【Oracle】OVER(PARTITION BY)函数用法
http://blog.itpub.net/10159839/viewspace-254449/
、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、、
OVER(PARTITION BY)函数介绍
Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化,举例如下:
1:over后的写法:
over(order by salary) 按照salary排序进行累计,order by是个默认的开窗函数
over(partition by deptno)按照部门分区
2:开窗的窗口范围:
over(order by salary range between 5 preceding and 5 following):窗口范围为当前行数据幅度减5加5后的范围内的。
举例:
--sum(s)over(order by s range between 2 preceding and 2 following) 表示加2或2的范围内的求和
select name,class,s, sum(s)over(order by s range between 2 preceding and 2 following) mm from t2
adf 3 45 45 --45加2减2即43到47,但是s在这个范围内只有45
asdf 3 55 55
cfe 2 74 74
3dd 3 78 158 --78在76到80范围内有78,80,求和得158
fda 1 80 158
gds 2 92 92
ffd 1 95 190
dss 1 95 190
ddd 3 99 198
gf 3 99 198
举例:
select name,class,s, sum(s)over(order by s rows between 2 preceding and 2 following) mm from t2
adf 3 45 174 (45+55+74=174)
asdf 3 55 252 (45+55+74+78=252)
cfe 2 74 332 (74+55+45+78+80=332)
3dd 3 78 379 (78+74+55+80+92=379)
fda 1 80 419
gds 2 92 440
ffd 1 95 461
dss 1 95 480
ddd 3 99 388
gf 3 99 293
3、与over函数结合的几个函数介绍
下面以班级成绩表t2来说明其应用
t2表信息如下:
cfe 2 74
dss 1 95
ffd 1 95
fda 1 80
gds 2 92
gf 3 99
ddd 3 99
adf 3 45
asdf 3 55
3dd 3 78
select * from
(
select name,class,s,rank()over(partition by class order by s desc) mm from t2
)
where mm=1;
得到的结果是:
dss 1 95 1
ffd 1 95 1
gds 2 92 1
gf 3 99 1
ddd 3 99 1
注意:
1.在求第一名成绩的时候,不能用row_number(),因为如果同班有两个并列第一,row_number()只返回一个结果;
select * from
(
select name,class,s,row_number()over(partition by class order by s desc) mm from t2
)
where mm=1;
1 95 1 --95有两名但是只显示一个
2 92 1
3 99 1 --99有两名但也只显示一个
2.rank()和dense_rank()可以将所有的都查找出来:
如上可以看到采用rank可以将并列第一名的都查找出来;
rank()和dense_rank()区别:
--rank()是跳跃排序,有两个第二名时接下来就是第四名;
select name,class,s,rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 3 --直接就跳到了第三
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 3
asdf 3 55 4
adf 3 45 5
--dense_rank()l是连续排序,有两个第二名时仍然跟着第三名
select name,class,s,dense_rank()over(partition by class order by s desc) mm from t2
dss 1 95 1
ffd 1 95 1
fda 1 80 2 --连续排序(仍为2)
gds 2 92 1
cfe 2 74 2
gf 3 99 1
ddd 3 99 1
3dd 3 78 2
asdf 3 55 3
adf 3 45 4
--sum()over()的使用
select name,class,s, sum(s)over(partition by class order by s desc) mm from t2 --根据班级进行分数求和
dss 1 95 190 --由于两个95都是第一名,所以累加时是两个第一名的相加
ffd 1 95 190
fda 1 80 270 --第一名加上第二名的
gds 2 92 92
cfe 2 74 166
gf 3 99 198
ddd 3 99 198
3dd 3 78 276
asdf 3 55 331
adf 3 45 376
first_value() over()和last_value() over()的使用
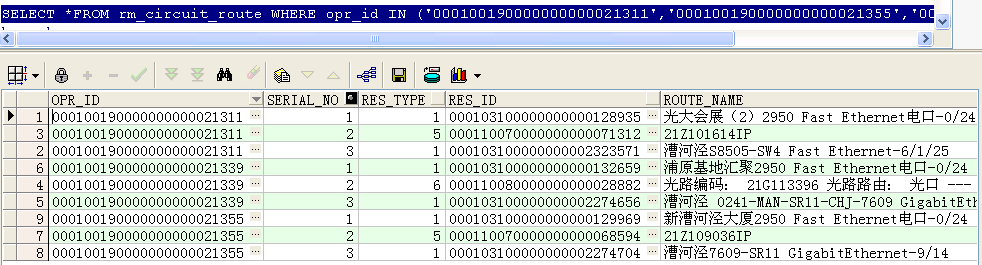
--找出这三条电路每条电路的第一条记录类型和最后一条记录类型
first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low,
last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type rows BETWEEN unbounded preceding AND unbounded following) high
FROM rm_circuit_route
WHERE opr_id IN ('000100190000000000021311','000100190000000000021355','000100190000000000021339')
ORDER BY opr_id;
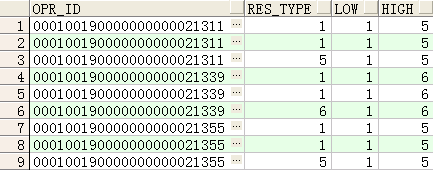
注:rows BETWEEN unbounded preceding AND unbounded following 的使用
--取last_value时不使用rows BETWEEN unbounded preceding AND unbounded following的结果
first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low,
last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) high
FROM rm_circuit_route
WHERE opr_id IN ('000100190000000000021311','000100190000000000021355','000100190000000000021339')
ORDER BY opr_id;
如下图可以看到,如果不使用
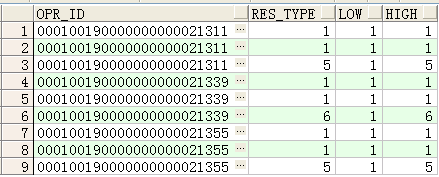
数据如下:

取出该电路的第一条记录,加上ignore nulls后,如果第一条是判断的那个字段是空的,则默认取下一条,结果如下所示:


lag(expresstion,<offset>,<default>)
with a as
(select 1 id,'a' name from dual
union
select 2 id,'b' name from dual
union
select 3 id,'c' name from dual
union
select 4 id,'d' name from dual
union
select 5 id,'e' name from dual
)
select id,name,lag(id,1,'')over(order by name) from a;
--lead() over()函数用法(取出后N行数据)
lead(expresstion,<offset>,<default>)
with a as
(select 1 id,'a' name from dual
union
select 2 id,'b' name from dual
union
select 3 id,'c' name from dual
union
select 4 id,'d' name from dual
union
select 5 id,'e' name from dual
)
select id,name,lead(id,1,'')over(order by name) from a;
--ratio_to_report(a)函数用法 Ratio_to_report() 括号中就是分子,over() 括号中就是分母
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over(partition by a) b from a
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over() b from a --分母缺省就是整个占比
order by a;
with a as (select 1 a from dual
union all
select 1 a from dual
union all
select 1 a from dual
union all
select 2 a from dual
union all
select 3 a from dual
union all
select 4 a from dual
union all
select 4 a from dual
union all
select 5 a from dual
)
select a, ratio_to_report(a)over() b from a
group by a order by a;--分组后的占比
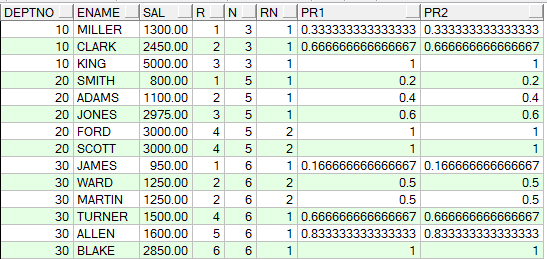
SELECT a.deptno,
a.ename,
a.sal,
a.r,
b.n,
(a.r-1)/(n-1) pr1,
percent_rank() over(PARTITION BY a.deptno ORDER BY a.sal) pr2
FROM (SELECT deptno,
ename,
sal,
rank() over(PARTITION BY deptno ORDER BY sal) r --计算出在组中的排名序号
FROM emp
ORDER BY deptno, sal) a,
(SELECT deptno, COUNT(1) n FROM emp GROUP BY deptno) b --按部门计算每个部门的所有成员数
WHERE a.deptno = b.deptno;
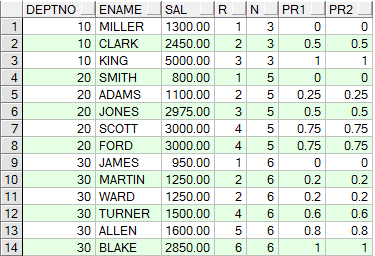
如下所示自己计算的pr1与通过percent_rank函数得到的值是一样的:
SELECT a.deptno,
a.ename,
a.sal,
a.r,
b.n,
c.rn,
(a.r + c.rn - 1) / n pr1,
cume_dist() over(PARTITION BY a.deptno ORDER BY a.sal) pr2
FROM (SELECT deptno,
ename,
sal,
rank() over(PARTITION BY deptno ORDER BY sal) r
FROM emp
ORDER BY deptno, sal) a,
(SELECT deptno, COUNT(1) n FROM emp GROUP BY deptno) b,
(SELECT deptno, r, COUNT(1) rn,sal
FROM (SELECT deptno,sal,
rank() over(PARTITION BY deptno ORDER BY sal) r
FROM emp)
GROUP BY deptno, r,sal
ORDER BY deptno) c --c表就是为了得到每个部门员工工资的一样的个数
WHERE a.deptno = b.deptno
AND a.deptno = c.deptno(+)
AND a.sal = c.sal;
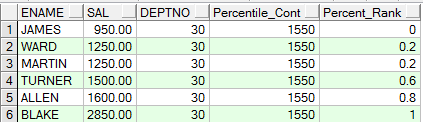
如下,输入百分比为0.7,因为0.7介于0.6和0.8之间,因此返回的结果就是0.6对应的sal的1500加上0.8对应的sal的1600平均
SELECT ename,
sal,
deptno,
percentile_cont(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Cont",
percent_rank() over(PARTITION BY deptno ORDER BY sal) "Percent_Rank"
FROM emp
WHERE deptno IN (30, 60);
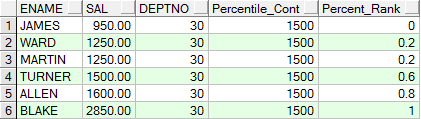
SELECT ename,
sal,
deptno,
percentile_cont(0.6) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Cont",
percent_rank() over(PARTITION BY deptno ORDER BY sal) "Percent_Rank"
FROM emp
WHERE deptno IN (30, 60);
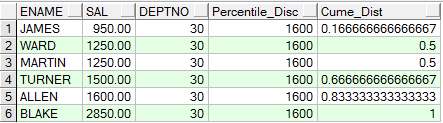
注意:本函数与PERCENTILE_CONT的区别在找不到对应的分布值时返回的替代值的计算方法不同
SAMPLE:下例中0.7的分布值在部门30中没有对应的Cume_Dist值,所以就取下一个分布值0.83333333所对应的SALARY来替代
SELECT ename,
sal,
deptno,
percentile_disc(0.7) within GROUP(ORDER BY sal) over(PARTITION BY deptno) "Percentile_Disc",
cume_dist() over(PARTITION BY deptno ORDER BY sal) "Cume_Dist"
FROM emp
WHERE deptno IN (30, 60);
【Oracle】OVER(PARTITION BY)函数用法的更多相关文章
- OVER(PARTITION BY)函数用法
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返 ...
- 获得供应商最近一次报价:OVER(PARTITION BY)函数用法的实际用法
利用rownumber ,关键字partition进行小范围分页 方法一: --所有供应商对该产品最近的一次报价with oa as(select a.SupplierId ,UnitPrice,Pr ...
- sql server ,OVER(PARTITION BY)函数用法,开窗函数,over子句,over开窗函数
https://technet.microsoft.com/zh-cn/library/ms189461(v=sql.105).aspx https://social.msdn.microsoft.c ...
- oracle OVER(PARTITION BY) 函数
OVER(PARTITION BY)函数介绍 开窗函数 Oracle从8.1.6开始提供分析函数,分析函数用于计算基于组的某种聚合值,它和聚合函数的不同之处是:对于每个组返 ...
- 【Oracle】row_number() over(partition by )函数用法
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编 ...
- oracle中分组排序函数用法 - 转
项目开发中,我们有时会碰到需要分组排序来解决问题的情况,如:1.要求取出按field1分组后,并在每组中按照field2排序:2.亦或更加要求取出1中已经分组排序好的前多少行的数据 这里通过一张表的示 ...
- Oracle中的时间函数用法(to_date、to_char) (总结)
一.24小时的形式显示出来要用HH24 select to_char(sysdate,'yyyy-MM-dd HH24:mi:ss') from dual; select to_date('2005- ...
- 分组函数group by和Oracle中分析函数partition by的用法以及区别
1.分组函数group by和Oracle中分析函数partition by的用法以及区别 2.开窗函数.
- oracle下的OVER(PARTITION BY)函数介绍
转自:http://www.cnblogs.com/lanzi/archive/2010/10/26/1861338.html OVER(PARTITION BY)函数介绍 开窗函数 ...
随机推荐
- 分享知识-快乐自己:Hibernate 关联映射
关联关系映射--概念: 关联关系是使用最多的一种关系,非常重要.在内存中反映为实体关系,映射到DB中为主外键关系. 实体间的关联,即对外键的维护.关联关系的发生,即对外键数据的改变. 外键:外面的主键 ...
- 搭建LoadRunner中的场景(一) 创建场景
一.创建场景 1. 使用场景创建设置对话框 场景分类: 1. 人工场景:相比面向目标场景,人工场景在实际工作中的应用更为广泛. 2. 面向目标场景:预先定义了一个测试目标,LoadRunner将根据这 ...
- HDU 6170 Two strings (dp)
/** * 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6170 * 字符串match, '.'代表匹配任意一个字符,"*" 代表 ...
- LINUX socket网络编程
1. 网络中进程之间如何通信 进 程通信的概念最初来源于单机系统.由于每个进程都在自己的地址范围内运行,为保证两个相互通信的进 程之间既互不干扰又协调一致工作,操作系统为进程通信提供了相应设施,如 U ...
- Selenium实战脚本集—新浪微博发送QQ每日焦点
Selenium实战脚本集-新浪微博发送QQ每日焦点 http://www.spasvo.com/ceshi/open/kygncsgj/Selenium/201549150822.html 背景 很 ...
- 阿里云服务器CentOS7中Tomcat8.x启动慢问题解决记录
公司服务器刚换CentOS7,在内部的刀片机上一直跑的很溜,迁移到阿里云上后Tomcat启动竟然要6.7分钟!这还了得. 且日志上无任何错误,在日志中查看到如下信息: Log4j:[2015-10-2 ...
- HDU - 6081 2017百度之星资格赛 度度熊的王国战略
度度熊的王国战略 Accepts: 644 Submissions: 5880 Time Limit: 40000/20000 MS (Java/Others) Memory Limit: 3 ...
- 使用HTML辅助方法载入分部视图
在webform中我们用过user control可以减少重复代码也利于将页面模组化, 在mvc中 叫分部视图 Partial View. 也就是一个片段的view.可以利用Partial vie ...
- Guid string 转换
System.Guid.NewGuid().ToString(); //GUID带-分割// db1b98e9-6f93-41aa-84f8-5eb773e93d67System.Guid.NewGu ...
- CMD运行指令
CMD运行指令 开始→运行→CMD→键入以下命令即可: gpedit.msc-----组策略 sndrec32-------录音机 Nslookup-------IP地址侦测器 explo ...