ShardingSphere-proxy-5.0.0企业级分库分表、读写分离、负载均衡、雪花算法、取模算法整合(八)
一、简要说明
以下配置实现了:
1、分库分表
2、每一个分库的读写分离
3、读库负载均衡算法
4、雪花算法,生成唯一id
5、字段取模
二、配置项
#
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ######################################################################################################
#
# Here you can configure the rules for the proxy.
# This example is configuration of sharding rule.
#
######################################################################################################
#
#schemaName: sharding_db
#
#dataSources:
# ds_0:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_0
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
# ds_1:
# url: jdbc:postgresql://127.0.0.1:5432/demo_ds_1
# username: postgres
# password: postgres
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
#
#rules:
#- !SHARDING
# tables:
# t_order:
# actualDataNodes: ds_${0..1}.t_order_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_inline
# keyGenerateStrategy:
# column: order_id
# keyGeneratorName: snowflake
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: database_inline
# defaultTableStrategy:
# none:
#
# shardingAlgorithms:
# database_inline:
# type: INLINE
# props:
# algorithm-expression: ds_${user_id % 2}
# t_order_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_${order_id % 2}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
#
# keyGenerators:
# snowflake:
# type: SNOWFLAKE
# props:
# worker-id: 123 ######################################################################################################
#
# If you want to connect to MySQL, you should manually copy MySQL driver to lib directory.
#
###################################################################################################### # 连接mysql所使用的数据库名
schemaName: MyDb dataSources:
dsdatasources_0:
url: jdbc:mysql://127.0.0.1:3306/MyDb_0?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: mysql123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
dsdatasources_0_read0:
url: jdbc:mysql://192.168.140.132:3306/MyDb_0?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: Xiaohemiao_123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
dsdatasources_1:
url: jdbc:mysql://127.0.0.1:3306/MyDb_1?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: mysql123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
dsdatasources_1_read1:
url: jdbc:mysql://192.168.140.132:3306/MyDb_1?serverTimezone=UTC&useSSL=false
username: root # 数据库用户名
password: Xiaohemiao_123 # 登录密码
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
# ds_1:
# url: jdbc:mysql://127.0.0.1:3306/demo_ds_1?serverTimezone=UTC&useSSL=false
# username: root
# password:
# connectionTimeoutMilliseconds: 30000
# idleTimeoutMilliseconds: 60000
# maxLifetimeMilliseconds: 1800000
# maxPoolSize: 50
# minPoolSize: 1
#
# 规则
rules:
- !READWRITE_SPLITTING
dataSources:
pr_ds1:
writeDataSourceName: dsdatasources_0 #主库
readDataSourceNames:
- dsdatasources_0_read0 # 从库,如果有多个从库,就在下面写多个
loadBalancerName: loadBalancer_ROUND_ROBIN
pr_ds2:
writeDataSourceName: dsdatasources_1 #主库
readDataSourceNames:
- dsdatasources_1_read1 # 从库,如果有多个从库,就在下面写多个
loadBalancerName: loadBalancer_ROUND_ROBIN
loadBalancers: # 负载均衡算法配置
loadBalancer_ROUND_ROBIN: # 负载均衡算法名称,自定义
type: ROUND_ROBIN # 负载均衡算法,默认为轮询算法,还有加权算法和随机算法,可参考官网
- !SHARDING
tables:
t_product: #需要进行分表的表名
actualDataNodes: dsdatasources_${0..1}.t_product_${0..1} # 表达式,将表分为t_product_0 , t_product_1
tableStrategy: #分表策略
standard:
shardingColumn: product_id # 字段名
shardingAlgorithmName: t_product_MOD
databaseStrategy: # 分库策略
standard:
shardingColumn: product_id
shardingAlgorithmName: t_product_MOD
keyGenerateStrategy:
column: id
keyGeneratorName: snowflake #雪花算法
# t_order_item:
# actualDataNodes: ds_${0..1}.t_order_item_${0..1}
# tableStrategy:
# standard:
# shardingColumn: order_id
# shardingAlgorithmName: t_order_item_inline
# keyGenerateStrategy:
# column: order_item_id
# keyGeneratorName: snowflake
# bindingTables:
# - t_order,t_order_item
# defaultDatabaseStrategy:
# standard:
# shardingColumn: user_id
# shardingAlgorithmName: database_inline
# defaultTableStrategy:
# none:
#
shardingAlgorithms:
t_product_MOD: # 取模名称,可自定义
type: MOD # 取模算法
props:
sharding-count: 2 #分片数量,因为分了两个表,所以这里是2
# t_order_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_${order_id % 2}
# t_order_item_inline:
# type: INLINE
# props:
# algorithm-expression: t_order_item_${order_id % 2}
#
keyGenerators:
snowflake: # 雪花算法名称,自定义名称
type: SNOWFLAKE
props:
worker-id: 123
三、数据准备
-- 创建表
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0; -- ----------------------------
-- Table structure for t_product
-- ----------------------------
DROP TABLE IF EXISTS `t_product`;
CREATE TABLE `t_product` (
`id` varchar(225) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`product_id` int(11) NOT NULL,
`product_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
PRIMARY KEY (`id`, `product_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1; -- 插入表数据
INSERT INTO t_product(product_id,product_name) VALUES(1,'one');
INSERT INTO t_product(product_id,product_name) VALUES(2,'two');
INSERT INTO t_product(product_id,product_name) VALUES(3,'three');
INSERT INTO t_product(product_id,product_name) VALUES(4,'four');
INSERT INTO t_product(product_id,product_name) VALUES(5,'five');
INSERT INTO t_product(product_id,product_name) VALUES(6,'six');
INSERT INTO t_product(product_id,product_name) VALUES(7,'seven');
四、查看数据
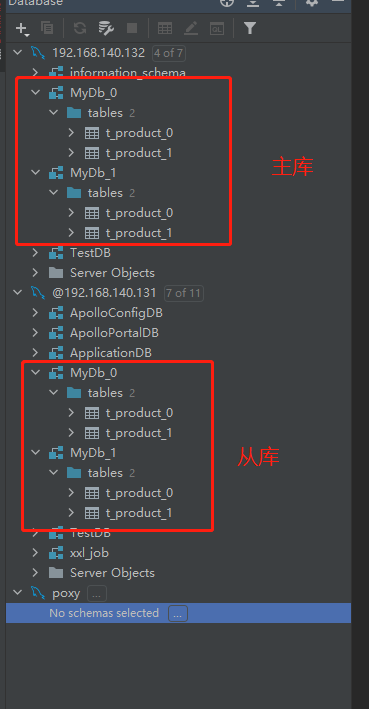

1、查看shardingsphere中间件t_product表数据
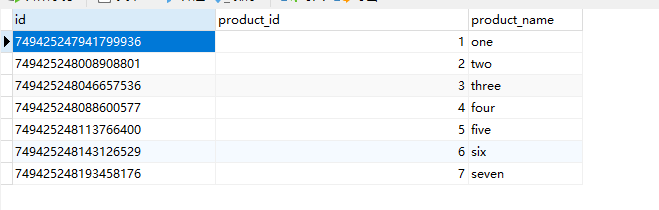
2、主库192.168.140.131数据

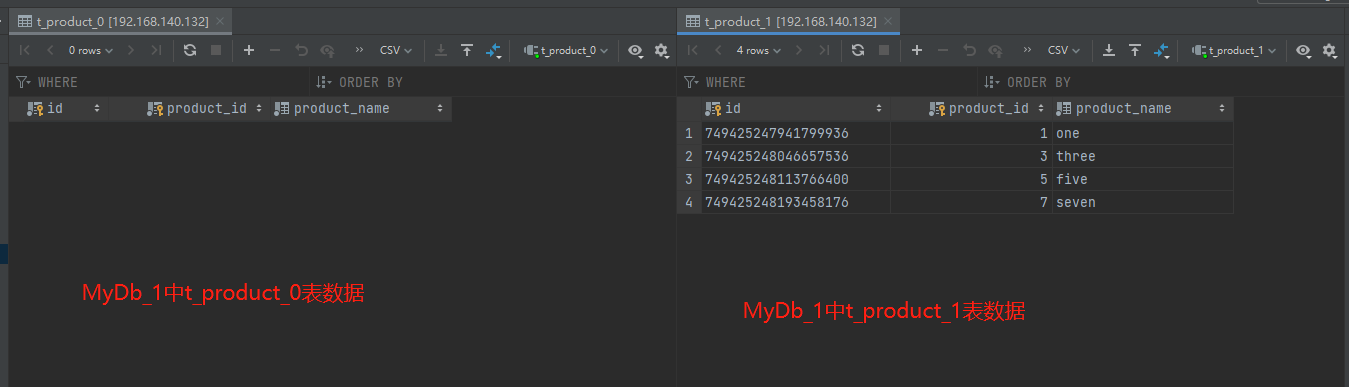
2、从库192.168.140.132数据
ShardingSphere-proxy-5.0.0企业级分库分表、读写分离、负载均衡、雪花算法、取模算法整合(八)的更多相关文章
- 分库分表(7)--- SpringBoot+ShardingSphere实现分库分表 + 读写分离
分库分表(7)--- ShardingSphere实现分库分表+读写分离 有关分库分表前面写了六篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理 ...
- DB层面上的设计 分库分表 读写分离 集群化 负载均衡
第1章 引言 随着互联网应用的广泛普及,海量数据的存储和访问成为了系统设计的瓶颈问题.对于一个大型的 互联网应用,每天几十亿的PV无疑对数据库造成了相当高的负载.对于系统的稳定性和扩展性造成了极大的 ...
- ShardingJdbc-分表;分库;分库分表;读写分离;一主多从+分表;一主多从+分库分表;公共表;数据脱敏;分布式事务
目录 创建项目 分表 导包 表结构 Yml 分库 Yml Java 分库分表 数据库 Yml 读写分离 数据库 Yml 其他 只请求主库 读写分离判断逻辑代码 一主多从+分表 Yml 一主多从+分库分 ...
- 一致性哈希算法(适用于分库分表、RPC负载均衡)转
在分布式应用中,应该来说使用到hash最多的地方就是rpc负载均衡和分库分表,通常对于正式意义上的分布式应用来说,扩容和收缩是一个半自动化的过程,在此期间,应用基本上是可用的,所以不能发生大规模动荡的 ...
- MySQL+MyCat分库分表 读写分离配置
一. MySQL+MyCat分库分表 1 MyCat简介 java编写的数据库中间件 Mycat运行环境需要JDK. Mycat是中间件.运行在代码应用和MySQL数据库之间的应用. 前身 : cor ...
- Windows环境下使用Mycat模拟分库分表-读写分离案例
一.基本环境 W7 64位.Mycat1.6.MySQL8.0 二.Mycat核心配置文件配置 解压Mycat1.6,并对server.xml.schema.xml.rule.xml三个核心配置文件做 ...
- 分库分表(6)--- SpringBoot+ShardingSphere实现分表+ 读写分离
分库分表(6)--- ShardingSphere实现分表+ 读写分离 有关分库分表前面写了五篇博客: 1.分库分表(1) --- 理论 2.分库分表(2) --- ShardingSphere(理论 ...
- dynamic + shardingsphere(4.1.1) 实现动态分库分表
1. 主要依赖: <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-da ...
- go分库分表 主从分离例子
网上有很多介绍分库分表的文章,方法很多: 分区表切分 垂直切分 水平切分 区间切分 取模切分 这里不细说 分库分表简单,但后期会带来一系列的难题: 事务 Join 分页 数据库: master和sla ...
随机推荐
- Java语言学习day06-7月05日
今日内容介绍流程控制语句之循环语句循环高级###10for循环_1 * A: for循环_1 * a: 使用格式 for(初始化变量 ; 条件 ; 增量){ 循环体; } * b: 各模块解释 初始化 ...
- Python paho-mqtt使用心得
一.概述 一)基本概念 使用回调处理从MQTT代理返回的数据,要使用回调需要先定义回调函数然后将其指派给客户端实例(client). 例如: # 定义一个回调函数 def on_connect(cli ...
- mmdetection获取最高map的epoch
自动从训练结果中获取最高的mAP所对应的epoch. <code>import json import os ''' :param work_dir 训练结果目录 :return 最好的m ...
- pgpool-II 4.3 中文手册-前言
什么是 Pgpool-II? Pgpool II 管理一个 PostgreSQL 服务器池,以实现单个 PostgreSQL 安装无法实现的一些功能.这些功能包括: 高可用 Pgpool-II 通过使 ...
- 【学习笔记】CDQ分治(等待填坑)
因为我对CDQ分治理解不深,所以这篇博客只是我现在的浅显理解有任何不对的,希望大佬指出. 首先就是CDQ分治适用的题型: (1)带修改,但修改互相独立 (2)必须允许离线 (3)解决数据结构的题,能把 ...
- react-router@6 版本初体验
最近使用了一下react-router@6 版本感觉有很大的改动,记录一下. React Router v6 makes heavy use of React hooks, so you'll nee ...
- Linux下的计划任务—crontab
点击上方"开源Linux",选择"设为星标" 回复"学习"获取独家整理的学习资料! 来自:Linux就该这么学 crond 是linux下用 ...
- 824. Goat Latin - LeetCode
Questioin 824. Goat Latin Solution 题目大意:根据要求翻译句子 思路:转换成单词数组,遍历数组,根据要求转换单词 Java实现: 用Java8的流实现,效率太低 pu ...
- Spark在Local环境下的使用
① 将 spark-3.0.0-bin-hadoop3.2.tgz 文件上传到 Linux (cd /opt/module路径下)并解压缩 ② 修改spark-3.0.0-bin-hado ...
- 记一次生产事故的排查与优化——Java服务假死
一.现象 在服务器上通过curl命令调用一个Java服务的查询接口,半天没有任何响应.关于该服务的基本功能如下: 1.该服务是一个后台刷新指示器的服务,即该服务会将用户需要的指示器数据提前计算好,放入 ...