Pytorch分布式训练
用单机单卡训练模型的时代已经过去,单机多卡已经成为主流配置。如何最大化发挥多卡的作用呢?本文介绍Pytorch中的DistributedDataParallel方法。
1. DataParallel
其实Pytorch早就有数据并行的工具DataParallel,它是通过单进程多线程的方式实现数据并行的。
简单来说,DataParallel有一个参数服务器的概念,参数服务器所在线程会接受其他线程传回来的梯度与参数,整合后进行参数更新,再将更新后的参数发回给其他线程,这里有一个单对多的双向传输。因为Python语言有GIL限制,所以这种方式并不高效,比方说实际上4卡可能只有2~3倍的提速。
2. DistributedDataParallel
Pytorch目前提供了更加高效的实现,也就是DistributedDataParallel。从命名上比DataParallel多了一个分布式的概念。首先 DistributedDataParallel是能够实现多机多卡训练的,但考虑到大部分的用户并没有多机多卡的环境,本篇博文主要介绍单机多卡的用法。
从原理上来说,DistributedDataParallel采用了多进程,避免了python多线程的效率低问题。一般来说,每个GPU都运行在一个单独的进程内,每个进程会独立计算梯度。
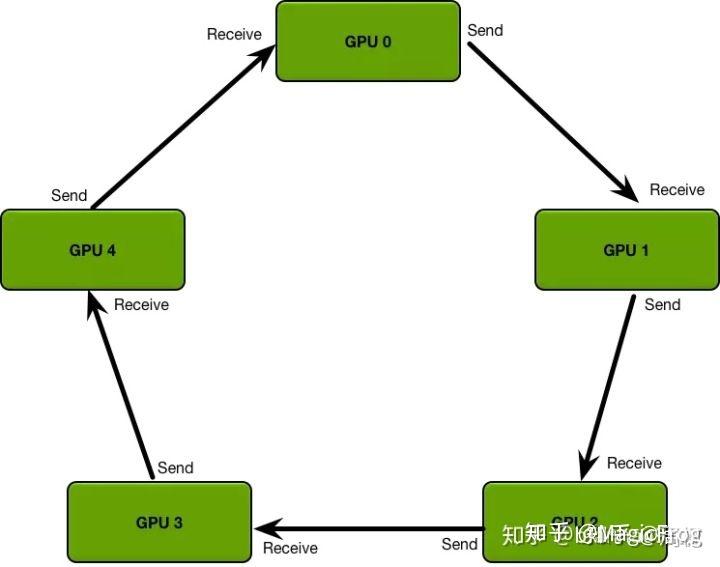
同时DistributedDataParallel抛弃了参数服务器中一对多的传输与同步问题,而是采用了环形的梯度传递,这里引用知乎上的图例。这种环形同步使得每个GPU只需要和自己上下游的GPU进行进程间的梯度传递,避免了参数服务器一对多时可能出现的信息阻塞。
3. DistributedDataParallel示例
下面给出一个非常精简的单机多卡示例,分为六步实现单机多卡训练。
第一步,首先导入相关的包。
import argparse
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
第二步,加一个参数,local_rank。这比较好理解,相当于就是告知当前的程序跑在那一块GPU上,也就是下面的第三行代码。local_rank是通过pytorch的一个启动脚本传过来的,后面将说明这个脚本是啥。最后一句是指定通信方式,这个选nccl就行。
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=-1, type=int)
args = parser.parse_args()
torch.cuda.set_device(args.local_rank)
dist.init_process_group(backend='nccl')
第三步,包装Dataloader。这里需要的是将sampler改为DistributedSampler,然后赋给DataLoader里面的sampler。
为什么需要这样做呢?因为每个GPU,或者说每个进程都会从DataLoader里面取数据,指定DistributedSampler能够让每个GPU取到不重叠的数据。
读者可能会比较好奇,在下面指定了batch_size为24,这是说每个GPU都会被分到24个数据,还是所有GPU平分这24条数据呢?答案是,每个GPU在每个iter时都会得到24条数据,如果你是4卡,一个iter中总共会处理24*4=96条数据。
train_sampler = torch.utils.data.distributed.DistributedSampler(my_trainset)
trainloader = torch.utils.data.DataLoader(my_trainset,batch_size=24,num_workers=4,sampler=train_sampler)
第四步,使用DDP包装模型。device_id仍然是args.local_rank。
model = DDP(model, device_ids=[args.local_rank])
第五步,将输入数据放到指定GPU。后面的前后向传播和以前相同。
for imgs,labels in trainloader:
imgs=imgs.to(args.local_rank)
labels=labels.to(args.local_rank)
optimizer.zero_grad()
output=net(imgs)
loss_data=loss(output,labels)
loss_data.backward()
optimizer.step()
第六步,启动训练。torch.distributed.launch就是启动脚本,nproc_per_node是GPU数。
python -m torch.distributed.launch --nproc_per_node 2 main.py
通过以上六步,我们就让模型跑在了单机多卡上。是不是也没有那么麻烦,但确实要比DataParallel复杂一些,考虑到加速效果,不妨试一试。
4. DistributedDataParallel注意点
DistributedDataParallel是多进程方式执行的,那么有些操作就需要小心了。如果你在代码中写了一行print,并使用4卡训练,那么你将会在控制台看到四行print。我们只希望看到一行,那该怎么做呢?
像下面一样加一个判断即可,这里的get_rank()得到的是进程的标识,所以输出操作只会在进程0中执行。
if dist.get_rank() == 0:
print("hah")
你会经常需要dist.get_rank()的。因为有很多操作都只需要在一个进程里执行,比如保存模型,如果不加以上判断,四个进程都会写模型,可能出现写入错误;另外load预训练模型权重时,也应该加入判断,只load一次;还有像输出loss等一些场景。
【参考】https://zhuanlan.zhihu.com/p/178402798
Pytorch分布式训练的更多相关文章
- [源码解析] 深度学习分布式训练框架 Horovod (1) --- 基础知识
[源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 目录 [源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 0x00 摘要 0x01 分布式并 ...
- [源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入
[源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入 目录 [源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入 0x00 摘要 0 ...
- [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架
[源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 目录 [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 0x00 摘要 0x01 架构图 ...
- [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构
[源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 目录 [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 0x00 摘要 0x01 ...
- [源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化 目录 [源码解析] PyTorch 分布式(9) ----- DistributedD ...
- [源码解析] PyTorch 分布式(10)------DistributedDataParallel 之 Reducer静态架构
[源码解析] PyTorch 分布式(10)------DistributedDataParallel之Reducer静态架构 目录 [源码解析] PyTorch 分布式(10)------Distr ...
- [源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer
[源码解析] PyTorch 分布式(11) ----- DistributedDataParallel 之 构建Reducer 目录 [源码解析] PyTorch 分布式(11) ----- Dis ...
- [源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播
[源码解析] PyTorch 分布式(12) ----- DistributedDataParallel 之 前向传播 目录 [源码解析] PyTorch 分布式(12) ----- Distribu ...
- [源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播
[源码解析] PyTorch 分布式(13) ----- DistributedDataParallel 之 反向传播 目录 [源码解析] PyTorch 分布式(13) ----- Distribu ...
随机推荐
- .NET MAUI RC2 发布,支持 Tizen 平台
在.NET多平台应用程序UI(.NET MAUI)RC1之后仅两周,微软已经发布了RC2,并以新的Tizen支持为亮点..NET MAUI是微软对Xamarin.Forms的演变,因为它除了iOS和A ...
- 测试必会 Docker 实战(一):掌握高频命令,夯实内功基础
在 Dokcer 横空出世之前,应用打包一直是大部分研发团队的痛点.在工作中,面对多种服务,多个服务器,以及多种环境,如果还继续用传统的方式打包部署,会浪费大量时间精力. 在 Docker 出现后,它 ...
- [题解] [AGC022E] Median Replace
题目大意 有个奇数长度的 \(01\) 串 \(s\) 其中有若干位置是 \(?\). 每次可将 \(3\) 个连续的字符替换成这三个数的中位数. 求有多少方案将 \(?\) 替换成 \(0/1\) ...
- fedora访问win10共享
sudo mount -t cifs -o username=user,password=123 //192.168.31.20/aa /home/liao/win
- Spring Boot配置全局异常捕获
1 SpringBoot配置全局的异常捕获 项目的说明 配置thymeleaf作为视图模板 ExceptionController.java模拟测试用 MyAjaxExceptionHandler.j ...
- MongoDB启动报错:Unrecognized option: storage try 'mongod --help' for more information(已解决)
问题说明: 今天在使用配置文件方式启动MongoDB时,一直启动失败,报错显示:Unrecognized option: storage try 'mongod --help' for more in ...
- Android——RelativeLayout
代码:<?xml version="1.0" encoding="utf-8"?><RelativeLayout xmlns:android= ...
- freeswitch使用mod_shout模块播放mp3
概述 freeswitch 在对VOIP语音通话中,可以通过playback命令播放IVR语音文件. 默认情况下,freeswitch支持wav文件,也可以直接播放VOIP中常见编解码的G711文件. ...
- torch.rand、torch.randn、torch.normal、torch.linespace
torch.rand(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False) # ...
- ESXI系列问题整理以及记录——使用SSH为设备打VIB驱动包,同时提供一种对于ESXI不兼容螃蟹网卡(Realtek 瑞昱)的问题解决思路
对于ESXI不兼容螃蟹网卡的问题,这里建议购买一张博通的低端单口千兆网卡,先使用博通网卡完成系统部署,再按照下文方法添加螃蟹网卡的VIB驱动,最后拆除博通网卡. 螃蟹网卡VIB驱动包下载地址:http ...