Python 之有道翻译数据抓取
import requests
import time def you_dao():
key = input("请输入要翻译的内容:")
# key = "哈哈"
# 构建url链接
# url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
# 这里要去掉?号前面的_o,不然会进行加密算法,导致失败
url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule'
salt = int(time.time() * 10000)
ts = int(salt / 10)
form_data = {
"i": key,
"from": "AUTO",
"to": "AUTO",
"smartresult": "dict",
"client": "fanyideskweb",
"salt": salt,
"sign": "abf857d70c24cb55263b1f624193b38b",
"ts": ts,
"bv": "bbb3ed55971873051bc2ff740579bb49",
"doctype": "json",
"version": "2.1",
"keyfrom": "fanyi.web",
"action": "FY_BY_REALTlME",
}
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
json_data = requests.get(url, params=form_data, headers=headers).json()
print(json_data['translateResult'])
return json_data['translateResult'][0][0]['tgt'] if __name__ == '__main__':
you_dao()
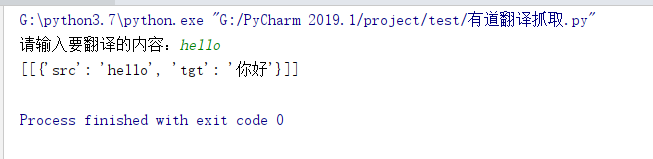
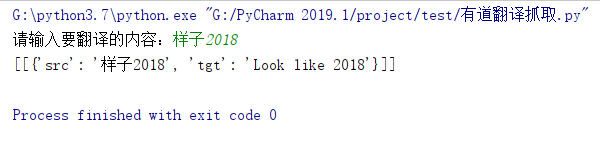
运行效果如图:
Python 之有道翻译数据抓取的更多相关文章
- 吴裕雄--天生自然python学习笔记:WEB数据抓取与分析
Web 数据抓取技术具有非常巨大的应用需求及价值, 用 Python 在网页上收集数据,不仅抓取数据的操作简单, 而且其数据分析功能也十分强大. 通过 Python 的时lib 组件中的 urlpar ...
- Python笔记(十一)——数据抓取例子
上班时候想看股票行情怎么办?试试这个小例子,5分钟拉去一次股票价格,预警: #coding=utf-8 import re import urllib2 import time import thre ...
- Python学习之静态页面数据抓取
1 页面信息抓取 定义getPage函数,根据传入的页码get到整个页面的html内容 getContent函数,通过正则匹配把页面中的表格部分的html内容取出 最后定义getData函数,同样是通 ...
- Python开发笔记:网络数据抓取
网络数据获取(爬取)分为两部分: 1.抓取(抓取网页) · urlib内建模块,特别是urlib.request · Requests第三方库(中小型网络爬虫的开发) · Scrapy框架(大型网络爬 ...
- Python爬虫之-动态网页数据抓取
什么是AJAX: AJAX(Asynchronouse JavaScript And XML)异步JavaScript和XML.过在后台与服务器进行少量数据交换,Ajax 可以使网页实现异步更新.这意 ...
- python 入门实践之网页数据抓取
这个不错.正好入门学习使用. 1.其中用到 feedparser: 技巧:使用 Universal Feed Parser 驾驭 RSS http://www.ibm.com/developerwor ...
- python爬虫数据抓取方法汇总
概要:利用python进行web数据抓取方法和实现. 1.python进行网页数据抓取有两种方式:一种是直接依据url链接来拼接使用get方法得到内容,一种是构建post请求改变对应参数来获得web返 ...
- 数据抓取分析(python + mongodb)
分享点干货!!! Python数据抓取分析 编程模块:requests,lxml,pymongo,time,BeautifulSoup 首先获取所有产品的分类网址: def step(): try: ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
随机推荐
- nodejs shell
REPL (Read-eval-print loop),即输入—求值—输出循环.如果你用过 Python,就会知道在终端下运行无参数的 python 命令或者使用 Python IDLE 打开的 sh ...
- dota监測
执行环境:win7 32位. python版本号:3.4.1 因为用到了一些win32api,这些并不是python标准库自带的,所以你须要先去下载pywin32模块.去http://sourcefo ...
- D3js-API介绍【中】
JavaScript可视化图表库D3.js API中文參考,d3.jsapi D3 库所提供的全部 API 都在 d3 命名空间下.d3 库使用语义版本号命名法(semantic versioning ...
- UVa 11475 - Extend to Palindrome
題目:給你一個字符串,在後面拼接一部分使得它變成回文串,使得串最短.輸出這個回文串. 分析:KMP,dp.這裡利用KMP算法將串和它的轉置匹配,看結束時匹配的長度就可以. 因為串比较長.使用KMP比较 ...
- 一次c3p0连接池连接异常错误的排查
近期写了一个数据库採集程序,大概过程是将SQLSERVER数据库的数据定时採集到Oracle数据库. 1小时出一次数据,每次数据量在2W左右.环境採用Sping3+hibernate4,数据库连接池採 ...
- LeetCode 1002. Find Common Characters (查找常用字符)
题目标签:Array, Hash Table 题目给了我们一个string array A,让我们找到common characters. 建立一个26 size 的int common array, ...
- mysql 多日志表结果集合拼接存储过程
通常单天的日志 仅仅记录当天的日志信息,假设须要查看一月内的日志信息须要对每天的日志表结果集合进行拼接,通经常使用到 union . 储存过程: drop PROCEDURE if EXISTS un ...
- 使用Vitamio插件显示花屏
Vitamio是一款 Android 与 iOS 平台上的全能多媒体开发框架,全面支持硬件解码与 GPU 渲染. 使用vitamio进行播放器的开发非常便捷,使用vitamio的解码,自己编写播放器界 ...
- 常见的几种异常类型Exception
转自:https://blog.csdn.net/niceworkgogogo/article/details/71746208 算数异常类:ArithmeticExecption 空指针异常类型:N ...
- 支持HTTP2的cURL——基于Alpine的最小化Docker镜像
cURL是我喜欢的开源软件之一.虽然cURL的强大常常被认为是理所当然的,但我真心地认为它值得感谢和尊重.如果我们的工具箱失去了curl,那些需要和网络重度交互的人(我们大多数人都是这样的)将会陷入到 ...