[深度学习] imgaug边界框增强笔记
imgaug边界框增强笔记主要是讲述基于imgaug库对目标检测图像的边界框进行图像增强。本文需要掌握imgaug库的基本使用,imgaug库的基本使用见[深度学习] imgaug库使用笔记。
文章目录
0 示例图像和标注文件
示例图像如图所示

# 对应的标注文件
!cat demo.xml
<?xml version="1.0" ?>
<annotation>
<folder>demo</folder>
<filename>demo.jpg</filename>
<path>demo.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>640</width>
<height>424</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>187</xmin>
<ymin>93</ymin>
<xmax>276</xmax>
<ymax>378</ymax>
</bndbox>
</object>
<object>
<name>horse</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>390</xmin>
<ymin>138</ymin>
<xmax>602</xmax>
<ymax>345</ymax>
</bndbox>
</object>
<object>
<name>dog</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>61</xmin>
<ymin>256</ymin>
<xmax>207</xmax>
<ymax>348</ymax>
</bndbox>
</object>
</annotation>
1 imgaug加载图像和标注数据
标注文件的数据信息需要从外部读取后放入imgaug的BoundingBox类中,本文标注文件的数据信息通过BeautifulSoup读取。BeautifulSoup学习文章见使用 Beautiful Soup。具体代码如下。
from bs4 import BeautifulSoup
import imgaug as ia
import imageio
from imgaug.augmentables.bbs import BoundingBox, BoundingBoxesOnImage
from imgaug import augmenters as iaa
# 打开标注文件
soup = BeautifulSoup(open('demo.xml'),"lxml")
# 导入图像
image = imageio.imread("demo.jpg")
# 用于存放标注文件边界框信息
bbsOnImg=[]
# 找到所有包含框选目标的节点
for objects in soup.find_all(name="object"):
# 获得当前边界框的分类名
object_name = str(objects.find(name="name").string)
# 提取坐标点信息
xmin = int(objects.xmin.string)
ymin = int(objects.ymin.string)
xmax = int(objects.xmax.string)
ymax = int(objects.ymax.string)
# 保存该边界框的信息
bbsOnImg.append(BoundingBox(x1=xmin, x2=xmax, y1=ymin, y2=ymax,label=object_name))
# 初始化imgaug的标选框数据
bbs = BoundingBoxesOnImage( bbsOnImg,shape=image.shape)
# 展示结果
ia.imshow(bbs.draw_on_image(image, size=2))

2 边界框增强
imgaug中的边界框增强有两种办法,一种是对整张图像增强,另外一种是根据边界框信息,图像部分区域增强。
2.1 整张图像增强
直接对整张图像进行增强,直接从imgaug增强效果示例中找示例代码,然后添加到iaa.Sequential()中叠加就可以实现图像增强。
# 增强效果
seq = iaa.Sequential([
iaa.GammaContrast(1.5),
iaa.Fliplr(1),
iaa.Cutout(fill_mode="constant", cval=255),
iaa.CoarseDropout(0.02, size_percent=0.15, per_channel=0.5),
])
# 输入增强前的图像和边框,得到增强后的图像和边框
image_aug, bbs_aug = seq(image=image, bounding_boxes=bbs)
# 可视化,size边框的宽度
ia.imshow(bbs_aug.draw_on_image(image_aug, size=2))

2.2 图像部分区域增强
imgaug可以只对边界框框选区域或者除边界框的区域进行图像增强,通过imgaug的BlendAlphaBoundingBoxes类实现。BlendAlphaBoundingBoxes类的接口说明如下:
classimgaug.augmenters.blend.BlendAlphaBoundingBoxes(labels, foreground=None, background=None, nb_sample_labels=None, seed=None, name=None, random_state='deprecated', deterministic='deprecated')
该类的常用参数为labels,foreground,background。labels表示对哪一类或哪几类的边界框进行处理,为None表示所有标签都处理。foreground设置对labels标注的边界框区域增强效果。background设置对除边界库区域增强效果。示例代码如下:
# demo1
seq = iaa.Sequential([
# background设置除了dog和person标选框之外的区域都涂黑
iaa.BlendAlphaBoundingBoxes(['dog','person'],background=iaa.Multiply(0.0)),
# 对整张图进行增强
#iaa.Cartoon()
])
# 输入增强前的图像和边框,得到增强后的图像和边框
image_aug, bbs_aug = seq(image=image, bounding_boxes=bbs)
# 可视化,size边框的宽度
ia.imshow(bbs_aug.draw_on_image(image_aug, size=2))

# demo2
seq = iaa.Sequential([
# label=None表示不选择特定标签,即对所以标签进行处理
iaa.BlendAlphaBoundingBoxes(None,foreground=iaa.Fog())
])
# 输入增强前的图像和边框,得到增强后的图像和边框
image_aug, bbs_aug = seq(image=image, bounding_boxes=bbs)
# 可视化,size边框的宽度
ia.imshow(bbs_aug.draw_on_image(image_aug, size=2))

# demo3
seq = iaa.Sequential([
# 前后景分别处理
iaa.BlendAlphaBoundingBoxes(["dog","person"],foreground=iaa.Fog(),background=iaa.Cartoon()),
# 整张图片增强效果
iaa.Fliplr(1)
])
# 输入增强前的图像和边框,得到增强后的图像和边框
image_aug, bbs_aug = seq(image=image, bounding_boxes=bbs)
# 可视化,size边框的宽度
ia.imshow(bbs_aug.draw_on_image(image_aug, size=2))
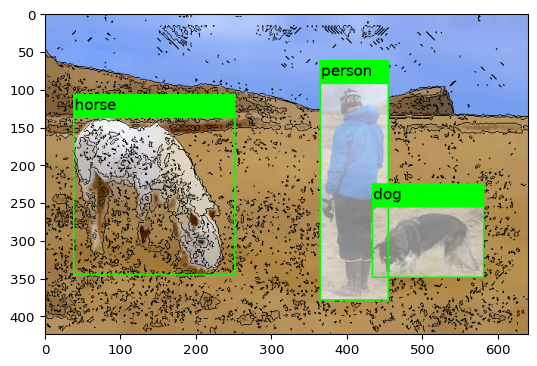
2.3 边界框超出图像范围解决办法
在[深度学习] imgaug库使用笔记中有提到不要图像旋转来增强边界框,很容易出现边界框超出图像范围,在imgaug中也提供了相应的解决办法, 通过clip_out_of_image函数即可解决。尽管这样,还是不建议使用图像旋转增强边界框。
seq = iaa.Sequential([
iaa.Affine(rotate=80)
])
# 输入增强前的图像和边框,得到增强后的图像和边框
image_aug, bbs_aug = seq(image=image, bounding_boxes=bbs)
# 可视化,size边框的宽度
ia.imshow(bbs_aug.draw_on_image(image_aug, size=2))
# 显示边界框结果,可以看到dog和horse的边界框范围超过图像。
bbs_aug

BoundingBoxesOnImage([BoundingBox(x1=133.4267, y1=60.3564, x2=429.5516, y2=197.4940, label=person), BoundingBox(x1=201.1759, y1=268.0866, x2=441.8446, y2=512.8110, label=horse), BoundingBox(x1=141.0913, y1=-35.4247, x2=257.0462, y2=124.3329, label=dog)], shape=(424, 640, 3))
# 删除超过图像范围的边界框范围
bbs_aug_clip =bbs_aug.clip_out_of_image()
# 可视化
ia.imshow(bbs_aug_clip.draw_on_image(image_aug, size=2))
bbs_aug_clip

BoundingBoxesOnImage([BoundingBox(x1=133.4267, y1=60.3564, x2=429.5516, y2=197.4940, label=person), BoundingBox(x1=201.1759, y1=268.0866, x2=441.8446, y2=424.0000, label=horse), BoundingBox(x1=141.0913, y1=0.0000, x2=257.0462, y2=124.3329, label=dog)], shape=(424, 640, 3))
3 保存增强图像和标注文件
xml标注文件保存参考python如何读取&生成voc xml格式标注信息。可自行修改相关代码。本文保存代码如下。
# xml文件生成代码
from lxml import etree
# ---- 创建标注
class CreateAnnotations:
# ----- 初始化
def __init__(self, flodername, filename):
self.root = etree.Element("annotation")
child1 = etree.SubElement(self.root, "folder")
child1.text = flodername
child2 = etree.SubElement(self.root, "filename")
child2.text = filename
child3 = etree.SubElement(self.root, "path")
child3.text = filename
child4 = etree.SubElement(self.root, "source")
child5 = etree.SubElement(child4, "database")
child5.text = "Unknown"
# ----- 设置size
def set_size(self, imgshape):
(height, witdh, channel) = imgshape
size = etree.SubElement(self.root, "size")
widthn = etree.SubElement(size, "width")
widthn.text = str(witdh)
heightn = etree.SubElement(size, "height")
heightn.text = str(height)
channeln = etree.SubElement(size, "depth")
channeln.text = str(channel)
# ----- 保存文件
def savefile(self, filename):
tree = etree.ElementTree(self.root)
tree.write(filename, pretty_print=True, xml_declaration=False, encoding='utf-8')
def add_pic_attr(self, label, xmin, ymin, xmax, ymax):
object = etree.SubElement(self.root, "object")
namen = etree.SubElement(object, "name")
namen.text = label
bndbox = etree.SubElement(object, "bndbox")
xminn = etree.SubElement(bndbox, "xmin")
xminn.text = str(xmin)
yminn = etree.SubElement(bndbox, "ymin")
yminn.text = str(ymin)
xmaxn = etree.SubElement(bndbox, "xmax")
xmaxn.text = str(xmax)
ymaxn = etree.SubElement(bndbox, "ymax")
ymaxn.text = str(ymax)
# 从imgaug中提取边界框信息并保存
foldername = "demo"
filename = "demo_aug.jpg"
# 创建保存类
anno = CreateAnnotations(foldername, filename)
#
anno.set_size(image_aug.shape)
# 循环提取
for index,bb in enumerate(bbs_aug_clip):
xmin = int(bb.x1)
ymin = int(bb.y1)
xmax = int(bb.x2)
ymax = int(bb.y2)
label = str(bb.label)
anno.add_pic_attr(label, xmin, ymin, xmax, ymax)
# 保存标注文件
anno.savefile("{}.xml".format(filename.split(".")[0]))
# 保存增强图像
imageio.imsave(filename, image_aug)
4 参考
[深度学习] imgaug边界框增强笔记的更多相关文章
- [深度学习] imgaug库使用笔记
imgaug是一款非常有用的python图像增强库,非常值得推荐应用于深度学习图像增强.其包含许多增强技术,支持图像分类,目标检测,语义分割,热图.关键点检测等一系列任务的图像增强.本文主要介绍img ...
- Coursera深度学习(DeepLearning.ai)编程题&笔记
因为是Jupyter Notebook的形式,所以不方便在博客中展示,具体可在我的github上查看. 第一章 Neural Network & DeepLearning week2 Logi ...
- deeplearning.ai 改善深层神经网络 week1 深度学习的实用层面 听课笔记
1. 应用机器学习是高度依赖迭代尝试的,不要指望一蹴而就,必须不断调参数看结果,根据结果再继续调参数. 2. 数据集分成训练集(training set).验证集(validation/develop ...
- deeplearning.ai 神经网络和深度学习 week4 深层神经网络 听课笔记
1. 计算深度神经网络的时候,尽量向量化数据,不要用for循环.唯一用for循环的地方是依次在每一层做计算. 2. 最常用的检查代码是否有错的方法是检查算法中矩阵的维度. 正向传播: 对于单个样本,第 ...
- 深度学习-Wasserstein GAN论文理解笔记
GAN存在问题 训练困难,G和D多次尝试没有稳定性,Loss无法知道能否优化,生成样本单一,改进方案靠暴力尝试 WGAN GAN的Loss函数选择不合适,使模型容易面临梯度消失,梯度不稳定,优化目标不 ...
- 深度学习-语言处理特征提取 Word2Vec笔记
Word2Vec的主要目的适用于词的特征提取,然后我们就可以用LSTM等神经网络对这些特征进行训练. 由于机器学习无法直接对文本信息进行有效的处理,机器学习只对数字,向量,多维数组敏感,所以在进行文本 ...
- 深度学习-生成对抗网络GAN笔记
生成对抗网络(GAN)由2个重要的部分构成: 生成器G(Generator):通过机器生成数据(大部分情况下是图像),目的是“骗过”判别器 判别器D(Discriminator):判断这张图像是真实的 ...
- 深度学习-DCGAN论文的理解笔记
训练方法DCGAN 的训练方法跟GAN 是一样的,分为以下三步: (1)for k steps:训练D 让式子[logD(x) + log(1 - D(G(z)) (G keeps still)]的值 ...
- 深度学习框架 Torch 7 问题笔记
深度学习框架 Torch 7 问题笔记 1. 尝试第一个 CNN 的 torch版本, 代码如下: -- We now have 5 steps left to do in training our ...
随机推荐
- 设计模式之观察者模式_C++
1 // ADBHelper.cpp : This file contains the 'main' function. Program execution begins and ends there ...
- ExceptionHandler配合RestControllerAdvice全局处理异常
Java全局处理异常 引言 对于controller中的代码,为了保证其稳定性,我们总会对每一个controller中的代码进行try-catch,但是由于接口太多,try-catch会显得太冗杂,s ...
- Oracle 同义词详解(synonym)
Oracle 同义词详解(synonym) 一.Oracle同义词概念 Oracle 数据库中提供了同义词管理的功能.同义词是数据库方案对象的一个别名,经常用于简化对象访问和提高对象访问的安全性.在使 ...
- 3.Task对象
Task对象 用于调度或并发协程对象 在事件循环中可以添加多个任务 创建task对象三种方式 创建task对象可以让协程加入事件循环中等待被调度执行 3.7版本之后加入asyncio.create ...
- 【性能测试】Loadrunner12.55(二)-飞机订票系统-脚本录制
1.1 飞机订票系统 Loadrunner 12.55不会自动安装飞机订票系统,要自己手动安装. 我们需要下载Web Tools以及一个小插件strawberry https://marketplac ...
- Python基础部分:1、typora软件和对计算机的认识
目录 一.typora软件 1.安装 2.markdown语法 二.计算机的本质 1.进制数 三.计算机五大组成部分概要 1.控制器 2.运算器 3.存储器 4.输入设备 5.输出设备 一.typor ...
- NC-日志配置及代码详解
目录 一.日志文件输出说明 二.日志配置说明 2.1 配置文件路径 2.2 配置格式 2.2.1 参数说明 三.代码说明 四.自定义日志实例 实例1-新建日志类 实例2-直接在代码中使用日志输出 五. ...
- DevOps | 企业内源(内部开源)适合什么样的公司
框架类是否适合企业内源? 框架类都由公司早期来的一些大佬们负责(相当于技术委员会),更新频率非常低.给框架类提MR的人,多数本身就在技术委员会. 如果公司的人员众多,类似BAT级别,几万人使用的框架, ...
- ES6高级编程(一)
一.JavaScript概要 1.1.JavaScript组成 JavaScript主要由三部分构成,分别是ECMAScript.DOM与BOM ECMAScript定义了该语言的语法.类型.语句.关 ...
- 4.mysql-进阶
1.事务 将多个操作步骤变成一个事务,任何一个步骤失败,则回滚到事务的所有步骤之前状态,大白话:要成功都成功:要失败都失败. 如转账操作,A扣钱.B收钱,必须两个步骤都成功,才认为转账成功 innod ...