某宝抢购taobaosnap开发与实现
某宝抢购脚本
Taobaosnap
Taobaosnap is a completely open tool, which is used to buy goods in seconds on Taobao. This is a project created with python, using selenium and requests module to achieve login and snap-up. The project integrates network script ideas and improves them, using selenium to realize remote login and login verification problems. Use requests for snapping without rendering, reducing the time required for access and snapping. Use the countdown idea to realize automatic snapping when the time is up. The number of times of use is set, which is convenient for reading and analyzing the program log after the snap-up is over.(This description is for versions higher than 3.1.5)
关于Taobaosnap的介绍描述已经在项目的readme.md写的非常详细了,大家可自行访问开源项目查看。(代码已于git托管并开源)
项目开发经历
基于战队队长对于手动抢购一周仍一墩无购的情况,我们在网络上找到了两位开发者写的抢购脚本。
requests方案
1、来自"Charles的比卡丘"师傅的程序使用python开发,使用requests模块,以requests的方式获取登录二维码进行扫码登陆后直接进行购物车信息获取,选择并抢购。该代码使用了request请求的方式直接进行抢购.
优点:访问速度快,无需渲染。
缺点:容易触发反爬虫(经大量数据测试,极大多数情况下前四次正常,第五次无法获取购物车信息),登录遇到二次校验或三次校验(二次校验概率非常高,三次校验概率较低。该情况会导致部分账号无法登录),抢购第四五次会触发校验。
selenium+webdriver方案
2、来自"SWHL"师傅的程序同样使用python开发,使用selenium模块,以webdriver的形式自动打开浏览器,使用浏览器自动操做。该项目使用了读秒的方式计算抢购开始时间,抢购以自动化可视化操做提交订单。
优点:解决了登录校验的问题,能够完成或多次登的录校验。读秒抢购,减少请求次数。
缺点:访问速度慢,页面访问需要渲染,对于网络速度的要求相对较高。
下面我们来分析一下某宝的反爬虫策略
selenium抓取一个网站的时候,容易被识别为爬虫。我们来分析一下识别点:
- 账号密码或手机号登录容易触发反爬虫机制。
- 某宝官方提取浏览器驱动的指纹特征,比如chromedriver,firefox的webdriver,edge的msedgedriver。
- 重复提交登录申请而未完成登录校验。
- 多次提交订单而未完成校验。
反爬虫与应对策略
- 使用扫码登录并完成多次校验,避免登录过程被反爬;
- 经过测试发现,对selenium中chrome进行配置后,可将chromedriver触发的某宝官网中 window.navigator.webdriver 由true变为flase,进而避免反爬;
- 由于此处使用webdriver会导致抢购速度慢,需要等待页面渲染。requests不便实现 再次使用webdriver弹出校验。该问题目前暂无良好解决方案;
- 此处可以参考使用 mitmproxy 蔽掉识别 webdriver 标识符的 js 文件;
- 设置抢购开始时间,读秒并与系统时间比对。同时设置抢购次数(测试建议五次)。
理论与思路
- 使用selenium模块与webdriver调用chromedriver完成登录与登录校验。
- 将selenium登陆完后获取列表形式的cookie转换为requests请求字典形式cookie,并使用requests方案获取购物车信息。
- 使用读秒思路比对抢购时间,设置抢购次数限制,减少反爬虫触犯几率。
优点:解决登录校验的问题,完成或多次登的录校验。读秒抢购,减少请求次数。访问速度快,无需渲染。不易触发反爬虫机制。
缺点:requests不便实现 再次使用webdriver弹出校验
项目思路
登录
使用selenium库与webdriver实现图形化登录,以解决requests登录方式无法完成登录验证的问题。
1 def cookie_info():
2 chrome_options = webdriver.ChromeOptions()
3 chrome_options.add_argument("start-maximized")
4
5 login_url = 'https://login.taobao.com/member/login.jhtml?spm=a21bo.jianhua.201864-2.d1.5af911d9lhGWni&f=top&redirectURL=http%3A%2F%2Fwww.taobao.com%2F'
6 driver = webdriver.Chrome(options=chrome_options)
7 print("请尽快扫码!")
8 driver.get(login_url)
9 driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
10 "source": """
11 Object.defineProperty(navigator, 'webdriver', {
12 get: () => undefined
13 })
14 """
15 }) # 给window.navigator定义一个undefined,绕过js检测
16 time.sleep(50) # 预留了安全验证的时间
17 driver.refresh() # 刷新页面
18 c = driver.get_cookies()
19 sessions = dict()
20 for cookie in c:
21 sessions[cookie['name']] = cookie['value']
22 driver.quit()
23 return sessions
经多次测试,安全验证时间采用15s停留,以应对二次校验。
命令参数解析
1 def parseArgs():
2 parser = argparse.ArgumentParser(description='抢购脚本')
3 parser.add_argument('--time', dest='time', help='秒杀时间', type=str, required=True)
4 parser.add_argument('--interval', dest='interval', help='抢购商品的时间间隔(单位秒)', type=float, required=True)
5 parser.add_argument('--l', dest='number', help='抢购商品的次数', type=int, required=True)
6 args = parser.parse_args()
7 return args
获取购物车
1 def buycartinfo(self):
2 url = 'https://cart.taobao.com/cart.htm'
3 headers = {
4 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
5 'sec-fetch-dest': 'document', 'sec-fetch-mode': 'navigate', 'sec-fetch-site': 'none', 'sec-fetch-user': '?1',
6 'upgrade-insecure-requests': '1',
7 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
8 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
9 'cache-control': 'max-age=0'
10 }
11 response = self.session.get(url, headers=headers)
12 response_json = re.search('try{var firstData = (.*?);}catch', response.text).group(1)
13 response_json = json.loads(response_json)
14 user_id = re.search('\|\^taoMainUser:(.*?):\^', response.headers['s_tag']).group(1)
15 return response_json, user_id
抢购时间比对与次数限制
时间比对与自动抢购。列出实时时间并比对抢购时间。此处若有因反爬虫检测导致提交订单失败将给出提示。
1 print(f'[{time.strftime("%H:%M:%S", time.localtime())} INFO]: 正在尝试抢购商品***{good_infos[good_id]["title"]}***')
2 # 对比时间,时间到的话就点击结算
3 while True:
4 now = datetime.datetime.now().strftime('%H:%M:%S.%f')
5 print(now)
6 if now > self.Seconds_kill_time:
7 for i in range(self.number):
8 try:
9 is_success = self.buygood(good_infos[good_id], user_id)
10 except Exception as err:
11 crawler = re.findall("'NoneType' object has no attribute 'group'",str(err))
12 if "'NoneType' object has no attribute 'group'" in crawler:
13 print("已触发反爬虫机制,请稍后尝试! 错误信息如下:\n{0}\n".format(err))
14 # is_success = False
15 break
16 else:
17 print(f'[{time.strftime("%H:%M:%S", time.localtime())} INFO]: 抢购失败, 错误信息如下: \n{err}\n将在{self.trybuy_interval}秒后重新尝试.')
18 is_success = False
19 if i == self.number-1 and is_success == False:
20 print("抢购失败")
21 break
22 elif is_success:
23 print(f'[{time.strftime("%H:%M:%S", time.localtime())} INFO]: 抢购***{good_infos[good_id]["title"]}***成功, 已为您自动提交订单, 请尽快完成付款.')
24 # 电脑语音提示
25 for _ in range(5):
26 pyttsx3.speak('已经为您抢购到你所需的商品, 请尽快完成付款.')
27 time.sleep(self.trybuy_interval)
28 break
29 break
结算请求
抢购数据使用requests提交,该方案优于自动抢购webdriver方案,无需渲染,自动提交抢购请求,提高抢购速度。
1 def buygood(self, info, user_id):
2 # 发送结算请求
3 url = 'https://buy.taobao.com/auction/order/confirm_order.htm?spm=a1z0d.6639537.0.0.undefined'
4 headers = {
5 'cache-control': 'max-age=0', 'upgrade-insecure-requests': '1',
6 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
7 'origin': 'https://cart.taobao.com', 'content-type': 'application/x-www-form-urlencoded',
8 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
9 'sec-fetch-site': 'same-site', 'sec-fetch-mode': 'navigate', 'sec-fetch-user': '?1',
10 'sec-fetch-dest': 'document', 'referer': 'https://cart.taobao.com/',
11 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8'
12 }
13 cart_id, item_id, sku_id, seller_id, cart_params, to_buy_info = info['cart_id'], info['item_id'], info['sku_id'], info['seller_id'], info['cart_params'], info['to_buy_info']
14 data = {
15 'item': f'{cart_id}_{item_id}_1_{sku_id}_{seller_id}_0_0_0_{cart_params}_{urllib.parse.quote(str(to_buy_info))}__0',
16 'buyer_from': 'cart',
17 'source_time': ''.join(str(int(time.time() * 1000)))
18 }
19 disable_warnings()
20 response = self.session.post(url = url, data = data, headers = headers, verify = False)
21 order_info = re.search('orderData= (.*?);\n</script>', response.text).group(1)
22 order_info = json.loads(order_info)
23 # 发送提交订单请求
24 token = self.session.cookies['_tb_token_']
25 endpoint = order_info['endpoint']
26 data = order_info['data']
27 structure = order_info['hierarchy']['structure']
28 hierarchy = order_info['hierarchy']
29 linkage = order_info['linkage']
30 linkage.pop('url')
31 submitref = order_info['data']['submitOrderPC_1']['hidden']['extensionMap']['secretValue']
32 sparam1 = order_info['data']['submitOrderPC_1']['hidden']['extensionMap']['sparam1']
33 input_charset = order_info['data']['submitOrderPC_1']['hidden']['extensionMap']['input_charset']
34 event_submit_do_confirm = order_info['data']['submitOrderPC_1']['hidden']['extensionMap']['event_submit_do_confirm']
35 url = f'https://buy.taobao.com/auction/confirm_order.htm?x-itemid={item_id}&x-uid={user_id}&submitref={submitref}&sparam1={sparam1}'
36 data_submit = {}
37 for key, value in data.items():
38 if value.get('submit') == 'true' or value.get('submit'):
39 data_submit[key] = value
40 data = {
41 'action': '/order/multiTerminalSubmitOrderAction',
42 '_tb_token_': token,
43 'event_submit_do_confirm': '1',
44 'praper_alipay_cashier_domain': 'cashierrz54',
45 'input_charset': 'utf-8',
46 'endpoint': urllib.parse.quote(json.dumps(endpoint)),
47 'data': urllib.parse.quote(json.dumps(data_submit)),
48 'hierarchy': urllib.parse.quote(json.dumps({"structure": structure})),
49 'linkage': urllib.parse.quote(json.dumps(linkage))
50 }
51 headers = {
52 'cache-control': 'max-age=0', 'upgrade-insecure-requests': '1', 'origin': 'https://buy.taobao.com',
53 'content-type': 'application/x-www-form-urlencoded',
54 'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36',
55 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
56 'sec-fetch-site': 'same-origin', 'sec-fetch-mode': 'navigate', 'sec-fetch-user': '?1',
57 'sec-fetch-dest': 'document',
58 'referer': 'https://buy.taobao.com/auction/order/confirm_order.htm?spm=a1z0d.6639537.0.0.undefined',
59 'accept-encoding': 'gzip, deflate, br', 'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8'
60 }
61 response = self.session.post(url, data=data, headers=headers, verify = False)
62 if response.status_code == 200: return True
63 return False
使用方式
- 从https://kaydenlsr.coding.net/public/taobaosnap/taobaosnap/git/files解压最新版taobaosnap
- 安装相关依赖 pip install [modules]
- 下载chrome浏览器和对应的chromedriver,放到python.exe目录下。项目提供chromedriver version = 99.0.4844.51
- 运行cmd并运行’python taobaosnap.py --interval [时间间隔] --time [开始时间] --l [频率]
例子
1 $ python taobaosnap.py --interval 0.1 --time 15:59:59:90000000 --l 5
帮助
1 usage : python taobaosnap.py
2 --time Buying time and format: 00:00:00:00000000.
3 --interval Buying time interval.
4 --l Buying frequency.
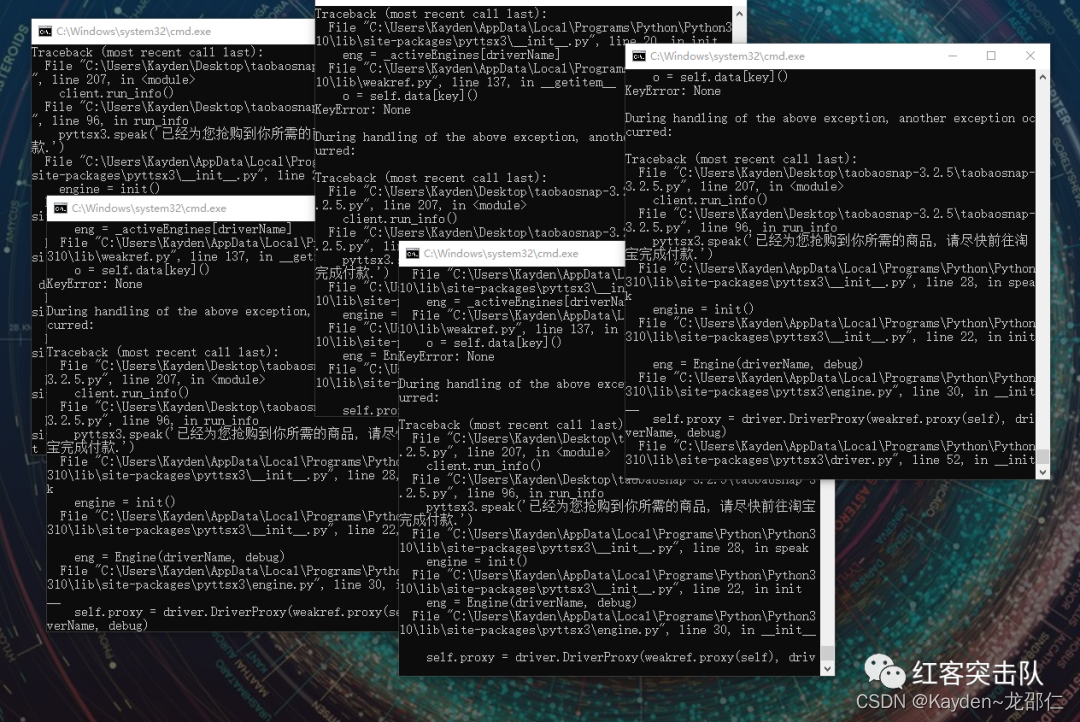
测试截图
(以下非抢购时间测试截图,已测试其他商品可成功提交订单)

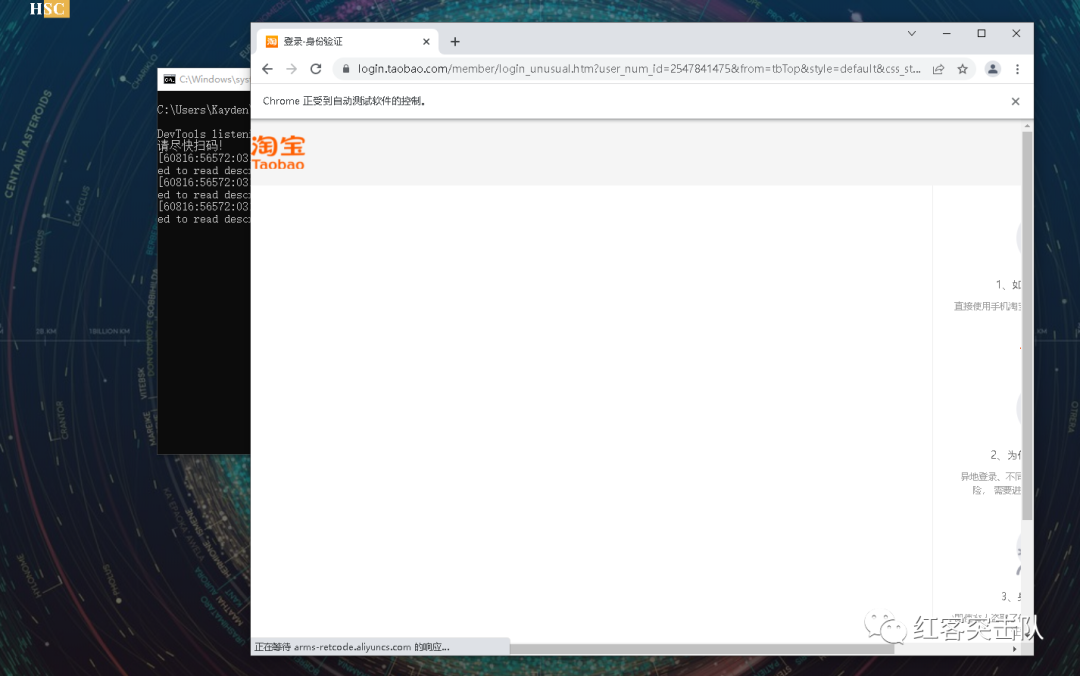
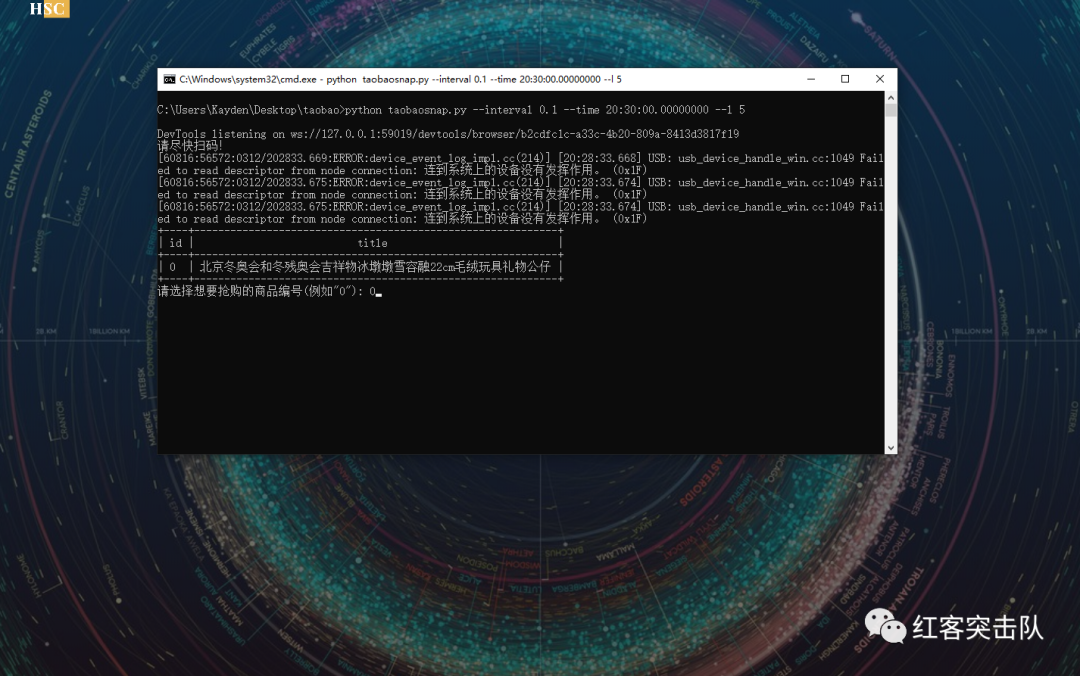
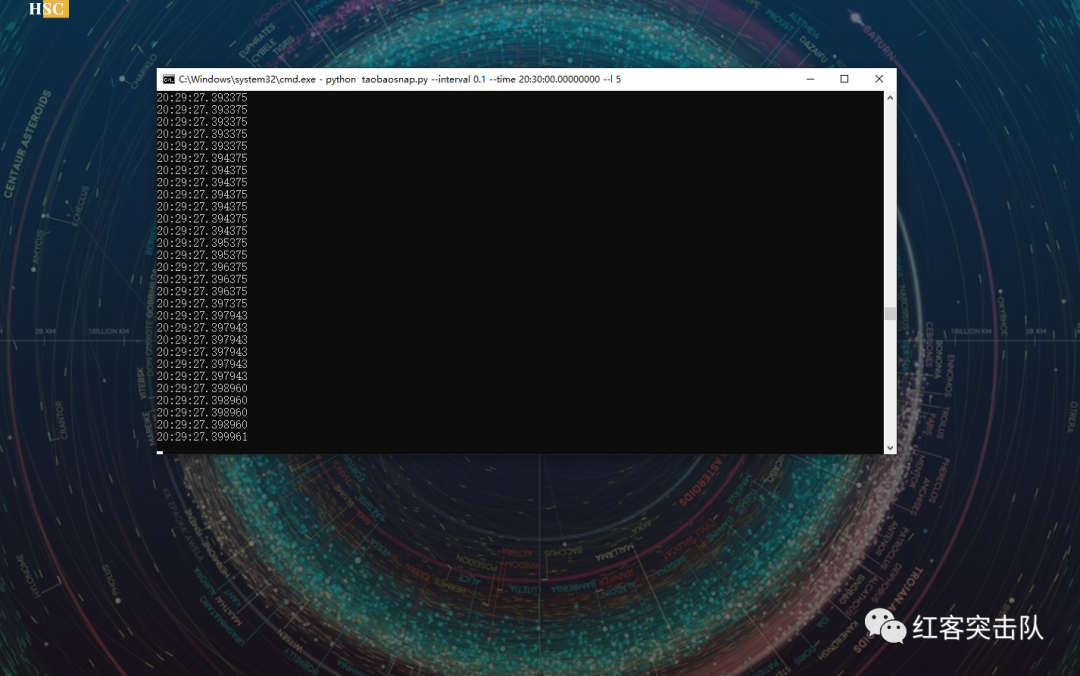
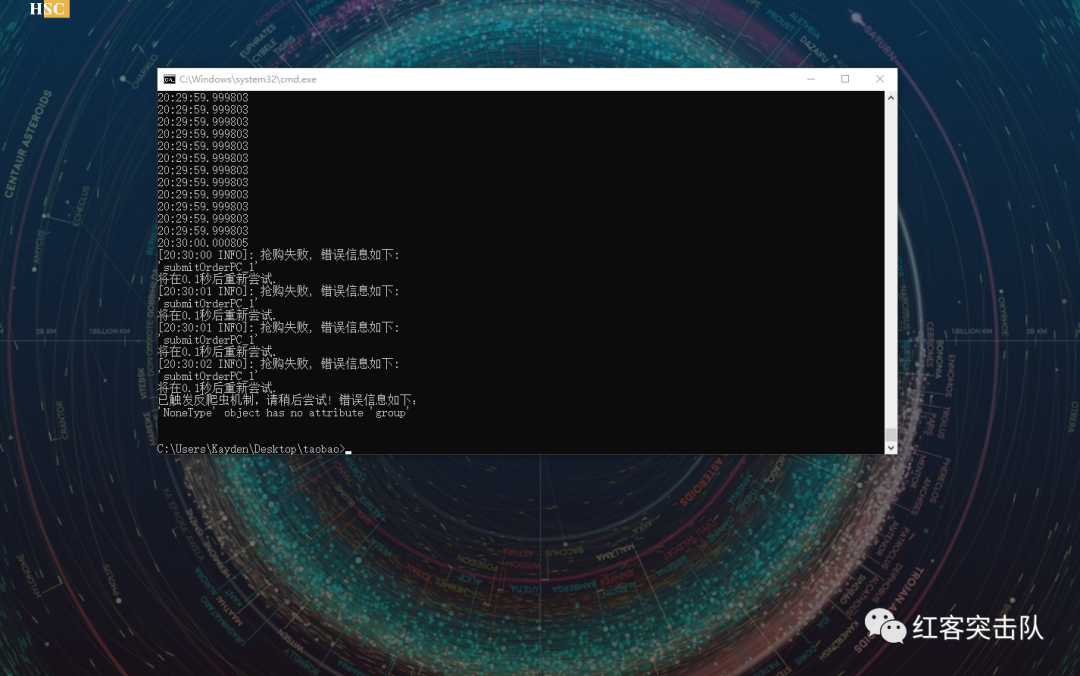
3.13,战队队长使用本程序成功抢购十三个,明天试试抢茅台吧
如何获取
Taobaosnap 发行版可从以下位置获得
1 https://kaydenlsr.coding.net/public/taobaosnap/taobaosnap/git/files
Taobaosnap 应该在任何支持python的平台上运行
1 Python (http://www.python.org)
注意:有关注意事项,请参阅以下链接中的指南
1 https://kaydenlsr.coding.net/public/taobaosnap/taobaosnap/git/files/master/readme.md
注意:此方案目前不兼容linux系统和mac系统(目前已开发version=3.2.5支持linux系统,大家可自行git上项目查看)
依赖
必要的驱动
1 chromedriver
python依赖库
1 -requests
2 -urllib
3 -pyttsx3
4 -prettytable
5 -argparse
6 -selenium
获取
github
1 https://github.com/kaydenlsr/taobaosnap
coding
1 https://kaydenlsr.coding.net/public/taobaosnap/taobaosnap/git/files
项目各版本使用方法均于readme.md作描述。可以在项目中查看描述文件,或于往期推文阅读使用方法。
其他因素
- 代码运行速度
- 网络延时
- 网络发包速度
- 越点路由数量
使用建议
- 将抢购开始时间设置为开始前约0.1秒,抢购时间间隔设置为0.1秒,抢购次数设置为五次。
- 系统时间与标准网络时间校对。
- 使用前约十分钟登录账号,设置好后等待读秒即可。
关于项目
开源项目已发行五个版本。
version=1.0.5使用requests的方式完成抢购。
version=2.0.3 使用selenium模块与webdriver调用完成抢购。
version=3.1.5 使用selenium模块与webdriver调用完成登录,使用requests的方式完成抢购。
version=3.2.5 简化了3.1.5版本的的操作。
version=3.3.5 适用于linux的方案。
项目作者
spmonkey
K龙
特别鸣谢
Charles
版本(Version)
Last update 2022.3.12 by K龙 version=3.2.5
免责声明
本项目为开源项目旨在互相学习。禁止违反法律法规使用本程序。因使用本程序造成的任何后果或相关规定,作者概不负责。
某宝抢购taobaosnap开发与实现的更多相关文章
- TortoiseSVN安装以及淘宝 TAE SDK 开发环境的搭建
一.TortoiseSVN 的下载和安装 1.进入TortoiseSVN 官网下载地址http://tortoisesvn.net/downloads.html,根据自己的操作系统位数下载相应最新版本 ...
- 淘宝web前端开发岗面试经历及感悟
今天下午四点接到淘宝UED的面试电话,很突然,很激动.现在怀着淡淡的忧伤为之文以志一下. 1.自我介绍一下. 我xx时候毕业,在xx公司任xx职务,主要负责xx balabala.(怕公司同事听到,接 ...
- 淘宝店铺模板开发SDK2.0下载安装图文教程
使用TortoiseSVN Checkout TAE SDK2.0 废话少说,切入主题: 1.在http://tortoisesvn.net/downloads.html上下载TortoiseSVN ...
- (转)从P1到P7——我在淘宝这7年
(一) 2011-12-08 [原文链接] 今天有同事恭喜我,我才知道自己在淘宝已经七周年了.很多人第一句话就是七年痒不痒,老实说,也曾经痒过,但往往都是一痒而过,又投入到水深火热的工作中去.回家之后 ...
- Android无线开发的几种常用技术(阿里巴巴资深工程师原创分享)
完整的开发一个android移动App需要经过从分解需求.架构设计到开发调试.测试.上线发布等多个阶段,在发布后还会有产品功能上的迭代演进,此外还会面对性能.安全.无线网络质量等多方面的问题. 移动A ...
- TP开发小技巧
TP开发小技巧原文地址http://wp.chenyuanzhao.com/wp/2016/07/23/tp%E5%BC%80%E5%8F%91%E5%B0%8F%E6%8A%80%E5%B7%A7/ ...
- 淘宝API学习之道:淘宝API相关了解
淘宝API开发平台,经过两年多的升级一系列动作,提供的api接口日渐稳定.看到淘宝api开发的浏览量还是较大,但那会写的DEMO如今已不能执行,淘宝改了链接地址,改了加密算法,为了不让大家浪费时间,特 ...
- 从P1到P7——我在淘宝这7年(转)
作者: 赵超 发布时间: 2012-02-25 14:47 阅读: 114607 次 推荐: 153 [收藏] (一) 2011-12-08 [原文链接] 今天有同事恭喜我,我才知道自己在淘 ...
- 【Android 应用开发】GitHub 优秀的 Android 开源项目
原文地址为http://www.trinea.cn/android/android-open-source-projects-view/,作者Trinea 主要介绍那些不错个性化的View,包括Lis ...
随机推荐
- 2022-7-9 第五小组 潘堂智 html学习笔记
什么是 HTML? HTML 是用来描述网页的一种语言. HTML 指的是超文本标记语言 (Hyper Text Markup Language) HTML 不是一种编程语言,而是一种标记语言 (ma ...
- HashSet存储自定义数据类型和LinkedHashSet集合
HashSet存储自定义数据类型 public class Test{ /** * HashSet存储自定义数据类型 * set集合保证元素唯一:存储的元素(String,Integer,Studen ...
- [RCTF2015]EasySQL-1|SQL注入
1.打开之后只有登录和注册两个功能,界面如下: 2.随便注册一个账户并进行登录,(注册admin时显示该账户已存在,考虑到是不是要获取到admin账户),发现可以进行改密操作,结果如下: 3.抓取各个 ...
- python主动杀死线程
简介 在一些项目中,为了防止影响主进程都会在执行一些耗时动作时采取多线程的方式,但是在开启线程后往往我们会需要快速的停止某个线程的动作,因此就需要进行强杀线程,下面将介绍两种杀死线程的方式. 直接强杀 ...
- 一款性价比很高的PLC网关如何采集西门子PLC到Thingsboard
PLC转MQTT网关金鸽BL100 西门子S7-200smart对接thingsboardBL102是一款采集西门子.三菱.欧姆龙.台达.AB.施耐德等各种PLC数据转换为Modbus TCP.OPC ...
- Swift高仿iOS网易云音乐Moya+RxSwift+Kingfisher+MVC+MVVM
效果 列文章目录 因为目录比较多,每次更新这里比较麻烦,所以推荐点击到主页,然后查看iOS Swift云音乐专栏. 目简介 这是一个使用Swift(还有OC版本)语言,从0开发一个iOS平台,接近企业 ...
- Vs 快捷键---探索不一样的编程
前言:现在很多工具都支持各式各样的快捷键,vs作为后起之秀,多功能的快捷键自然是必不可少的, 而且针对单行操作的快捷键是无需选中整行的,只需要光标停留在所操作的代码上面即可. 1.注释:CTRL+K+ ...
- spring实体类(POJO)参数的赋值(form表单)原理
10.实体类(POJO)参数的赋值(form表单)原理 10.1.原理解析 测试用例 准备好两个实体类 public class Person { private String name; priva ...
- 我与Apache DolphinScheduler的成长之路
关于 Apache DolphinScheduler社区 Apache DolphinScheduler(incubator) 于17年在易观数科立项,19年3月开源, 19 年8月进入Apache ...
- javaScript 事件循环机制
JavaScript是单线程的编程语言,只能同一时间内做一件事.但是在遇到异步事件的时候,js线程并没有阻塞,还会继续执行,这就是因为JS有事件循环机制. 事件循环流程总结 主线程开始执行一段代码, ...