Spider-天眼查字体反爬
字体反爬也就是自定义字体反爬,通过调用自定义的woff文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容!
1.思路
近期在爬取天眼查某公司详情页遇到了字体反爬,经过多次测试,终于解决了字体反爬
首先我们来看一下字体反爬

此图可以看出源代码数字跟页面显示的内容是不一样的,在调试器中看到它有一个类tyc-num
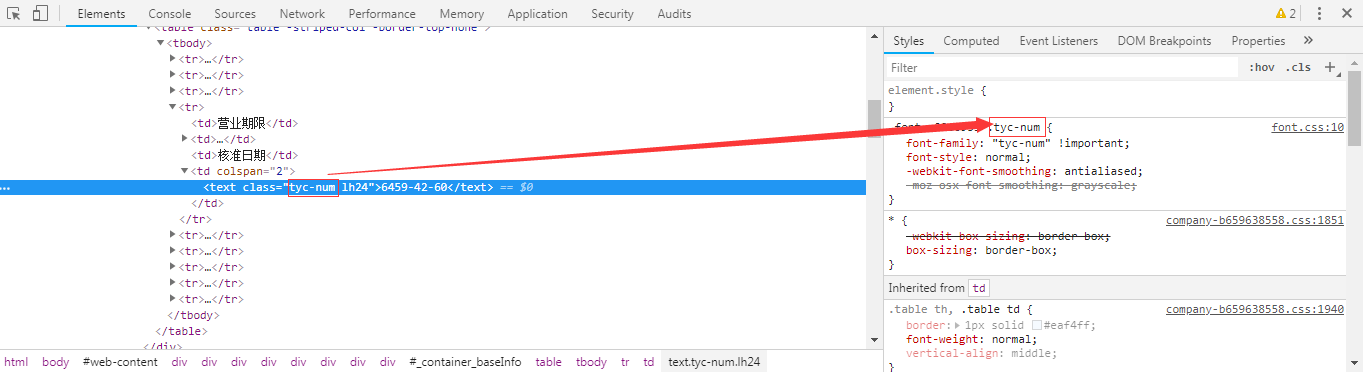
此图可以看出类tyc-num存放的是一个字体,通过network获取这个字体
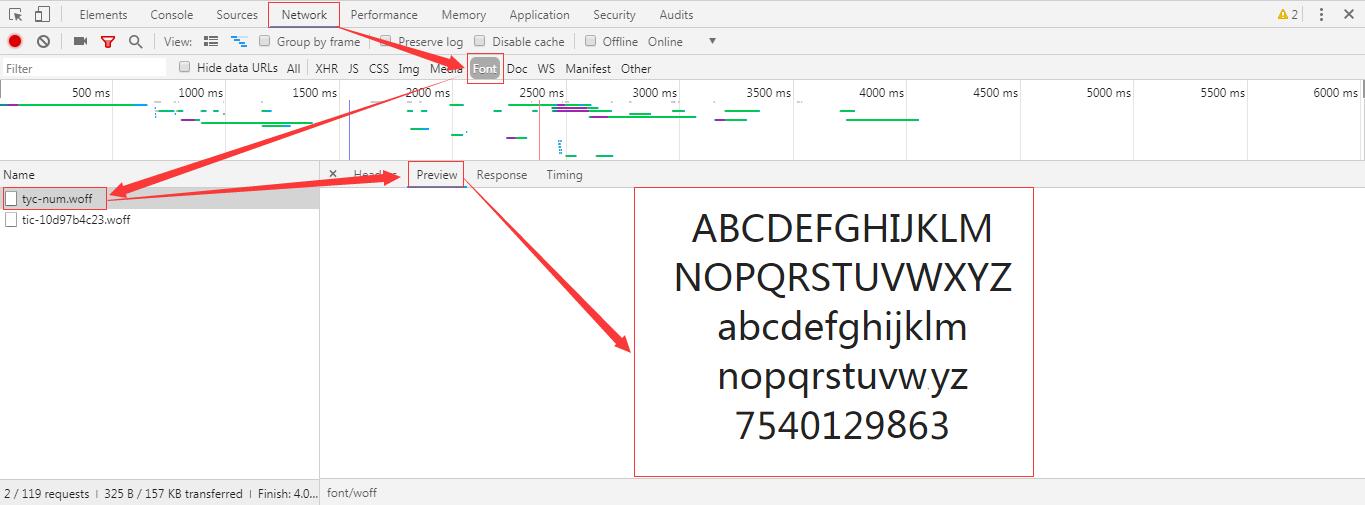
此图可以看出正常的字体数字是1234567890而现在显示的是7540129863它是顺序打乱的,把tyc-num.woff下载过来,下载过来之后发现windows是查看不了的,我用的是在线工具查看
在线工具链接:FontEditor
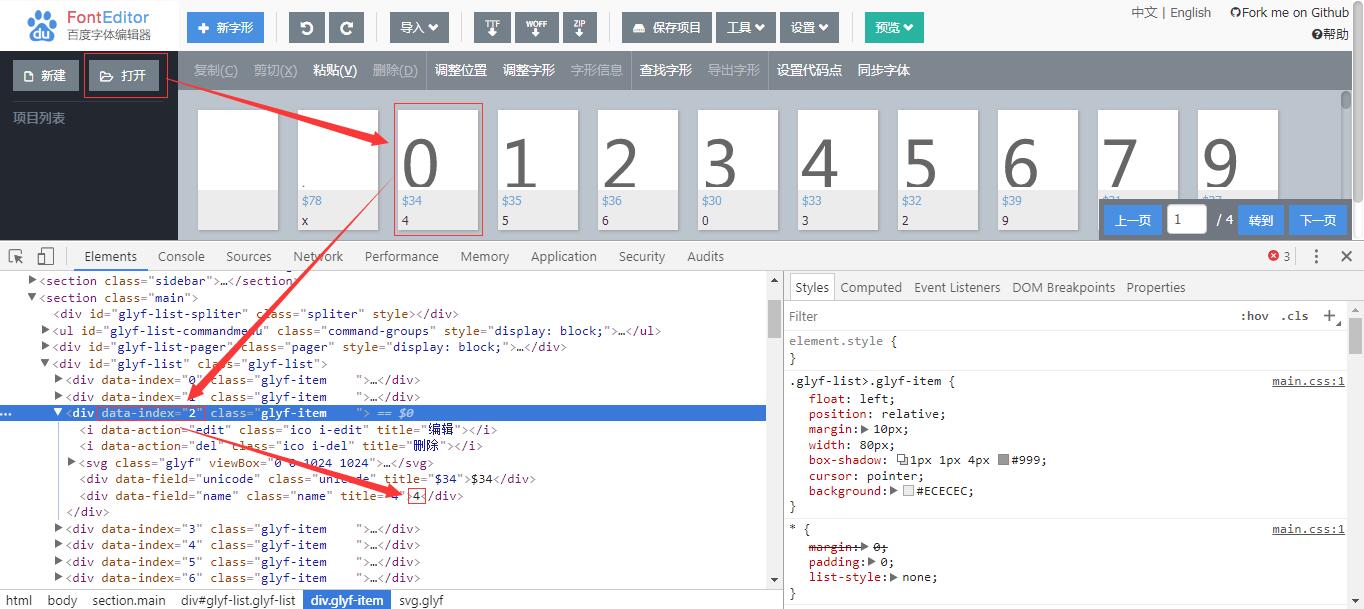
此图可以发现索引2对应的是4,说明第4个数字是0,通过Python对woff转换成xml
from fontTools.ttLib import TTFont
font = TTFont('tyc-num.woff')
font.saveXML('tyc-num.xml')
查看xml文件
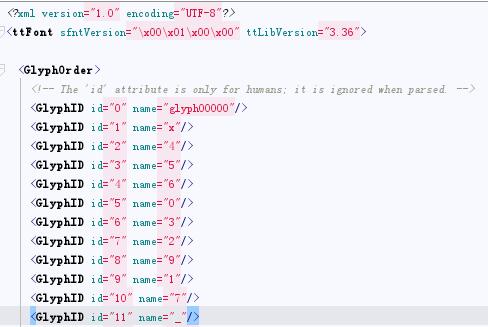
此图发现id2对应是4跟在线查看器是一样的,那就找到了对应关系
2.代码实现
安装 fontTools
pip install fontTools
上代码(代码更新2019-01-21|19:23:16) PS:发现某些公司时间还是对不上,代码更新了,上面思路是一样的
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from fontTools.ttLib import TTFont
import re font = TTFont('tyc-num.woff') # 打开tyc-num.woff
font.saveXML('tyc-num.xml') # 保存为tyc-num.xml
with open('tyc-num.xml', 'r') as f:
xml = f.read() # 读取tyc-num.xml赋值给xml
GlyphID = re.findall(r'<GlyphID id="(.*?)" name="(\d+)"/>', xml) # 获得对应关系
GlyphIDNameLists = list(set([int(Gname) for Gid, Gname in GlyphID])) # 对应关系数量转换
# print(GlyphIDNameLists)
DigitalDicts = {str(i): str(GlyphIDNameLists[i - 2]) for i in range(2, len(GlyphIDNameLists)+2)} # 数字对应关系的字典推导式
# print(DigitalDicts)
GlyphIDDicts = {str(Gname): DigitalDicts[Gid] for Gid, Gname in GlyphID} # 通过数字对应关系生成源代码跟页面显示的字典推导式
print('-' * 39 + '数字对应关系的字典推导式' + '-' * 39)
print(DigitalDicts)
print('-' * 27 + '通过数字对应关系生成源代码跟页面显示的字典推导式' + '-' * 27)
print(GlyphIDDicts)
代码运行结果

Spider-天眼查字体反爬的更多相关文章
- Python爬虫入门教程 63-100 Python字体反爬之一,没办法,这个必须写,反爬第3篇
背景交代 在反爬圈子的一个大类,涉及的网站其实蛮多的,目前比较常被爬虫coder欺负的网站,猫眼影视,汽车之家,大众点评,58同城,天眼查......还是蛮多的,技术高手千千万,总有五花八门的反爬技术 ...
- 58 字体反爬攻略 python3
1.下载安装包 pip install fontTools 2.下载查看工具FontCreator 百度后一路傻瓜式安装即可 3.反爬虫机制 网页上看见的 后台源代码里面的 从上面可以看出,生这个字变 ...
- python解析字体反爬
爬取一些网站的信息时,偶尔会碰到这样一种情况:网页浏览显示是正常的,用python爬取下来是乱码,F12用开发者模式查看网页源代码也是乱码.这种一般是网站设置了字体反爬 一.58同城 用谷歌浏览器打开 ...
- 网络字体反爬之pyspider爬取起点中文小说
前几天跟同事聊到最近在看什么小说,想起之前看过一篇文章说的是网络十大水文,就想把起点上的小说信息爬一下,搞点可视化数据看看.这段时间正在看爬虫框架-pyspider,觉得这种网站用框架还是很方便的,所 ...
- 实战-快手H5字体反爬
实战-快手H5字体反爬 前言 快手H5端的粉丝数是字体反爬,抓到的html文本是乱码 <SPAN STYLE='FONT-FAMILY: kwaiFont;'></SPA ...
- python爬取实习僧招聘信息字体反爬
参考博客:http://www.cnblogs.com/eastonliu/p/9925652.html 实习僧招聘的网站采用了字体反爬,在页面上显示正常,查看源码关键信息乱码,如下图所示: 查看网页 ...
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫-字体反爬-猫眼国内票房榜
偶然间知道到了字体反爬这个东西, 所以决定了解一下. 目标: https://maoyan.com/board/1 问题: 类似下图中的票房数字无法获取, 直接复制粘贴的话会显示 □ 等无法识别的字 ...
随机推荐
- (四)SpringBoot如何定义消息转换器
一:添加fastjson依赖 <dependency> <groupId>com.alibaba</groupId> <artifactId>fastj ...
- Educational Codeforces Round 20 A
Description You are given matrix with n rows and n columns filled with zeroes. You should put k ones ...
- Baker Vai LightOJ - 1071
题意:类似传纸条 方法: 把他要求的操作(一个人来回),转化为两个人同时走,除了开始和结束位置只能走不同路,得到的分数和的最大值即可. 一开始想到要定义的状态,是两个人的x(行)和y(列)坐标.这样时 ...
- vue文件中style标签的几个标识符
.vue文件中style标签的几个标识符 在人生就要绝望的时候, 被编辑器所提示的一个scopedSlots所拯救. 卧槽, 写到最后才发现这个属性的具体卵用. 详情见最后解决办法. 问题背景 问题由 ...
- 今天发现一个汉字转换成拼音的模块,记录一下,直接pip install xpinyin即可
http://blog.csdn.net/qq_33232071/article/details/50915760
- qconbeijing2017
http://2017.qconbeijing.com/schedule 第一天 (2017年4月16日/星期日) 签到 专题 主题演讲 快速进化的容器生态 微服务与 DevOps 最佳实践(厂商 ...
- AJPFX简述Scanner类的特点
hasNextInt() :判断是否还有下一个输入项,其中Xxx可以是Int,Double等.如果需要判断是否包含下一个字符串,则可以省略Xxx nextInt(): 获取下一个输入项. ...
- 【转】几种Java序列化方式的实现
0.前言 本文主要对几种常见Java序列化方式进行实现.包括Java原生以流的方法进行的序列化.Json序列化.FastJson序列化.Protobuff序列化. 1.Java原生序列化 Java原生 ...
- leetcode410 Split Array Largest Sum
思路: dp. 实现: class Solution { public: int splitArray(vector<int>& nums, int m) { int n = nu ...
- 【学习笔记】深入理解js原型和闭包系列学习笔记——精华
深入理解js原型和闭包笔记: 1.“一切皆是对象”,对象是属性的集合. 丨 函数也是对象,但是使用typeof时为什么函数返回function而 丨 不是object呢,js为何要对函数做这样的区分 ...