Java 序列化的缺点
Java 提供的对象输入流(ObjectInputStream)和输出流(ObjectOutputStream),可以直接把 Java 对象作为可存储的字节数据写入文件,也可以传输到网络上。对于程序员来说,基于 JDK 默认的序列化机制可以避免操作底层的字节数组,从而提高开发效率。Java 序列化的主要目的是网络传输和对象持久化。
一、无法跨语言
无法跨语言,是 Java 序列化最致命的问题。对于跨进程的服务调用,服务提供者可能是 Java 意外的其他语言,当我们需要和异构语言交互时,Java 序列化就难以胜任
由于 Java 序列化技术是 Java 语言内部的私有协议,其他语言并不支持,对于用户来说它完全是个黑盒子。对于 Java 序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用。
事实上,目前几乎所有流行的 Java RCP 通信框架,都没有使用 Java 序列化作为编解码框架,原因就在于它无法跨语言,而这些 RPC 框架往往需要支持跨语言调用。
二、序列化后的码流太大
【1】通过一个实例看下 Java 序列化后的字节数组大小。如下 UserInfo 对象是实现了序列化接口的对象,并生成了默认的序列号:serialVersionUID = 1L。说明 UserInfo 对象可以通过 JDK 默认的序列化机制进行序列化和反序列化。并创建了一个与之比较码流大小的方法 codeC ,此方法基于 ByteBuffer 的通用二进制编解码技术对 UserInfo 对象进行编码,编码结果也是 byte 数组。
【序列化 ID 问题】:两个客户端 A 和 B 试图通过网络传递对象数据,A 端将对象 C 序列化为二进制数据再传给 B,B 反序列化得到 C。
问题:C 对象的全类路径假设为 com.yintong.UserInfo,在 A 和 B 端都有这么一个类文件,功能代码完全一致。也都实现了 Serializable 接口,但是反序列化时总是提示不成功。
解决:虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID = 1L)。清单 1 中,虽然两个类的功能代码完全一致,但是序列化 ID 不同,他们无法相互序列化和反序列化。
1 //实现了序列化接口的实例
2 public class UserInfo implements Serializable{
3
4 private static final long serialVersionUID = 1L;
5
6 //用户ID
7 private int ID;
8 //用户名
9 private String name;
10
11 //有参构造器
12 public UserInfo(int iD, String name) {
13 super();
14 ID = iD;
15 this.name = name;
16 }
17
18 //根据 buffer缓冲区 获取字节数组
19 public byte[] codeC() {
20 //定义字节缓冲区
21 ByteBuffer buffer = ByteBuffer.allocate(1024);
22 //获取name属性的二进制字节流
23 byte[] value = this.name.getBytes();
24 //用于写入 int 值的相对 put 方法(可选操作)。
25 //将 n 个包含给定 int 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 n。
26 buffer.putInt(value.length);
27 //存入 二进制值
28 buffer.put(value);
29
30 //写入一个int值=ID到ByteBuffer中。
31 buffer.putInt(this.ID);
32 //切换为读
33 buffer.flip();
34 value = null;
35 //remaining 返回剩余的可用长度,次长度为实际读取的数据长度
36 byte[] result = new byte[buffer.remaining()];
37 //获取buffer中的值到 result
38 buffer.get(result);
39 return result;
40 }
41
42 public int getID() {
43 return ID;
44 }
45
46 public void setID(int iD) {
47 ID = iD;
48 }
49
50 public String getName() {
51 return name;
52 }
53
54 public void setName(String name) {
55 this.name = name;
56 }
57 }
【2】下面是测试程序,先调用两种编码接口对 UserInfo 进行编码,然后分别打印两者编码后的流大小进行对比。
1 public class TestUserInfo {
2
3 public static void main(String[] args) throws Exception {
4 UserInfo info = new UserInfo(101, "zheng zhao xiang");
5 //JDK 序列化流程
6 ByteArrayOutputStream bos = new ByteArrayOutputStream();
7 ObjectOutputStream oos = new ObjectOutputStream(bos);
8 oos.writeObject(info);
9 oos.flush();
10 oos.close();
11 byte[] b = bos.toByteArray();
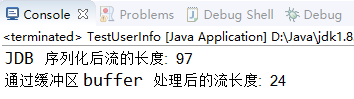
12 System.out.println("JDB 序列化后流的长度: "+b.length);
13 bos.close();
14 System.out.println("通过缓冲区 buffer 处理后的流长度: "+info.codeC().length);
15 }
16 }
【3】测试结果如下:采用 JDK 序列化机制编码后的二进制数组大小是通过缓冲区处理后的 4 倍。

三、序列化性能太低
【1】下面从序列化的性能角度看下 JDK 的表现如何。将之前的例子进行修改。对 UserInfo 中的 codeC 方法改造如下:
1 public byte[] codeC(ByteBuffer buffer) {
2 //清空缓冲区
3 buffer.clear();
4 //获取name属性的二进制字节流
5 byte[] value = this.name.getBytes();
6 //用于写入 int 值的相对 put 方法(可选操作)。
7 //将 n 个包含给定 int 值的字节按照当前的字节顺序写入到此缓冲区的当前位置,然后将该位置增加 n。
8 buffer.putInt(value.length);
9 //存入 二进制值
10 buffer.put(value);
11
12 //写入一个int值=ID到ByteBuffer中。
13 buffer.putInt(this.ID);
14 //切换为读
15 buffer.flip();
16 value = null;
17 //remaining 返回剩余的可用长度,次长度为实际读取的数据长度
18 byte[] result = new byte[buffer.remaining()];
19 //获取buffer中的值到 result
20 buffer.get(result);
21 return result;
22 }
【2】对 Java 序列化和二进制编码分别进行性能测试,编码 100万次,然后统计消耗的总时间:
1 public class PerformTestUserInfo {
2 public static void main(String[] args) throws IOException {
3 UserInfo info = new UserInfo(101, "zheng zhao xiang");
4 //循环次数
5 //JDK 序列化流程
6 ByteArrayOutputStream bos = null;
7 int loop = 1000000;
8 ObjectOutputStream oos = null;
9 //写之前获取系统时间
10 long startTimeMillis = System.currentTimeMillis();
11 for(int i=0; i<loop; i++) {
12 bos = new ByteArrayOutputStream();
13 oos = new ObjectOutputStream(bos);
14 oos.writeObject(info);
15 oos.flush();
16 oos.close();
17 byte[] b = bos.toByteArray();
18 bos.close();
19 }
20 long endTimeMillis = System.currentTimeMillis();
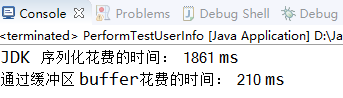
21 System.out.println("JDK 序列化花费的时间: "+(endTimeMillis - startTimeMillis)+" ms");
22
23 ByteBuffer buffer = ByteBuffer.allocate(1024);
24 startTimeMillis = System.currentTimeMillis();
25 for(int i=0; i<loop; i++) {
26 info.codeC(buffer);
27 }
28 endTimeMillis = System.currentTimeMillis();
29 System.out.println("通过缓冲区 buffer花费的时间: "+(endTimeMillis - startTimeMillis)+" ms");
30 }
31 }
【3】结果展示:结果非常令人惊讶,Java 序列化的性能只有二进制编码的 11% 左右,可见原生序列化的性能很差。
四、结论
无论是序列化后的码流大小,还是序列化的性能,JDK 默认的序列化机制表现都很差。因此,我们通常不会选择 Java 序列化作为远程跨节点调用的编解码框架。而是使用业界提供的很多优秀的编解码框架,它们在克服了 JDK 默认的序列化框架缺点的基础上,还增加了很多亮点。例如:Google 的 Protobuf、Facebook 的 Thrift 和 JBoss 的 Marshalling 等等,我后期都会学习和整理相关的博文。

----架构师资料,关注公众号获取----
Java 序列化的缺点的更多相关文章
- java序列化框架(protobuf、thrift、kryo、fst、fastjson、Jackson、gson、hessian)性能对比
我们为什么要序列化 举个栗子:下雨天我们要打伞,但是之后我们要把伞折叠起来,方便我们存放.那么运用到我们java中道理是一样的,我们要将数据分解成字节流,以便存储在文件中或在网络上传输,这叫序列 ...
- 各种Java序列化性能比较
转载:http://www.jdon.com/concurrent/serialization.html 这里比较Java对象序列化 XML JSON Kryo POF等序列化性能比较. 很多人以 ...
- Java序列化的几种方式以及序列化的作用
Java序列化的几种方式以及序列化的作用 本文着重讲解一下Java序列化的相关内容. 如果对Java序列化感兴趣的同学可以研究一下. 一.Java序列化的作用 有的时候我们想要把一个Java对象 ...
- [java]序列化框架性能对比(kryo、hessian、java、protostuff)
序列化框架性能对比(kryo.hessian.java.protostuff) 简介: 优点 缺点 Kryo 速度快,序列化后体积小 跨语言支持较复杂 Hessian 默认支持跨语言 较慢 Pro ...
- Java序列化技术
Java序列化与反序列化是什么?为什么需要序列化与反序列化?如何实现Java序列化与反序列化? Java序列化是指把Java对象转换为字节序列的过程:而Java反序列化是指把字节序列恢复为Java对象 ...
- java序列化测试
0.前言 本文主要对几种常见Java序列化方式进行实现.包括Java原生以流的方法进行的序列化.Json序列化.FastJson序列化.Protobuff序列化. 1.Java原生序列化 Java原生 ...
- 浅析若干Java序列化工具【转】
在Java中socket传输数据时,数据类型往往比较难选择.可能要考虑带宽.跨语言.版本的兼容等问题.比较常见的做法有: 采用java对象的序列化和反序列化 把对象包装成JSON字符串传输 Googl ...
- Java序列化的几种方式
本文着重解说一下Java序列化的相关内容. 假设对Java序列化感兴趣的同学能够研究一下. 一.Java序列化的作用 有的时候我们想要把一个Java对象变成字节流的形式传出去,有的时候我们想要从 ...
- 【转】几种Java序列化方式的实现
0.前言 本文主要对几种常见Java序列化方式进行实现.包括Java原生以流的方法进行的序列化.Json序列化.FastJson序列化.Protobuff序列化. 1.Java原生序列化 Java原生 ...
- (记录)Jedis存放对象和读取对象--Java序列化与反序列化
一.理论分析 在学习Redis中的Jedis这一部分的时候,要使用到Protostuff(Protobuf的Java客户端)这一序列化工具.一开始看到序列化这些字眼的时候,感觉到一头雾水.于是,参考了 ...
随机推荐
- SpringBoot项目启动
SpringBoot项目与其他项目启动方式有些不同. 查看是否是SpringBoot项目,可以查看在项目的pom.xml中是否有引入SpringBoot: 上图中就是对应的spring-boot.若有 ...
- Python 的入门学习之 Day4~6 ——from”夜曲编程“
Day 4 time: 2021.8.1. 打卡第四天.今天起得很早(7点多一些),很棒,而梳头发更快些就更好了.我也算渐渐养成了晨间学习的习惯吧,一起床就心心念念着Python课程,这让我感觉到了生 ...
- 高级纹理以及复杂而真实的应用——ShaderCp10
--20.9.7 这章主要分成三个部分 立方体纹理(cubemap) 渲染纹理(RenderTexture,rt) 和程序纹理 一.立方体纹理 立方体纹理顾名思义是一种三维的纹理形状类似于立方体,由六 ...
- (论文笔记)Learning Deep Structured Semantic Models for Web Search using Clickthrough Data
利用点击数据学习web搜索的深度学习模型 [总结] 该模型可以得到query和item的低维度向量表示,也可以得到二者的余弦语义相似度. 学习过程是通过最大化后验概率的极大似然估计得到的参数. ...
- Linux_Shell脚本
Shell脚本 shell基础 shell变量 shell扩展 shell基础 shell简介 1.什么是shell? shell是一种命令解释器 shell也是一种编程语言 shell,python ...
- 学习JavaScript第一周
三种输出方式,console.log.element.write.alert(): 简单数据类型:数值型.字符串型.布尔类型.undefined.null 复杂数据类型:对象 数据类型的转换:字符串转 ...
- html页面间传递参数
$.query.get("id") jquery.params.js代码 /** * jQuery.query - Query String Modification and Cr ...
- 『教程』mariadb的主从复制
一.MariaDB简介 MariaDB数据库的主从复制方案,是其自带的功能,并且主从复制并不是复制磁盘上的数据库文件,而是通过binlog日志复制到需要同步的从服务器上. MariaDB数据库支持单向 ...
- Flask-Migrate数据库模型映射
1.Flask-Migrate介绍 flask-migrate可以十分方便的进行数据库的迁移与映射,将我们修改过的ORM模型映射到数据库中.flask-migrate是基于Alembic进行的一个封装 ...
- idea的tomcat控制台输出乱码
tomcat乱码问题 idea的tomcat控制台输出乱码 找到自己的安装目录 用vscode打开 ctrl+f打开搜索 输入encoding 最后一个是用来给idea中的控制台输出 --->改 ...