机器学习 scikit-learn 图谱
scikit-learn 是机器学习领域非常热门的一个开源库,基于Python 语言写成。可以免费使用。
网址: http://scikit-learn.org/stable/index.html
上面有很多的教程,编程实例。而且还做了很好的总结,下面这张图基本概括了传统机器学习领域的大多数理论与相关算法。
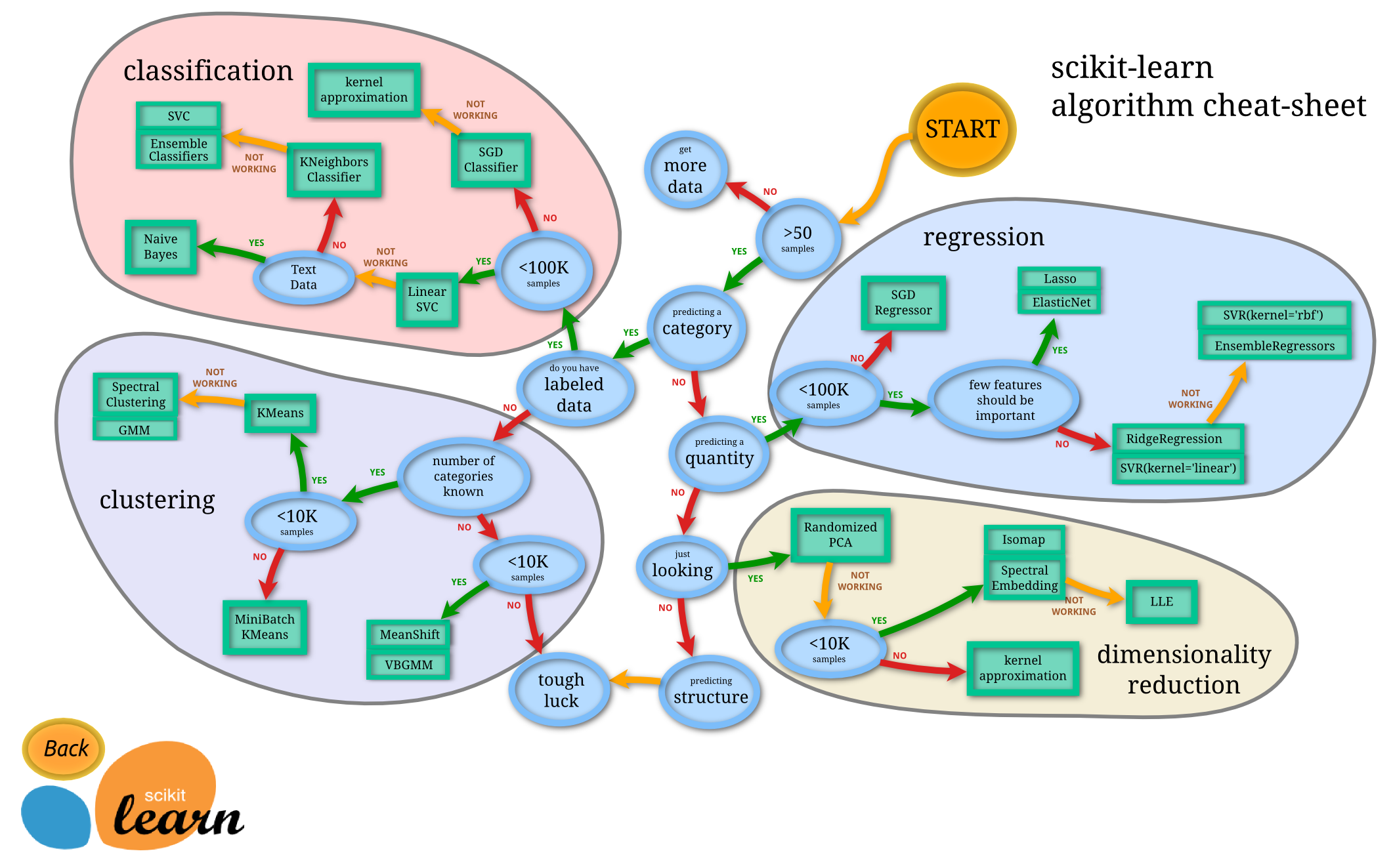
我们可以看到,机器学习分为四大块,分别是 classification (分类), clustering (聚类), regression (回归), dimensionality reduction (降维)。
给定一个样本特征 x, 我们希望预测其对应的属性值 y, 如果 y 是离散的, 那么这就是一个分类问题,反之,如果 y 是连续的实数, 这就是一个回归问题。
如果给定一组样本特征 S={x∈RD}, 我们没有对应的 y, 而是想发掘这组样本在 D 维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
如果我们想用维数更低的子空间来表示原来高维的特征空间, 那么这就是降维问题。
classification & regression
无论是分类还是回归,都是想建立一个预测模型 H,给定一个输入 x, 可以得到一个输出 y:
不同的只是在分类问题中, y 是离散的; 而在回归问题中 y 是连续的。所以总得来说,两种问题的学习算法都很类似。所以在这个图谱上,我们看到在分类问题中用到的学习算法,在回归问题中也能使用。分类问题最常用的学习算法包括 SVM (支持向量机) , SGD (随机梯度下降算法), Bayes (贝叶斯估计), Ensemble, KNN 等。而回归问题也能使用 SVR, SGD, Ensemble 等算法,以及其它线性回归算法。
clustering
聚类也是分析样本的属性, 有点类似classification, 不同的就是classification 在预测之前是知道 y 的范围, 或者说知道到底有几个类别, 而聚类是不知道属性的范围的。所以 classification 也常常被称为 supervised learning, 而clustering就被称为 unsupervised learning。
clustering 事先不知道样本的属性范围,只能凭借样本在特征空间的分布来分析样本的属性。这种问题一般更复杂。而常用的算法包括 k-means (K-均值), GMM (高斯混合模型) 等。
dimensionality reduction
降维是机器学习另一个重要的领域, 降维有很多重要的应用, 特征的维数过高, 会增加训练的负担与存储空间, 降维就是希望去除特征的冗余, 用更加少的维数来表示特征. 降维算法最基础的就是PCA了, 后面的很多算法都是以PCA为基础演化而来。
机器学习 scikit-learn 图谱的更多相关文章
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- 机器学习 machine learn
机器学习 机器学习 概述 什么是机器学习 机器学习是一门能够让编程计算机从数据中学习的计算机科学.一个计算机程序在完成任务T之后,获得经验E,其表现效果为P,如果任务T的性能表现,也就是用以衡量的P, ...
- Query意图分析:记一次完整的机器学习过程(scikit learn library学习笔记)
所谓学习问题,是指观察由n个样本组成的集合,并根据这些数据来预测未知数据的性质. 学习任务(一个二分类问题): 区分一个普通的互联网检索Query是否具有某个垂直领域的意图.假设现在有一个O2O领域的 ...
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
随机推荐
- SQLite基本(实例FileOrganizer2013.5.12)
工具用 SQLite Dev 数据类型: 1.NULL:空值. 2.INTEGER:带符号的整型,具体取决有存入数字的范围大小. 3.REAL:浮点数字,存储为8-byte IEEE浮点数. 4. ...
- 数据挖掘之pandas
sdata={'语文':89,'数学':96,'音乐':39,'英语':78,'化学':88} #字典向Series转化 @@ >>> studata=Series(sdata) & ...
- C语言内存分配函数malloc——————【Badboy】
C语言中经常使用的内存分配函数有malloc.calloc和realloc等三个,当中.最经常使用的肯定是malloc,这里简单说一下这三者的差别和联系. 1.声明 这三个函数都在stdlib.h库文 ...
- NUTCH2.3 hadoop2.7.1 hbase1.0.1.1 solr5.2.1部署(二)
Precondition: hadoop 2.7.1 hbase 1.0.1.1 / hbase 0.98.13 192.168.1.106 ->master 192.168.1.105 ...
- phpstorm pycharm IntelliJ IDEA激活
phpstorm 和 pycharm server选项里边输入 http://idea.imsxm.com/ IntelliJ IDEA 1. 到网站 http://idea.lanyus.com/ ...
- 使用Reveal来查看别人的APP界面+白苹果不刷机解决方式
Reveal这个强大的界面调试工具.能够实时查看.改动view的属性,大体上实现了iOS程序猿梦寐以求的功能.比方,有时候我们加入了一个view,可是那个view死活不显示出来,这时候祭出Reveal ...
- LoadRunner性能测试过程/流程
用LoadRunner进行负载测试的流程通常由五个阶段组成:计划.脚本创建.场景定义.场景执行和结果分析.(1)计划负载测试:定义性能测试要求,例如并发用户的数量.典型业务流程和所需响应时间.(2)创 ...
- 广播、多播和IGMP的一点记录
广播和多播:仅应用于UDP 广播分为: 1.受限的广播(255.255.255.255) 2.指向网络的广播(eg:A类网络 netid.255.255.255)主机号为全1的地址 3.指向子网的广播 ...
- 九度OJ 1176:树查找 (完全二叉树)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:5209 解决:2193 题目描述: 有一棵树,输出某一深度的所有节点,有则输出这些节点,无则输出EMPTY.该树是完全二叉树. 输入: 输入 ...
- Python爬虫-- selenium库
selenium库 selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写及运行(Selenium Remote Control)和测试的并行处理(S ...