数据结构 - 链栈的实行(C语言)
一、什么是链栈?
链栈:是指利用链式存储结构实现的栈。
想想看栈只是栈顶来做插入和删除操作,栈顶放在链栈的头部还是尾部呢?由于单链表有头指针,而栈顶指针也是必须的,那干吗不让它俩合二为一呢,所以比较好的办法是把栈顶放在链栈的头部(如下图所示)。另外,都已经有了栈顶在头部了,单链表中比较常用的头结点也就失去了意义,通常对于链栈来说,是不需要头结点的。
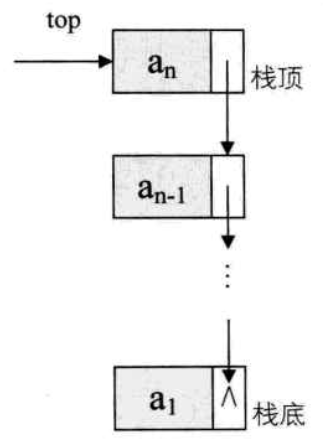
对于空栈来说,链表原定义是头指针指向空,那么链栈的空其实就是 top=NULL 的时候。
链栈的结构代码如下:
typedef int ElemType; /* ElemType类型根据实际情况而定,这里假设为int */
/* 链栈结点结构 */
typedef struct StackNode
{
ElemType data;
struct StackNode *next;
}StackNode;
/* 链栈结构 */
typedef struct
{
StackNode *top;
int count;
}LinkStack;
链栈的操作绝大部分都和单链表类似,只是在插入和删除上,特殊一些。
顺序栈与链栈的区别
两者在时间复杂度上是一样的,均为 O(1)。对于空间性能,顺序栈需要事先确定一个固定的长度,可能会存在内存空间浪费的问题,但它的优势是存取时定位很方便,而链栈则要求每个元素都有指针域,这同时也增加了一些内存开销,但对于栈的长度无限制。所以它们的区别和线性表中讨论的一样,如果栈的使用过程中元素变化不可预料,有时很小,有时非常大,那么最好是用链栈,反之,如果它的变化在可控范围内,建议使用顺序栈会更好一些。
二、基本操作
2.1 初始化栈操作
实现代码如下:
// 初始化栈操作
Status initStack(LinkStack **stack)
{
// 注意要给链栈分配内存
*stack = (LinkStack *)malloc(sizeof(LinkStack));
(*stack)->top = NULL; // 链栈的空其实就是 top=NULL 的时候
(*stack)->count = 0;
return TRUE;
}
2.2 进栈操作
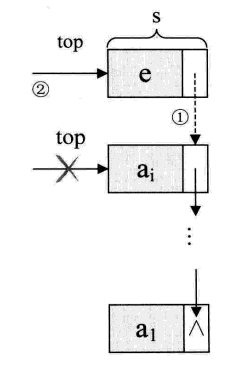
对于链栈的进栈 push 操作,假设元素值为 e 的新结点是 s,top 为栈顶指针,示意图如下图所示:
实现代码如下:
// 进栈操作
Status push(LinkStack *stack, ElemType e)
{
StackNode *s = (StackNode *)malloc(sizeof(StackNode));
s->data = e;
s->next = stack->top; // 把当前的栈顶元素赋值给新结点的直接后继,见图中①
stack->top = s; // 将新的结点s赋值给栈顶指针,见图中②
stack->count++;
return TRUE;
}
2.3 出栈操作
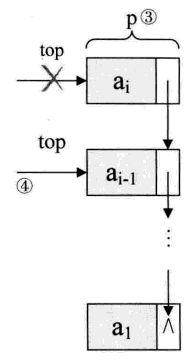
至于链栈的出栈 pop 操作,也是很简单的三句操作。假设变量 p 用来存储要删除的栈顶结点,将栈顶指针下移一位,最后释放 p 即可,如下图所示:
// 出栈操作
Status pop(LinkStack *stack, ElemType *e)
{
StackNode *p;
if (isEmpty(stack))
return FALSE;
*e = stack->top->data;
p = stack->top; // p用来存储要删除的栈顶结点,见图中③
stack->top = stack->top->next; // 使得栈顶指针下移一位,指向后一结点,见图中④
free(p); // 释放结点p
stack->count--;
return TRUE;
}
链栈的进栈 push 和出栈 pop 操作都很简单,没有任何循环操作,时间复杂度均为 O(1)。
2.4 遍历栈操作
实现代码如下:
// 遍历栈操作
Status traverseStack(LinkStack *stack)
{
StackNode *p;
p = stack->top;
while (p)
{
printf("%d ", p->data);
p = p->next;
}
printf("\n");
return TRUE;
}
三、完整程序
#include <stdio.h>
#include <stdlib.h>
#define TRUE 1
#define FALSE 0
#define MAXSIZE 20 /* 存储空间初始分配量 */
typedef int Status;
typedef int ElemType; /* ElemType类型根据实际情况而定,这里假设为int */
/* 链栈结点结构 */
typedef struct StackNode
{
ElemType data;
struct StackNode *next;
}StackNode;
/* 链栈结构 */
typedef struct
{
StackNode *top;
int count;
}LinkStack;
Status initStack(LinkStack **stack); // 初始化栈操作
Status push(LinkStack *stack, const ElemType e); // 进栈操作
Status pop(LinkStack *stack, ElemType *e); // 出栈操作
Status traverseStack(LinkStack *stack); // 遍历栈操作
Status clearStack(LinkStack *stack); // 清空栈操作
Status isEmpty(LinkStack *stack); // 判断是否为空
Status getTop(LinkStack *stack, ElemType *e); // 获得栈顶元素
int getLength(LinkStack *stack); // 获取栈的长度
// 初始化栈操作
Status initStack(LinkStack **stack)
{
// 注意要给链栈分配内存
*stack = (LinkStack *)malloc(sizeof(LinkStack));
(*stack)->top = NULL; // 链栈的空其实就是 top=NULL 的时候
(*stack)->count = 0;
return TRUE;
}
// 进栈操作
Status push(LinkStack *stack, ElemType e)
{
StackNode *s = (StackNode *)malloc(sizeof(StackNode));
s->data = e;
s->next = stack->top; // 把当前的栈顶元素赋值给新结点的直接后继,见图中①
stack->top = s; // 将新的结点s赋值给栈顶指针,见图中②
stack->count++;
return TRUE;
}
// 出栈操作
Status pop(LinkStack *stack, ElemType *e)
{
StackNode *p;
if (isEmpty(stack))
return FALSE;
*e = stack->top->data;
p = stack->top; // p用来存储要删除的栈顶结点,见图中③
stack->top = stack->top->next; // 使得栈顶指针下移一位,指向后一结点,见图中④
free(p); // 释放结点p
stack->count--;
return TRUE;
}
// 遍历栈操作
Status traverseStack(LinkStack *stack)
{
StackNode *p;
p = stack->top;
while (p)
{
printf("%d ", p->data);
p = p->next;
}
printf("\n");
return TRUE;
}
// 清除栈操作
Status clearStack(LinkStack *stack)
{
StackNode *p;
StackNode *q;
p = stack->top;
while (p)
{
q = p;
p = p->next;
free(q);
}
stack->count = 0;
return TRUE;
}
// 判断是否为空栈
Status isEmpty(LinkStack *stack)
{
return stack->count == 0 ? TRUE : FALSE;
}
// 获得栈顶元素
Status getTop(LinkStack *stack, ElemType *e)
{
if (stack->top == NULL)
return FALSE;
else
*e = stack->top->data;
return TRUE;
}
// 获得栈的长度
int getLength(LinkStack *stack)
{
return stack->count;
}
int main()
{
// 初始化栈
LinkStack *stack;
if (initStack(&stack) == TRUE)
printf("初始化链栈成功!\n\n");
// 入栈操作
for (int j = 1; j <= 10; j++)
push(stack, j);
printf("入栈操作(0-10)!\n\n");
// 出栈操作
int e;
pop(stack, &e);
printf("弹出的栈顶元素e=%d\n\n", e);
// 遍历栈
printf("遍历栈,栈中元素依次为:");
traverseStack(stack);
printf("\n");
// 获得栈顶元素
getTop(stack, &e);
printf("栈顶元素 e=%d 栈的长度为%d\n\n", e, getLength(stack));
// 判断是否为空栈
printf("栈空否:%d(1:空 0:否)\n\n", isEmpty(stack));
// 清空栈
clearStack(stack);
printf("清空栈后,栈空否:%d(1:空 0:否)\n\n", isEmpty(stack));
return 0;
}
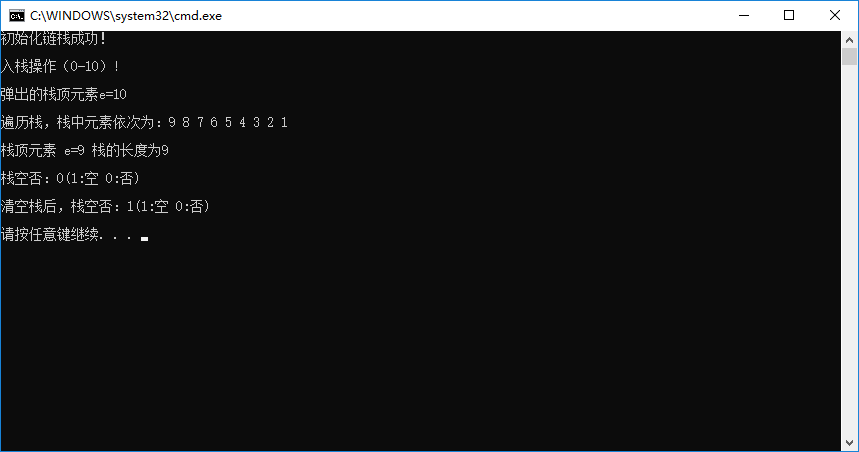
输出结果如下图所示:
参考:
《大话数据结构 - 第4章》 栈与队列
数据结构 - 链栈的实行(C语言)的更多相关文章
- C语言数据结构链栈(创建、入栈、出栈、取栈顶元素、遍历链栈中的元素)
/**创建链栈*创建一个top指针代表head指针*采用链式存储结构*采用头插法创建链表*操作 创建 出栈 入栈 取栈顶元素*创建数据域的结构体*创建数据域的名称指针*使用随机函数对数据域的编号进行赋 ...
- 链栈的基本操作(C语言)
栈的链式储存结构称为链栈.链栈的节点类型与链式线性表的节点类型 定义相同,不同的是它是仅在表头进行操作的单链表.链栈通常用不带头节 点的单链表来实现,栈顶指针就是链表的头指针 ,如图所示: 代码如下: ...
- 数据结构——链栈(link stack)
/* linkStack.c */ /* 链栈 */ #include <stdio.h> #include <stdlib.h> #include <stdbool.h ...
- 数据结构 - 链栈的实现 C++
链栈封装 C++ 使用C++对链栈进行了简单的封装,实现了栈的基本操作 封装方法: pop(),top(),size(),empty(),push() 代码已经过测试 #pragma once #in ...
- C#数据结构-链栈
上一篇我们通过数组结构实现了栈结构(准确的说是栈的顺序存储结构),现在我们通过链(单链)存储栈,也就是链栈. 通常对于正向单链表来说,是从头节点开始,在链的尾部附加节点,前一个节点的指针指向附加节点: ...
- 数据结构 - 链队列的实行(C语言)
数据结构-链队列的实现 1 链队列的定义 队列的链式存储结构,其实就是线性表的单链表,只不过它只能尾进头出而已, 我们把它简称为链队列.为了操作上的方便,我们将队头指针指向链队列的头结点,而队尾指针指 ...
- 数据结构 - 顺序栈的实行(C语言)
数据结构-顺序栈的实现 1 顺序栈的定义 既然栈是线性表的特例,那么栈的顺序存储其实也是线性表顺序存储的简化,我们简称为顺序栈.线性表是用数组来实现的,对于栈这种只能一头插入删除的线性表来说,用数组哪 ...
- 算法与数据结构(二) 栈与队列的线性和链式表示(Swift版)
数据结构中的栈与队列还是经常使用的,栈与队列其实就是线性表的一种应用.因为线性队列分为顺序存储和链式存储,所以栈可以分为链栈和顺序栈,队列也可分为顺序队列和链队列.本篇博客其实就是<数据结构之线 ...
- C语言实现链栈以及基本操作
链栈,即用链表实现栈存储结构.链栈的实现思路同顺序栈类似,顺序栈是将数顺序表(数组)的一端作为栈底,另一端为栈顶:链栈也如此,通常我们将链表的头部作为栈顶,尾部作为栈底,如下下图所示: 将链表头部作为 ...
随机推荐
- Javascript小数取整方法收集
1.丢弃小数部分,保留整数部分 parseInt(7/2) 2.向上取整,有小数就整数部分加1 Math.ceil(7/2) 3.四舍五入 Math.round(7/2) 4.向下取整 Math.fl ...
- dubbo-admin安装和使用
更新下链接,不知道是不是这个项目合入Apache的缘故,链接都变成了https://github.com/apache/incubator-dubbo/ 按照常理,直接去 https://github ...
- 【Nginx】惊群问题
转自:江南烟雨 惊群问题的产生 在建立连接的时候,Nginx处于充分发挥多核CPU架构性能的考虑,使用了多个worker子进程监听相同端口的设计,这样多个子进程在accept建立新连接时会有争抢,这会 ...
- react-redux 之 provider 和 connect
1.Provider 提供的是一个顶层容器的作用,实现store的上下文传递 2.connect 可以把state和dispatch绑定到react组件,使得组件可以访问到redux的数据 react ...
- debug找到source lookup path以及,debug跑到另外的解决办法
在我们使用eclipse调试的时候,有时候会出一些奇葩的问题,比如找不到Source lookup path, 这时我们可以点击Edit Source Lookup Path.接着回弹出一个 我们只 ...
- css的白富美
1,CSS(Cascading Style Sheet)是用来装饰HTML的,当浏览器读到这样一个样式的时候,它就会按照这个文档进行格式化(渲染) 2,CSS的组成:选择器和声明,声明又包括属性和属性 ...
- apache httpd 2.4 httpd
This is a wiki containing user-contributed recipes, tips, and tricks for the Apache HTTP Server (aka ...
- android stdio 异常
1.android studio gradle project sync failed File -> Settings 搜索Gradle 2.eqmu-system-i386未响应 分辨率 ...
- c# 32位机和64位机 读取Excel内容到DataSet
// ----------------------32位机 //注释说明 //ExclePath 为Excel路径 批号 是指Excel文件中某一列必填项 public static DataSet ...
- wpa_supplicant - 强有力的终端 wifi 配置工具【转】
本文转载自:http://rickgray.me/2015/08/03/useful-command-tool-for-wifi-connection.html 最近网购了一套Raspberry-Pi ...