
- TD error: \(\delta_t = Q^*({s_t},{a_t};w) - y_t\)
- 梯度下降,更新参数: \(w \leftarrow w -\alpha \cdot \delta_t \cdot \frac{{s_t},{a_t};w}{\partial w}\)
x. 参考教程
- 视频课程:深度强化学习(全)_哔哩哔哩_bilibili
- 视频原地址:https://www.youtube.com/user/wsszju
- 课件地址:https://github.com/wangshusen/DeepLearning
- 笔记参考:
强化学习-学习笔记8 | Q-learning的更多相关文章
- 强化学习系列之:Deep Q Network (DQN)
文章目录 [隐藏] 1. 强化学习和深度学习结合 2. Deep Q Network (DQN) 算法 3. 后续发展 3.1 Double DQN 3.2 Prioritized Replay 3. ...
- 强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning)
强化学习读书笔记 - 06~07 - 时序差分学习(Temporal-Difference Learning) 学习笔记: Reinforcement Learning: An Introductio ...
- 强化学习9-Deep Q Learning
之前讲到Sarsa和Q Learning都不太适合解决大规模问题,为什么呢? 因为传统的强化学习都有一张Q表,这张Q表记录了每个状态下,每个动作的q值,但是现实问题往往极其复杂,其状态非常多,甚至是连 ...
- 强化学习_Deep Q Learning(DQN)_代码解析
Deep Q Learning 使用gym的CartPole作为环境,使用QDN解决离散动作空间的问题. 一.导入需要的包和定义超参数 import tensorflow as tf import n ...
- 强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods)
强化学习读书笔记 - 05 - 蒙特卡洛方法(Monte Carlo Methods) 学习笔记: Reinforcement Learning: An Introduction, Richard S ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习读书笔记 - 10 - on-policy控制的近似方法
强化学习读书笔记 - 10 - on-policy控制的近似方法 学习笔记: Reinforcement Learning: An Introduction, Richard S. Sutton an ...
- 强化学习读书笔记 - 09 - on-policy预测的近似方法
强化学习读书笔记 - 09 - on-policy预测的近似方法 参照 Reinforcement Learning: An Introduction, Richard S. Sutton and A ...
- 强化学习读书笔记 - 02 - 多臂老O虎O机问题
# 强化学习读书笔记 - 02 - 多臂老O虎O机问题 学习笔记: [Reinforcement Learning: An Introduction, Richard S. Sutton and An ...
随机推荐
- SerialPort-4.0.+ 使用说明(Kotlin版本)
SerialPort-4.0.+ 项目官网 Java版本使用说明 介绍 SerialPort 是一个开源的对 Android 蓝牙串口通信的轻量封装库,轻松解决了构建自己的串口调试APP的复杂程度,让 ...
- i2c调试工具分享
i2c-tools简介 在嵌入式开发仲,有时候需要确认硬件是否正常连接,设备是否正常工作,设备的地址是多少等等,这里我们就需要使用一个用于测试I2C总线的工具--i2c-tools. i2c-tool ...
- 在Ubuntu安装eclipse环境
下载准备 1安装jdk,笔者安装的是jdk-8u121-linux-x64 2安装eclipse,下载地址:http://www.eclipse.org/downloads/packages/ecli ...
- kubeadm高可用master节点(三主两从)
1.安装要求 在开始之前,部署Kubernetes集群机器需要满足以下几个条件: 五台机器,操作系统 CentOS7.5+(mini) 硬件配置:2GBRAM,2vCPU+,硬盘30GB+ 集群中所有 ...
- CentOS 7 执行 yum 命令失败问题的排查方法
一个执着于技术的公众号 简介 本文主要为大家讲解 CentOS 7系统中执行yum命令失败等常见问题的排查方法. 1.执行yum命令报404错误 1)检查yum仓库是否配置正确,可以到阿里云下载rep ...
- 面试官:我把数据库部署在Docker容器内,你觉得如何?
开源Linux 一个执着于技术的公众号 上一篇:CentOS 7上搭建Zabbix4.0 近2年Docker非常的火热,各位开发者恨不得把所有的应用.软件都部署在Docker容器中,但是您确定也要把数 ...
- 初探webpack之编写loader
初探webpack之编写loader loader加载器是webpack的核心之一,其用于将不同类型的文件转换为webpack可识别的模块,即用于把模块原内容按照需求转换成新内容,用以加载非js模块, ...
- c++:-3
上一节学习了C++的函数:c++:-2,本节学习C++的数组.指针和字符串 数组 定义和初始化 定义 例如:int a[10]; 表示a为整型数组,有10个元素:a[0]...a[9] 例如: int ...
- RabbitMQ 3.9( 基础 )
1.认识MQ 1.1.什么是MQ? MQ全称:message queue 即 消息队列 这个队列遵循的原则:FIFO 即 先进先出 队列里面存的就是message 1.2.为什么要用MQ? 1.2.1 ...
- 设计模式---单例模式,pickle模块
设计模式---单例模式 简介 单例模式(Singleton Pattern) 是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实 例存在.当你希望在整个系统中,某个类只能出现一个实例时 ...