Beats:为 Beats => Logstash => Elasticsearch 架构创建 template 及 Dashboard
文章转载自:https://elasticstack.blog.csdn.net/article/details/115341977
前一段时间有一个开发者私信我说自己的 Beats 连接到 Logstash,然后连接到 Elasticsearch。等数据在 Elasticsearch 中收集完后,发现 Kibana 中的 Dashboard 不能被使用。数据类型不匹配。这个到底是什么原因呢?
我们可以通过如下的三种路径把数据导入到 Elasticsearch 中:
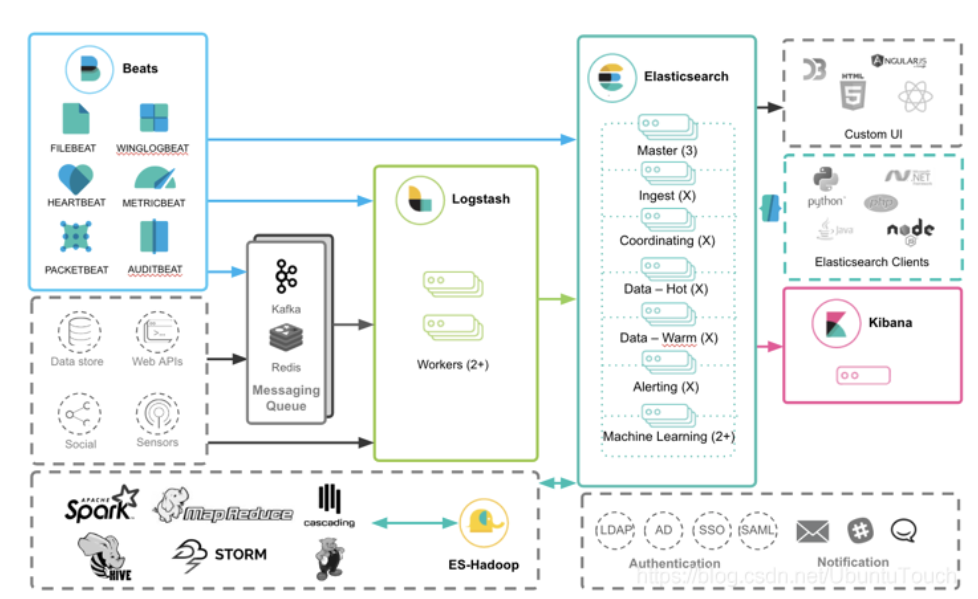
- Beats ==> Elasticsearch
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
在 Beats 的模块启动中,我们通常采用 setup 来进行导入index template, ingest pipeline,ILM policy 及 Dashboard。非常需要注意的一点是:如果你没有一个 index template,那么等 Elasticsearch 收集第一个数据,它就会按照自己默认的方式为你的数据创建一个 mapping。这个也就是在 Elasticsearch 中常说的 schemaless,但是在很多的情况下这个并不是最优的 mapping。当我们使用 Beats 导入的 Dashboard,它适合于使用 setup 命令而导入的 index template 所定义的数据类型。当我们使用 Beats 时,我们最重要的一点就是先执行 setup,而后再导入数据。
然而对于如下的两种输入方式:
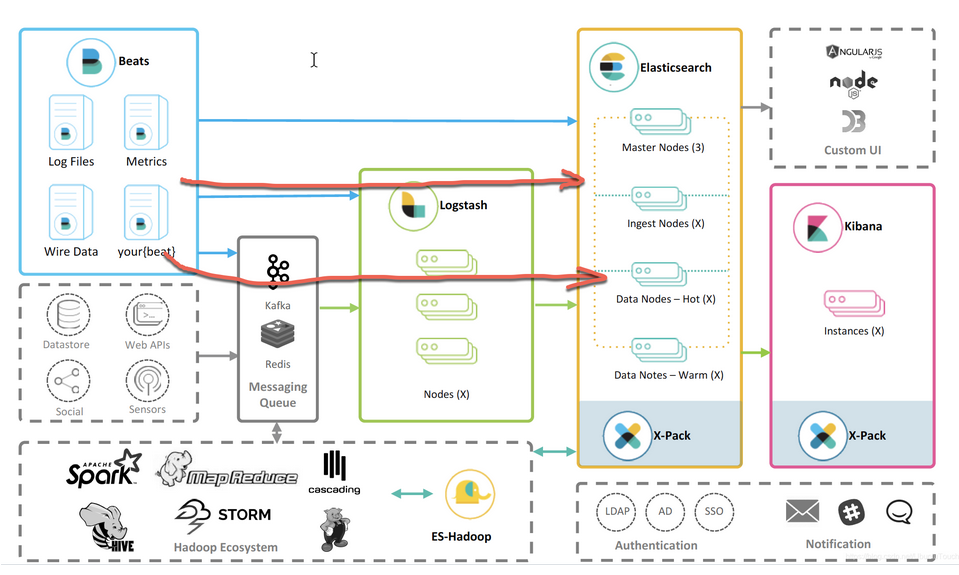
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
由于我们的 Beats 并不是直接连接到 Elasticsearch。在执行 setup 时,它并不能起到作用。那么我们该怎么办呢?
对上面的两种情况,我们需要首先按照如下的方式配置 Beats:
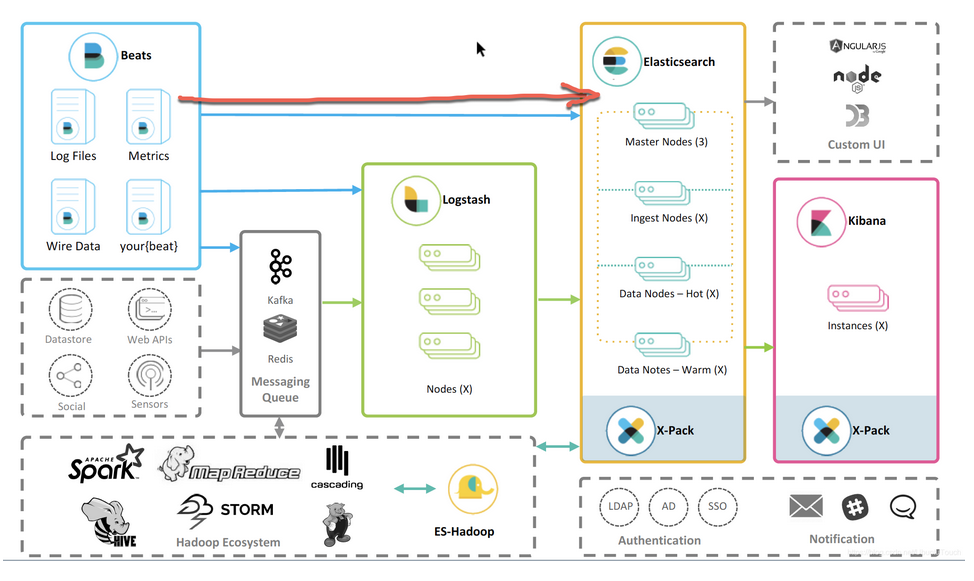
也就是:
- Beats ==> Elasticsearch
当我们执行完 setup 命令之后,我们就创建好了相应的 index template,index pattern, ILM policy 以及 Dashboard 等。这个过程我们可以称之为 Bootstrap。然后,当我们导入数据的时候,我们按照之前的连接方式导入数据,也就是:
- Beats ==> Logstash ==> Elasticsearch
- Beats ==> Kafka ==> Logstash ==> Elasticsearch
值得注意的是:setup 针对任何的 Beats,只需要运行一次就可以了。这样导入的数据,它完全可以使用之前的 Dashboard 进行展示。
Beats:为 Beats => Logstash => Elasticsearch 架构创建 template 及 Dashboard的更多相关文章
- Filebeat+Logstash+Elasticsearch测试
安装配置好三个软件使之能够正常启动,下面开始测试. 第一步 elasticsearch提供了restful api,这些api会非常便利,为了方便查看,可以使用postman调用接口. 1.查看Ela ...
- filebeat + logstash + elasticsearch + granfa
filebeat + logstash + elasticsearch + granfa https://www.cnblogs.com/wenchengxiaopenyou/p/9034213.ht ...
- filebeat -> logstash -> elasticsearch -> kibana ELK 日志收集搭建
Filebeat 安装参考 http://blog.csdn.net/kk185800961/article/details/54579376 elasticsearch 安装参考http://blo ...
- Nginx filebeat+logstash+Elasticsearch+kibana实现nginx日志图形化展示
filebeat+logstash+Elasticsearch+kibana实现nginx日志图形化展示 by:授客 QQ:1033553122 测试环境 Win7 64 CentOS-7- ...
- 安装logstash,elasticsearch,kibana三件套
logstash,elasticsearch,kibana三件套 elk是指logstash,elasticsearch,kibana三件套,这三件套可以组成日志分析和监控工具 注意: 关于安装文档, ...
- 使用logstash+elasticsearch+kibana快速搭建日志平台
日志的分析和监控在系统开发中占非常重要的地位,系统越复杂,日志的分析和监控就越重要,常见的需求有: * 根据关键字查询日志详情 * 监控系统的运行状况 * 统计分析,比如接口的调用次数.执行时间.成功 ...
- 安装logstash,elasticsearch,kibana三件套(转)
logstash,elasticsearch,kibana三件套 elk是指logstash,elasticsearch,kibana三件套,这三件套可以组成日志分析和监控工具 注意: 关于安装文档, ...
- logstash+elasticsearch+kibana快速搭建日志平台
使用logstash+elasticsearch+kibana快速搭建日志平台 日志的分析和监控在系统开发中占非常重要的地位,系统越复杂,日志的分析和监控就越重要,常见的需求有: 根据关键字查询日 ...
- 【转载】使用logstash+elasticsearch+kibana快速搭建日志平台
原文链接:http://www.cnblogs.com/buzzlight/p/logstash_elasticsearch_kibana_log.html 日志的分析和监控在系统开发中占非常重要的地 ...
随机推荐
- 05 MySQL_主键约束
主键约束 主键: 用于表示数据唯一性的字段称为主键: 约束:就是对表字段添加限制条件 主键约束:保证主键字段的值唯一且非空: - 格式 : create table t1(id int primary ...
- 聊一聊 C# 后台GC 到底是怎么回事?
一:背景 写这一篇的目的主要是因为.NET领域内几本关于阐述GC方面的书,都是纯理论,所以懂得人自然懂,不懂得人也没法亲自验证,这一篇我就用 windbg + 源码 让大家眼见为实. 二:为什么要引入 ...
- 【Unity基础知识】认识常用的生命周期函数(Awake、Start、Update...)
一.了解帧的概念 游戏的本质就是一个死循环 每一次循环都会处理游戏逻辑 并 更新一次游戏画面 之所以能看到画面在动 是因为 切换画面速度达到一定速度时 人眼就会认为画面是动态且流畅的 一帧就是执行了一 ...
- 序列化和返序列化的概述和对象的序列化流ObjectOutputStream
序列化和返序列化的概述 对象的序列化流ObjectOutputStream Person类: package com.yang.Test.ObjectStreamStudy; import java. ...
- HTML基础标签学习
HTML基础学习 前言 HTML基础学习会由HTML基础标签学习.HTML表单学习和一张思维导图总结HTML基础三篇文章构成,文章中博主会提取出重点常用的知识和经常出现的bug,提高学习的效率,后续会 ...
- YII的lazy loading
版本1 require('class\class1.php'); require('class\class1.php'); if($is_girl){ echo 'this is a girl'; $ ...
- 游戏开发常遇到数据一致性BUG,怎么解?
摘要:数据副本强一致.全节点可写.存储全面降本,GaussDB(for Redis)重新定义游戏数据库,彻底修复一致性BUG. 本文分享自华为云社区<华为云GaussDB(for Redis)揭 ...
- SQL Server查询优化
从上至下优化 看过一篇文章,印象深刻,里面将数据库查询优化分为四个大的方向 使用钞能力--给DB服务器加物理配置,内存啊,CPU啊,硬盘啊,全上顶配 替换存储系统--根据实际的业务情况选择不同的存储数 ...
- 客户流失?来看看大厂如何基于spark+机器学习构建千万数据规模上的用户留存模型 ⛵
作者:韩信子@ShowMeAI 大数据技术 ◉ 技能提升系列:https://www.showmeai.tech/tutorials/84 行业名企应用系列:https://www.showmeai. ...
- iommu分析之---DMA remap框架实现
本文主要介绍iommu的框架.基于4.19.204内核 IOMMU核心框架是管理IOMMU设备的一个通过框架,IOMMU设备通过实现特定的回调函数并将自身注册到IOMMU核心框架中,以此通过IOMMU ...