利用python数据分析panda学习笔记之基本功能
1 重新生成索引 如果某个索引值不存在就引入缺失值
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
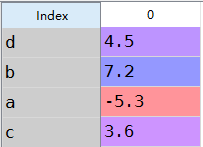
obj=Series([4.5,7.2,-5.3,3.6],index=['d','b','a','c'])
obj #重新生成索引
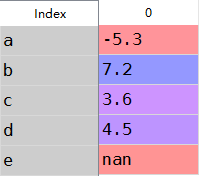
obj2=obj.reindex(['a','b','c','d','e'])
obj2
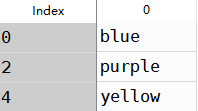
a使用method的ffill可以实现前向值填充,效果如下
#前向填充
obj3=Series(['blue','purple','yellow'],index=[,,])
obj3.reindex(range(),method='ffill')

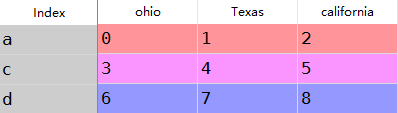
b:对于dataframe使用reindex可以同时修改行列索引,如果仅传入一个序列那么如下
frame=DataFrame(np.arange().reshape((,)),index=['a','c','d'],
columns=['ohio','Texas','california'])
frame
frame2=frame.reindex(['a','b','c','d'])
frame2
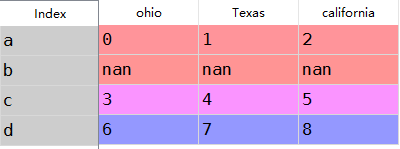
c:使用colunms重新索引列
states=['Texax','Utah','california']
frame.reindex(columns=states)

d:同时插入行列,但是插值只能按行应用
#同时对行 列进行重新索引 而插值只能引用到行
frame.reindex(index=['a','b','c','d'],method='ffill',
columns=states)

reindex的参数说明如下:

2 丢弃制定轴上的项
a:drop方法返回一个指定轴上删除了指定值的新对象,删除列c
#丢弃指定轴的项
obj=Series(np.arange(.),index=['a','b','c','d','e'])
new_obj=obj.drop('c')
new_obj

b:删除两个 b c
obj.drop(['d','c'])
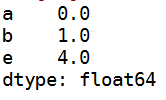
c:对于dataframe可以删除任意轴上的索引
#对于DataFrame可以删除任意轴的索引
data = DataFrame(np.arange().reshape((,)),
index=['ohio','colorado','utah','new york'],
columns=['one','two','three','four'])
#删除两个
data.drop(['colorado','ohio'])
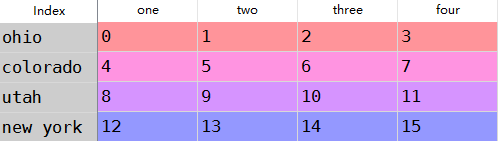
3 索引,选取和过滤
a:Series中的索引类似与Numpy,但是不只是整数,索引字符
obj=Series(np.arange(.),index=['a','b','c','d'])
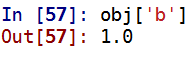
obj['b']#1.0
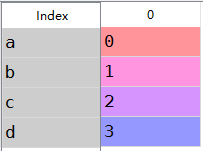
b:按照整数,范围
obj[]#1.0
obj[:]#

c:利用标签的切片运算和普通depython切片不同,其包含末端
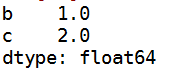
obj['b':'c']#b c
d:那么对dataframe进行索引就是获取一个或者多个列勒
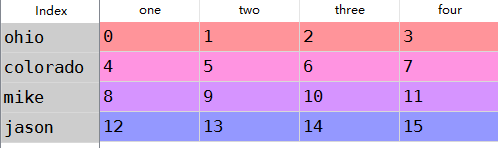
data=DataFrame(np.arange().reshape(,),
index=['ohio','colorado','mike','jason'],
columns=['one','two','three','four'])
data
e:选择一列
data['two']#输出第二列+行号 也就是索引
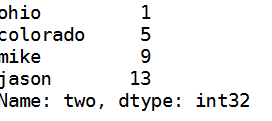
f:选择多列
data[['three','one']]

g:选取行标签前两行
data[:]#选取的是前面两行

h:选取第三列大于5的值
data[data['three']>]
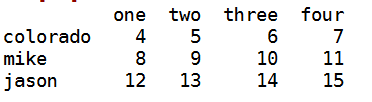
i:为了能在dataframe的行上进行标签索引引入字段ix
data.ix['colorado',['two','three']]

j:选取第4 1 2列 而且行为colorado jason
data.ix[['colorado','jason'],[,,]]
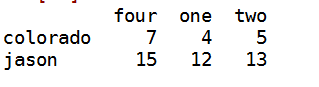
k:输出行mike
data.ix[]

DataFrame索引总结

4 算数运算和数据对齐
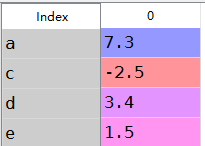
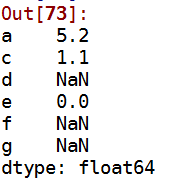
a:Series的加法
s1=Series([7.3,-2.5,3.4,1.5],index=['a','c','d','e'])
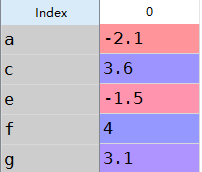
s2=Series([-2.1,3.6,-1.5,,3.1],index=['a','c','e','f','g'])
3 s1+s2
b:对于dataframe,对齐会同时发生在行 列中
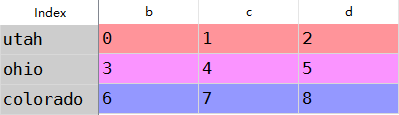
df1=DataFrame(np.arange(.).reshape((,)),columns=list('bcd'),
index=['utah','ohio','colorado'])
df2=DataFrame(np.arange(.).reshape((,)),columns=list('bde'),
index=['utah','ohio','colorado','oragen'])

df1+df2

------>索引和列都为其并集
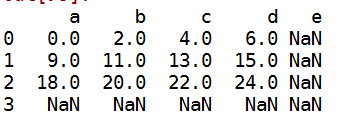
c:在算术方法中填充值。比如说两个dataframe相加,其中一个不在的时候填充为0
#算术中进行填充
df1=DataFrame(np.arange(.).reshape((,)),columns=list('abcd'))
df2=DataFrame(np.arange(.).reshape((,)),columns=list('abcde'))
df1+df2
#使用df1的add方法 传入df2以及一个fill_value参数
df1.add(df2,fill_value=)

5 DataFrame和Series之间的运算----->广播,也就是如果第一个数值-1,那么这个列都会减1
a:看一看一个二维数组和一行之间的差
arr=np.arange(.).reshape((,))
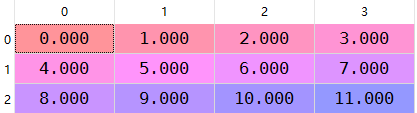
arr[]

arr-arr[]

b:frame和series的运算
frame=DataFrame(np.arange(.).reshape((,)),columns=list('bde'),
index=['utah','ohio','texas','orogen'])
series=frame.ix[]

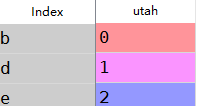
frame-series

好了,加油骚年!!!!
利用python数据分析panda学习笔记之基本功能的更多相关文章
- 利用python数据分析panda学习笔记之Series
1 Series a:类似一维数组的对象,每一个数据与之相关的数据标签组成 b:生成的左边为索引,不指定则默认从0开始. from pandas import Series,DataFrame imp ...
- 利用python数据分析panda学习笔记之DataFrame
2 DataFrame a:通过传入一个等长的列表构成DataFrame 自动加上索引 data={'state':['ohio','ohio','ohio','Nevada','Nevada'], ...
- python数据分析入门学习笔记
学习利用python进行数据分析的笔记&下星期二内部交流会要讲的内容,一并分享给大家.博主粗心大意,有什么不对的地方欢迎指正~还有许多尚待完善的地方,待我一边学习一边完善~ 前言:各种和数据分 ...
- python数据分析入门学习笔记儿
学习利用python进行数据分析的笔记儿&下星期二内部交流会要讲的内容,一并分享给大家.博主粗心大意,有什么不对的地方欢迎指正~还有许多尚待完善的地方,待我一边学习一边完善~ 前言:各种和数据 ...
- Python数据分析:Numpy学习笔记
Numpy学习笔记 ndarray多维数组 创建 import numpy as np np.array([1,2,3,4]) np.array([1,2,3,4,],[5,6,7,8]) np.ze ...
- $《利用Python进行数据分析》学习笔记系列——IPython
本文主要介绍IPython这样一个交互工具的基本用法. 1. 简介 IPython是<利用Python进行数据分析>一书中主要用到的Python开发环境,简单来说是对原生python交互环 ...
- Requests:Python HTTP Module学习笔记(一)(转)
Requests:Python HTTP Module学习笔记(一) 在学习用python写爬虫的时候用到了Requests这个Http网络库,这个库简单好用并且功能强大,完全可以代替python的标 ...
- python网络爬虫学习笔记
python网络爬虫学习笔记 By 钟桓 9月 4 2014 更新日期:9月 4 2014 文章文件夹 1. 介绍: 2. 从简单语句中開始: 3. 传送数据给server 4. HTTP头-描写叙述 ...
- Python Built-in Function 学习笔记
Python Built-in Function 学习笔记 1. 匿名函数 1.1 什么是匿名函数 python允许使用lambda来创建一个匿名函数,匿名是因为他不需要以标准的方式来声明,比如def ...
随机推荐
- UDIMM、RDIMM、SODIMM以及LRDIMM的区别
DIMM简介 DIMM(Dual Inline Memory Module,双列直插内存模块)与SIMM(single in-line memory module,单边接触内存模组)相当类似,不同的只 ...
- diff patch
http://rails-deployment.group.iteye.com/group/wiki/1318-diff-and-patch-10-minutes-guide 情景一:你正尝试从代码编 ...
- Kubernetes之网络策略(Network Policy)
系列目录 概述 Kubernetes要求集群中所有pod,无论是节点内还是跨节点,都可以直接通信,或者说所有pod工作在同一跨节点网络,此网络一般是二层虚拟网络,称为pod网络.在安装引导kubern ...
- Kubernetes基本概念之Label
系列目录 在为对象定义好Label后,其他对象就可以通过Label来对对象进行引用.Label的最常见的用法便是通过spec.selector来引用对象. apiVersion: v1 kind: R ...
- caffe学习--caffe入门classification00学习--ipython
首先,数据文件和模型文件都已经下载并处理好,不提. cd "caffe-root-dir " ----------------------------------分割线---- ...
- ASP.Net MVC upload file with record & validation - Step 6
Uploading file with other model data, validate model & file before uploading by using DataAnnota ...
- PHP中的面向对象 中的类(class)
2.11 上午讲的是面向对象中的类(class),一个非常抽象的概念, 类里面成员的定义有 public$abc; private$abc(私有变量): protect $abc(受保护的变量): 下 ...
- Win10升级.NET Framework 3.5或2.0遇到错误0x800f081f
具体方法如下: 1.将WIN10安装光盘ISO文件加载到虚拟光驱中. 2.WIN键+R键一起按,输入CMD后回车. 3.在CMD的命令行窗口里输入: cd C:Windowssystem32 跳转到s ...
- #ZgotmplZ go web 开发 base64 图片显示
Go Web开发,用Base64作为图片URL时遇到#ZgotmplZ的问题 - 简书 https://www.jianshu.com/p/54fc25da7c4f // var imgBase64 ...
- 激活win10企业长期服务版
win10 2016 长期服务版的ISO文件中本身就带有KMS激活KEY,不用输入任何KEY,连接网络进入CMD,只要输入:slmgr /skms kms.digiboy.irslmgr /ato这两 ...