C语言之走迷宫深度和广度优先(利用堆栈和队列)

完成以下迷宫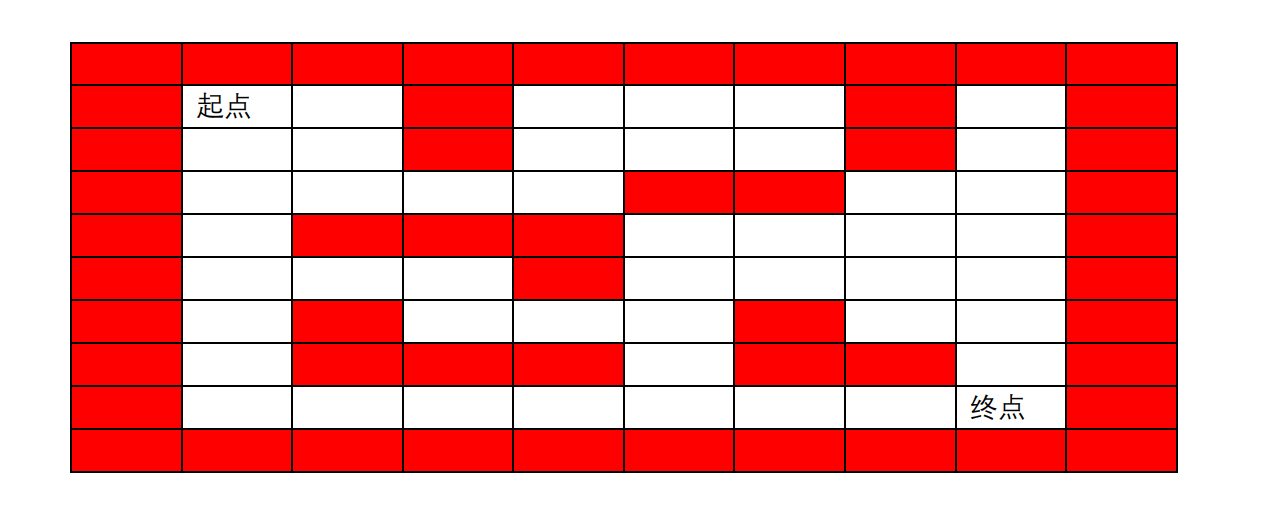
利用二维数组储存每一个数组里的值,若是不能走则为1,若是可行就是0,走过了就设为2。
一般是再复制一个数组,用来记录。
堆栈的思想就是将一个点的上下左右都遍历一遍,若可行进栈,跳出遍历,再寻找下一个可走的。若遇到无路可走的就退回上一步,就是出栈。所以就是说堆栈里记录的是可以走到终点的路。
队列的思想就是一直找,把所有可以走的路都走一遍,直到遇到终点。
这里的每一个可以走的点都为链表中的一个节点,在队列中要记录这个点的上一点是什么,就是哪一个点衍生出的这个点。
若是堆栈,最后在出栈便是所走的路径,但是堆栈是后进先出的原理,可能为了好看最后要做些处理。
若是队列,最后是利用找到的终点的那个节点,一直找这个节点的上一个节点,上个节点的上个节点,一直找到起点,可能为了好看最后还是要做些处理。
这里就是按照上述方法做的,但是太懒了,做出来就没有处理了。
堆栈是比较简单的,主要是队列中的头部和尾部的节点设置,和进队列的时候是怎么循环,这个循环是怎么在遍历之前的节点的也同时在加入新的节点进队。后来我是没有用出队这个原理去做。
以下是用堆栈实现的
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<time.h>
typedef struct stack{
int x;//记录下标
int y;
int direction;//记录方向
struct stack *next;
}stack;
int main(){
int maze[10][10];
int i,j;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if(i==0 || j==0 || i==9|| j==9){
maze[i][j]=1;
} else{
maze[i][j]=0;
}
}
}
maze[1][3]=1;
maze[1][7]=1;
maze[2][3]=1;
maze[2][7]=1;
maze[3][5]=1;
maze[3][6]=1;
maze[4][2]=1;
maze[4][3]=1;
maze[4][4]=1;
maze[5][4]=1;
maze[6][2]=1;
maze[6][6]=1;
maze[7][2]=1;
maze[7][3]=1;
maze[7][4]=1;
maze[7][6]=1;
maze[7][7]=1;
maze[8][1]=1;
//这里是输进去的迷宫,也可以随机实现,但是这里偷下懒
int cmaze[10][10];
for(i=0;i<10;i++){
for(j=0;j<10;j++){
cmaze[i][j]=maze[i][j];
}
}
//用一个新的二维数组记录走过的点
printf("\n\n");
stack *top,*p,*q,*t,*s;
top=(stack *)malloc(sizeof(stack));
top->next=NULL;
//人为设置的,(1,1)是起点,(8,8)是终点
int flag=0,x=0,y=0;
if(flag==0){
p=(stack *)malloc(sizeof(stack));
p->x=1;
p->y=1;
p->direction=-1;
q=top->next;
top->next=p;
p->next=q;
flag=1;
}
q=top->next;
x=q->x;
y=q->y;
while(q->x!=8 || q->y!=8){
//0:向左 y+1 1:向下 x+1 2:向右 y-1 3:向上 x+1
if(cmaze[x][y+1]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y+1;
p->direction=0;
q=top->next;
top->next=p;
p->next=q;
cmaze[x][y+1]=2;
}else if(cmaze[x+1][y]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x+1;
p->y=y;
p->direction=1;
q=top->next;
top->next=p;
p->next=q;
cmaze[x+1][y]=2;
}else if(cmaze[x][y-1]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y-1;
p->direction=2;
q=top->next;
top->next=p;
p->next=q;
cmaze[x][y-1]=2;
}else if(cmaze[x+1][y]==0){
p=(stack *)malloc(sizeof(stack));
p->x=x;
p->y=y-1;
p->direction=3;
q=top->next;
top->next=p;
p->next=q;
cmaze[x+1][y]=2;
}else{
t=top->next;
s=t->next;
top->next=s;
free(t);
}
q=top->next;
x=q->x;
y=q->y;
//每次都是栈顶的元素找方向,找不到就是free掉,出栈,就是后退一步
}
for(i=0;i<10;i++){
for(j=0;j<10;j++){
printf(" %d",cmaze[i][j]);
}
printf("\n");
}
printf("溯源:\n");
while(top->next!=NULL){
p=top->next;
x=p->x;
y=p->y;
printf("x=%d,y=%d\n",x,y);
top=top->next;
}
return 0;
}

//队列
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define maxsize 10
#define null 0
typedef struct node{
int x;
int y;
struct node*last;
struct node*next;
} lqnode;
typedef struct{
node *front,*rear;
}Queue;
//定义一个队列的结构体,记录头和尾
int main(){
int maze[10][10];
int i,j;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
if(i==0 || j==0 || i==9|| j==9){
maze[i][j]=1;
} else{
maze[i][j]=0;
}
}
}
maze[1][3]=1;
maze[1][7]=1;
maze[2][3]=1;
maze[2][7]=1;
maze[3][5]=1;
maze[3][6]=1;
maze[4][2]=1;
maze[4][3]=1;
maze[4][4]=1;
maze[5][4]=1;
maze[6][2]=1;
maze[6][6]=1;
maze[7][2]=1;
maze[7][3]=1;
maze[7][4]=1;
maze[7][6]=1;
maze[7][7]=1;
maze[8][1]=1;
for(i=0;i<10;i++){
for(j=0;j<10;j++){
printf(" %d",maze[i][j]);
}
printf("\n");
}
Queue *q;
lqnode *p;
q=(Queue *)malloc(sizeof(Queue));
p=(lqnode *)malloc(sizeof(lqnode));
p->next=null;
q->rear=p;
q->front=p;
int x,y;
lqnode *r,*t;
r=(lqnode *)malloc(sizeof(lqnode));
r->x=1;
r->y=1;
r->last=null;
q->rear->next=r;
r->next=null;
q->rear=r;
t=q->front->next;
x=t->x;
y=t->y;
printf("可以走的点\n");
while(x!=8 || y!=8){
if(maze[x][y+1]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x;
r->y=y+1;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x][y+1]=2;
}
if(maze[x+1][y]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x+1;
r->y=y;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x+1][y]=2;
}
if(maze[x][y-1]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x;
r->y=y-1;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x][y-1]=2;
}
if(maze[x+1][y]==0){
r=(lqnode *)malloc(sizeof(lqnode));
r->x=x+1;
r->y=y;
r->last=t;
q->rear->next=r;
r->next=null;
q->rear=r;
maze[x+1][y]=2;
}
//可以走的就加入队列,然后队列是从头开始循环的,一边循环一边加入了新元素
t=t->next;
x=t->x;
y=t->y;
printf("%d,%d\n",x,y);
}
printf("溯源:\n");
while(t->last!=NULL){
printf("x=%d,y=%d\n",t->x,t->y);
t=t->last;
}
//用last记录每一个节点是由哪个节点走过来的
return 0;
}
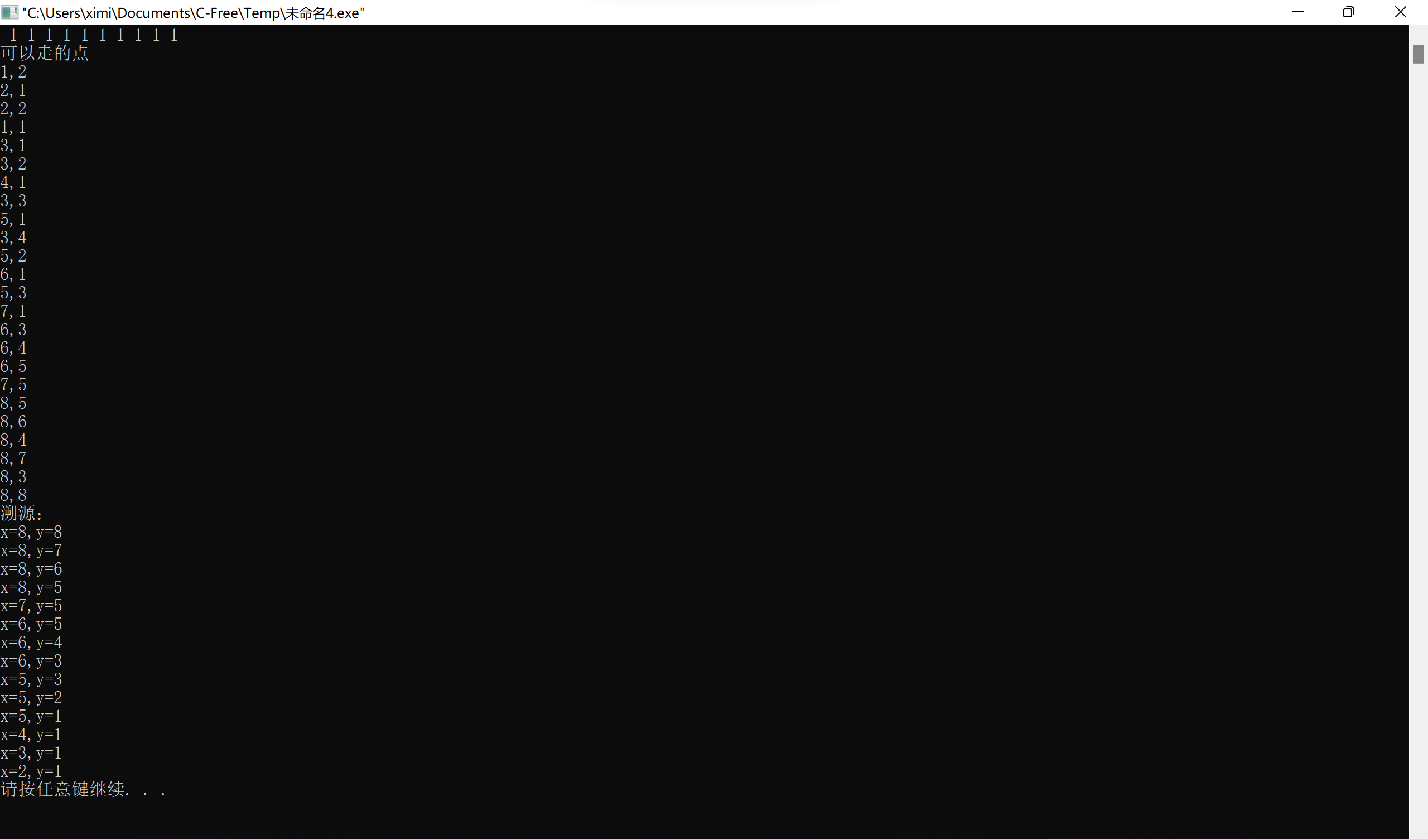
1 1 1 1 是上面的迷宫,截图没有截好
C语言之走迷宫深度和广度优先(利用堆栈和队列)的更多相关文章
- C语言动态走迷宫
曾经用C语言做过的动态走迷宫程序,先分享代码如下: 代码如下: //头文件 #include<stdio.h> #include<windows.h>//Sleep(500)函 ...
- golang 实现广度优先算法(走迷宫)
maze.go package main import ( "fmt" "os" ) /** * 广度优先算法 */ /** * 从文件中读取数据 */ fun ...
- golang广度优先算法-走迷宫
广度优先遍历,走迷宫思路: 1.创建二维数组,0表示是路,1表示是墙:创建队列Q,存储可遍历的点,Q的第一个元素为起始点 2.从队列中取一个点,开始,按上.左.下.右的顺序遍历周围的点next,nex ...
- 数据结构之 栈与队列--- 走迷宫(深度搜索dfs)
走迷宫 Time Limit: 1000MS Memory limit: 65536K 题目描述 一个由n * m 个格子组成的迷宫,起点是(1, 1), 终点是(n, m),每次可以向上下左右四个方 ...
- LeetCode 79,这道走迷宫问题为什么不能用宽搜呢?
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是LeetCode专题第48篇文章,我们一起来看看LeetCode当中的第79题,搜索单词(Word Search). 这一题官方给的难 ...
- sdut 2449走迷宫【最简单的dfs应用】
走迷宫 Time Limit: 1000ms Memory limit: 65536K 有疑问?点这里^_ 题目描述 一个由n * m 个格子组成的迷宫,起点是(1, 1), 终点是(n, m) ...
- 洛谷P1238 走迷宫
洛谷1238 走迷宫 题目描述 有一个m*n格的迷宫(表示有m行.n列),其中有可走的也有不可走的,如果用1表示可以走,0表示不可以走,文件读入这m*n个数据和起始点.结束点(起始点和结束点都是用两个 ...
- BZOJ 2707: [SDOI2012]走迷宫( tarjan + 高斯消元 )
数据范围太大不能直接高斯消元, tarjan缩点然后按拓扑逆序对每个强连通分量高斯消元就可以了. E(u) = 1 + Σ E(v) / degree(u) 对拍时发现网上2个程序的INF判断和我不一 ...
- NYOJ306 走迷宫(dfs+二分搜索)
题目描写叙述 http://acm.nyist.net/JudgeOnline/problem.php?pid=306 Dr.Kong设计的机器人卡多非常爱玩.它经常偷偷跑出实验室,在某个游乐场玩之不 ...
随机推荐
- 别无分号只此一家,Python3接入支付宝身份认证接口( alipay.user.certify)体系(2021年最新攻略)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_184 目前国内身份认证体系做的比较不错的大抵就是支付宝和微信两家了,支付宝的身份验证基于支付宝app的实人认证能力,采用多因子认证 ...
- odoo 14 一些常见问题集
1 # 当你往tree或者form视图中增加action的时候 2 # 记住!千万别重名 3 # 一旦重名,Export.Delete.Archive.Unarchive都会消失不见 4 # tree ...
- RocketMQ 详解系列
什么是RocketMQ RocketMQ作为一款纯java.分布式.队列模型的开源消息中间件,支持事务消息.顺序消息.批量消息.定时消息.消息回溯等.主要功能是异步解耦和流量削峰:. 常见的MQ主要有 ...
- js--自定义对象
1.直接量对象(JSON) {"name":"zhangsan","age":25} {}代表一个对象,包含多组键值对. 通常key是字符串 ...
- SpringBoot多重属性文件配置方案笔记
SpringBoot多重属性文件配置方案笔记 需要重写PropertyPlaceholderConfigurer 同时要忽略DataSourceAutoConfiguration @SpringBoo ...
- 【读书笔记】C#高级编程 第二十五章 事务处理
(一)简介 事务的主要特征是,任务要么全部完成,要么都不完成. (二)概述 事务由事务管理器来管理和协调.每个影响事务结果的资源都由一个资源管理器来管理.事务管理器与资源管理器通信,以定义事务的结果. ...
- 微软出品自动化神器Playwright,不用写一行代码(Playwright+Java)系列(一) 之 环境搭建及脚本录制
一.前言 半年前,偶然在视频号刷到某机构正在直播讲解Playwright框架的使用,就看了一会,感觉还不错,便被种草,就想着自己有时间也可以自己学一下,这一想着就半年多过去了. 读到这,你可能就去百度 ...
- Markdown学习 .md学习
# Markdown学习## 标题## 二级标题### 三级标题#### 四级标题## 字体**两个*是粗体***一个是斜体****三个是斜体加粗***~~两个~是删除线~~## 引用>走向人生 ...
- 后缀自动机(SAM)+广义后缀自动机(GSA)
经过一顿操作之后竟然疑似没退役0 0 你是XCPC选手吗?我觉得我是! 稍微补一点之前丢给队友的知识吧,除了数论以外都可以看看,为Dhaka和新队伍做点准备... 不错的零基础教程见 IO WIKI ...
- C# 中的那些锁,在内核态都是怎么保证同步的?
一:背景 1. 讲故事 其实这个问题是前段时间有位朋友咨询我的,由于问题说的比较泛,不便作答,但想想梳理一下还是能回答一些的,这篇就来聊一聊下面这几个锁. Interlocked AutoResetE ...