SQL Server 查询分解
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/查询步骤
概述
查询步骤是很基础也挺重要的一部分,但是我还是在周围发现有些人虽然会语法,但是对于其中的步骤不是很清楚,这里就来分解一下其中的步骤,在技术内幕系列里面都会有讲到。
目录
流程图
(1)FROM <LEFT_TABLE> <JOIN_TYPE> JOIN <RIGHT_TABLE> ON <ON_PREDICATE>
|<LEFT_TABLE> <APPLY_TYPE> APPLY <RIGHT_TABLE_EXPRESSION> AS <alias>
|<LEFT_TABLE> pivot(<pivot_specification>) AS <alias>
|<LEFT_TABLE> UNPIVOT(<unpivot_specification>) AS <alias>
(2)WHERE<where_predicate>
(3)GROUP BY<group_by_specification>
(4)HAVING<having_predicate>
(5)SELECT <DISTINCT> <TOP> <select_list>
(6)ORDER BY<order_by_list>
步骤分解
测试数据
--创建测试表 --创建顾客表
CREATE TABLE Customers
(custid INT NOT NULL PRIMARY KEY,
city NVARCHAR(20) NOT NULL
)
go
INSERT INTO Customers VALUES(1,'深圳'),(2,'广州'),(3,'武汉'),(4,'上海'),(5,'北京') --创建订单表
CREATE TABLE Orders
(orderid INT NOT NULL PRIMARY KEY IDENTITY(1000,1),
custid INT NOT NULL,
orderdate DATETIME NOT NULL
)
GO
INSERT INTO Orders(custid,orderdate)values(1,'2013-10-1 00:00:00'),(1,'2013-10-2 00:00:00'),(1,'2013-10-3 00:00:00'),(1,'2013-10-4 00:00:00'),(2,'2013-10-1 00:00:00'),(2,'2013-10-3 00:00:00'),(2,'2013-10-5 00:00:00'),(3,'2013-10-3 00:00:00'),(3,'2013-10-7 00:00:00'),(4,'2013-10-1 00:00:00') --创建订单明细表
CREATE TABLE [OrderDetails](
[orderid] [int] NOT NULL,
[productid] [int] NOT NULL,
[unitprice] [money] NOT NULL,
[qty] [smallint] NOT NULL
CONSTRAINT [PK_OrderDetails] PRIMARY KEY CLUSTERED
(
[orderid] ASC,
[productid] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
INSERT INTO OrderDetails VALUES(1000,10,5.00,1),(1000,14,6.00,2),(1001,10,5.31,3),(1001,11,5.22,1),(1001,12,3.20,3),(1001,13,4.10,2),(1002,11,7.00,1),(1003,12,8.00,5),(1004,13,8.41,1),(1004,11,6.65,1),(1005,18,7.41,1),(1006,17,10.00,1)
--查询深圳、广州每一个顾客每笔金额大于10的订单,并按订单价格倒序排序
SELECT TA.custid,TB.orderid,SUM(tc.unitprice*tc.qty) AS price FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid LEFT JOIN OrderDetails TC ON TB.orderid=tc.orderid
WHERE TA.city IN('深圳','广州')
GROUP BY TA.custid,TB.orderid
HAVING SUM(tc.unitprice*tc.qty)>10
ORDER BY price DESC
第一步:FROM阶段
这一步是一个T-SQL语句的开始,一般紧接着FROM的这个表被称作左表,例如a inner join b inner join c,首先a作为左表然后关联b,a和b关联的结果作为下一个运算的左表关联c。在FROM阶段涉及的表运算会有JOIN(LEFT JOIN,RIGHT JOIN,FULL JOIN),APPLY(CROSS APPLY,OUTER APPLY),PIVOT,UNPIVOT
对于上面的查询例子:FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid的左连接的分解是这样的
第一步交叉连接、SELECT * FROM Customers TA CROSS JOIN Orders TB---首先进行交叉连接得到的行数是5*10=50行
第二步ON筛选、将TA.custid=TB.custid以外的结果排除,可以等价于SELECT * FROM Customers TA CROSS JOIN Orders TB WHERE TA.custid=TB.custid
第三步、将主表(左边的表)不在第二步的行加上,可以等价于 SELECT * FROM Customers TA CROSS JOIN Orders TB WHERE TA.custid=TB.custid union all SELECT * FROM Customers TA LEFT JOIN Orders TB ON TA.custid=TB.custid WHERE TB.custid IS NULL
所以其它几个表运算只要大家知道怎么使用就可以了,大家只要明白它在T-SQL语句中的位置就行。
这里要注意一点:大家理解了JEFT JOIN的原理之后就明白"on"筛选对查询的删除不是最终的,在上面的第三步会把主表的一些行又添加上来,所以我们有时候写LEFT JOIN的时候有的人不太明白为什么ON 后面加AND和把AND放在WHERE里面的得到的结果不一样,就是这个原理了,WHERE操作对查询的删除才是最终的。
第二步:WHERE阶段
当然后面的有些阶段都是可选的也就是有的查询不一定会用到,但是这里为了讲述整个过程,所以就一步一步的来讲,在FROM 阶段结束之后会生成一张虚拟表,进入第二阶段也就是WHERE阶段,在WHERE阶段是对前一阶段(FROM阶段)结果返回行进行筛选,例如上面的查询筛选城市是‘深圳’,‘广州’的顾客
所以为什么把select步骤里面生成的列写在where里面无法识别就是因为where在select操作之前。
第三步:GROUP BY阶段
GROUP BY 操作是分组操作,确保进行分组的属性集每一个组都是唯一的,GROUP BY 操作的数据是WHERE阶段筛选之后的数据,例如上面的查询例子是将custid,orderid作为一行来进行分组,上面的例子是每一个顾客每一笔订单的消费金额。
第四步:HAVING阶段
HAVING阶段是在GOUP BY 阶段返回TURE之后才会有这步操作,HAVING是对上一步的分组之后的数据进行筛选的步骤,例如筛选消费订单金额大于10的顾客订单
第五步:SELECT阶段
select阶段是返回上一步操作得到的虚拟表的数据列,所以也就是为什么存在group by的分组查询,select里面的列跟group by 的分组列需要一致的原因了,聚会函数生成的列除外,因为select查询的基础列就是来源于前面的步骤,select阶段会涉及到去重复distinct当然如果前面存在分组也就不存在重复了,TOP操作,还有一些字段之间的算法运算,子查询等等。
第六步:ORDER BY阶段
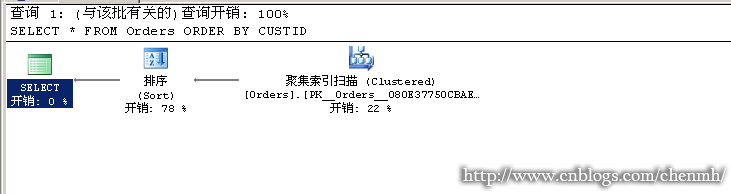
这一步是整个过程的最后一步操作,因为它在SELECT阶段之后,所以对于SELECT里面生成的字段别名在ORDER BY 中可以使用别名,对于一张表,表代表的是集合,集合是没有顺序的,当一个查询带有ORDER BY时我们可以把它理解成游标,游标是有特定的排序,所以为什么一个查询加上ORDER BY 操作之后会变的很慢了,因为它需要进行排序操作。
---当查询没有排序时
SELECT * FROM Orders
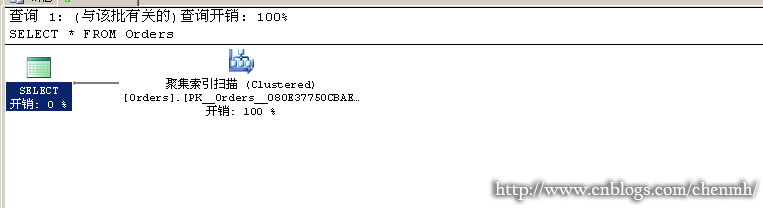
---当查询有排序时
SELECT * FROM Orders
ORDER BY CUSTID
TOP于ORDER BY的关系
order by 是保证结果排序顺序,top是一个逻辑运算操作
对于一个没有外部查询的语句,order by 操作既能保证结果根据制定条件的排序,又能满足TOP的逻辑运算(查询最小的三个orderid)
SELECT TOP (3) * FROM Orders
ORDER BY ORDERID
对于存在外部查询时,order by在作用仅仅是保证top的逻辑结果的正确输出,而不能保证查询结果的排序,虽然我们可能查询出的结果是按照这个方式排序。
---当不指定TOP时报错
SELECT * FROM(SELECT custid,orderid,orderdate FROM Orders ORDER BY orderdate DESC) AS A
---当指定
SELECT * FROM(SELECT TOP (3) custid,orderid,orderdate FROM Orders ORDER BY orderdate DESC) AS A
总结
理解完了整个查询的过程,也就能能理解为什么SQLServer这么耗内存了,每一步的操作都是生成一张虚拟表进入下一步操作,理解了整个查询过程 之后对我们理解T-SQL语法很有帮助,同时也有利于分析语句。
如果文章对大家有帮助,希望大家能给个赞,谢谢!!!
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |
SQL Server 查询分解的更多相关文章
- [转] 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- SQL SERVER 查询性能优化——分析事务与锁(五)
SQL SERVER 查询性能优化——分析事务与锁(一) SQL SERVER 查询性能优化——分析事务与锁(二) SQL SERVER 查询性能优化——分析事务与锁(三) 上接SQL SERVER ...
- SQL Server 查询性能优化 相关文章
来自: SQL Server 查询性能优化——堆表.碎片与索引(一) SQL Server 查询性能优化——堆表.碎片与索引(二) SQL Server 查询性能优化——覆盖索引(一) SQL Ser ...
- 利用SET STATISTICS IO和SET STATISTICS TIME 优化SQL Server查询性能
首先需要说明的是这篇文章的内容并不是如何调节SQL Server查询性能的(有关这方面的内容能写一本书),而是如何在SQL Server查询性能的调节中利用SET STATISTICS IO和SET ...
- 如何找出你性能最差的SQL Server查询
我经常会被反复问到这样的问题:”我有一个性能很差的SQL Server.我如何找出最差性能的查询?“.因此在今天的文章里会给你一些让你很容易找到问题答案的信息向导. 问SQL Server! SQL ...
- 使用WinDbg调试SQL Server查询
上一篇文章我给你介绍了WinDbg的入门,还有你如何能附加到SQL Server.今天的文章,我们继续往前一步,我会向你展示使用WinDbg调试SQL Server查询需要的步骤.听起来很有意思?我们 ...
- sql server 查询分析器消息栏里去掉“(5 行受影响)”
sql server 查询分析器消息栏里去掉"(5 行受影响)" 在你代码的开始部分加上这个命令: set nocount on 记住在代码结尾的地方再加上: set ...
- Sql Server查询性能优化之走出索引的误区
据了解绝大多数开发人员对于索引的理解都是一知半解,局限于大多数日常工作没有机会.也什么没有必要去关心.了解索引,实在哪天某个查询太慢了找到查询条件建个索引就ok,哪天又有个查询慢了,再建立个索引就是, ...
- SQL Server 查询分析器提供的所有键盘快捷方式(转)
下表列出 SQL Server 查询分析器提供的所有键盘快捷方式. 活动 快捷方式 书签:清除所有书签. CTRL-SHIFT-F2 书签:插入或删除书签(切换). CTRL+F2 书签:移动到下一个 ...
随机推荐
- 继承映射关系 TPH、TPT、TPC<EntityFramework6.0>
每个类型一张表[TPT] 声明方式 public class Business { [Key] public int BusinessId { get; protected set; } public ...
- C#运算符号
double x=5.1e3;// 5.1乘以10 的3次方. x就是 5100 //注 : 5.1e+3=5.1e3=5.1e03=5.1e+03 double y=5.1e-3;// 5.1乘以 ...
- CentOS 7 安装后没有ifconfig命令
/bin,/sbin,/usr/bin,/usr/sbin下面都没有ifconfig命令. 执行命令 yum install net-tools 即可.
- persistence.xml文件的妙处
在上家公司,经常要做的一个很麻烦的事就是写sql脚本, 修改了表结构,比如增加一个新字段的时候,都必须要写sql并放入指定目录中, 目的就是为了便于当我们把代码迁移到其他数据库中的时候,再来执行这些s ...
- linux 查看端口号
在使用Linux系统的过程中,有时候会遇到端口被占用而导致服务无法启动的情况.比如HTTP使用80端口,但当启动Apache时,却发现此端口正在使用. 这种情况大多数是由于软件冲突.或者默认端口设置不 ...
- (转) JAVA中如何设置图片(图标)自适应Jlable等组件的大小
一.问题: 一个程序,组件上设置某个图片作为图标,因为的label(应该说是组件)已经设定了固定大小, 所以再打开一些大图片时,超过组件大小的部分没显示出来,而小图片又没填充完整个组件 二.解决这个问 ...
- eclipse的maven项目,如何使用java run main函数
项目使用maven管理,一般说来就使用jetty:run了.但是对于做功能测试和集成测试的用例,需要使用自定义的quickrun来运行进行测试环境的参数设定和功能隔离,google一番发现maven有 ...
- "不能在 DropDownList 中选择多个项。"其解决办法及补充
探讨C#.NET下DropDownList的一个有趣的bug及其解决办法 摘要: 本文就C#.Net 环境下Web开发中经常使用的DropDownList控件的SelectedIndex属性进行了详细 ...
- unity 改变场景
public class GameManager : MonoBehaviour { public void OnStartGame(int sceneName) { SceneManager.Loa ...
- c、c++ 常用函数记录
1.void* memcpy(char*dest, char*src, size_tnum) 将第二个参数拷贝到第一个参数,最后一个是长度. 2.void *memset(void *s, int ...