机器学习 scikit-learn 图谱
scikit-learn 是机器学习领域非常热门的一个开源库,基于Python 语言写成。可以免费使用。
网址: http://scikit-learn.org/stable/index.html
上面有很多的教程,编程实例。而且还做了很好的总结,下面这张图基本概括了传统机器学习领域的大多数理论与相关算法。
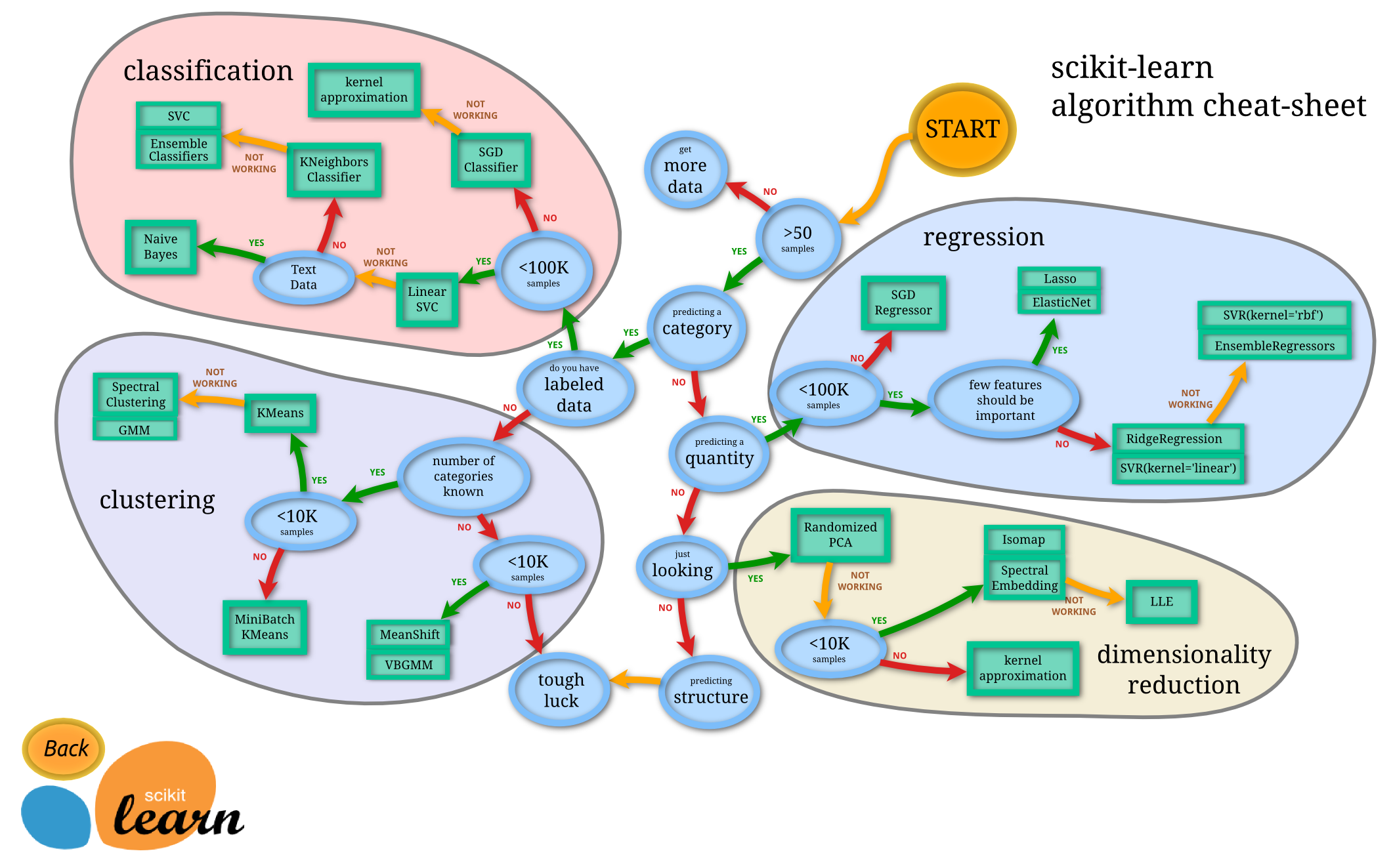
我们可以看到,机器学习分为四大块,分别是 classification (分类), clustering (聚类), regression (回归), dimensionality reduction (降维)。
给定一个样本特征 x, 我们希望预测其对应的属性值 y, 如果 y 是离散的, 那么这就是一个分类问题,反之,如果 y 是连续的实数, 这就是一个回归问题。
如果给定一组样本特征 S={x∈RD}, 我们没有对应的 y, 而是想发掘这组样本在 D 维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
如果我们想用维数更低的子空间来表示原来高维的特征空间, 那么这就是降维问题。
classification & regression
无论是分类还是回归,都是想建立一个预测模型 H,给定一个输入 x, 可以得到一个输出 y:
不同的只是在分类问题中, y 是离散的; 而在回归问题中 y 是连续的。所以总得来说,两种问题的学习算法都很类似。所以在这个图谱上,我们看到在分类问题中用到的学习算法,在回归问题中也能使用。分类问题最常用的学习算法包括 SVM (支持向量机) , SGD (随机梯度下降算法), Bayes (贝叶斯估计), Ensemble, KNN 等。而回归问题也能使用 SVR, SGD, Ensemble 等算法,以及其它线性回归算法。
clustering
聚类也是分析样本的属性, 有点类似classification, 不同的就是classification 在预测之前是知道 y 的范围, 或者说知道到底有几个类别, 而聚类是不知道属性的范围的。所以 classification 也常常被称为 supervised learning, 而clustering就被称为 unsupervised learning。
clustering 事先不知道样本的属性范围,只能凭借样本在特征空间的分布来分析样本的属性。这种问题一般更复杂。而常用的算法包括 k-means (K-均值), GMM (高斯混合模型) 等。
dimensionality reduction
降维是机器学习另一个重要的领域, 降维有很多重要的应用, 特征的维数过高, 会增加训练的负担与存储空间, 降维就是希望去除特征的冗余, 用更加少的维数来表示特征. 降维算法最基础的就是PCA了, 后面的很多算法都是以PCA为基础演化而来。
机器学习 scikit-learn 图谱的更多相关文章
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- 机器学习 machine learn
机器学习 机器学习 概述 什么是机器学习 机器学习是一门能够让编程计算机从数据中学习的计算机科学.一个计算机程序在完成任务T之后,获得经验E,其表现效果为P,如果任务T的性能表现,也就是用以衡量的P, ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
随机推荐
- cheap louis vuitton outlet
<h1>louis vuitton outlet store</h1>2 nigerian networking systems chosen seeing that enem ...
- Office 365 开发入门
<Office 365 开发入门指南>公开邀请试读,欢迎反馈 终于等来了这一天,可以为我的这本新书画上一个句号.我记得是在今年的2月份从西雅图回来之后,就萌发了要为中国的Office 36 ...
- Android锁屏状态下弹出activity,如新版qq的锁屏消息提示
在接收消息广播的onReceive里,跳转到你要显示的界面.如: Intent intent = new Intent(arg0,MainActivity.class); intent.addFlag ...
- 最新番茄花园win7系统快速稳定版
这是最新番茄花园win7系统64位快速稳定版 V2016年2月,该系统由系统妈整理和上传,系统具有更安全.更稳定.更人性化等特点.集成最常用的装机软件,集成最全面的硬件驱动,精心挑选的系统维护工具,加 ...
- <LeetCode OJ> 121. /122. Best Time to Buy and Sell Stock(I / II)
Say you have an array for which the ith element is the price of a given stock on day i. If you were ...
- .net调用存储过程详解(转载)
本文的数据库用的是sql server 连接字符串 string conn = ConfigurationManager.ConnectionStrings["NorthwindConnec ...
- Easy AR简单教程
Easy AR简单教程 相关SDK资源下载链接:http://pan.baidu.com/s/1dERtCWD 密码:o0jd 1.ImageTarget的制作 (1).导入EasyARSD包,删 ...
- SQL Server 中 GO 的用法(转)
本科里学了那么多年SQL Server一直看到书上各种SQL语句中间夹杂着那么几个看似毫无意义的GO,看着就让人莫名,问老师,老师一般只会告诉你,不要理他,这个东西没用的.但是个性纠结并且有轻微强迫症 ...
- kafka source type
https://flume.apache.org/FlumeUserGuide.html # example.conf: A single-node Flume configuration # Nam ...
- 【题解】P1407国家集训队稳定婚姻
[题解][P1407 国家集训队]稳定婚姻 很好的一道建模+图论题. 婚姻关系?很像二分图匹配呀,不过不管怎么办先建模再说.婚姻关系显然用图方面的知识解决.建图! 它给定的是字符串,所以我们使用\(a ...