SQL中查询语句的使用
常用SQL查询语句 - myLittleGarden - 博客园 http://www.cnblogs.com/sunada2005/p/3411873.html
一、简单查询语句
1. 查看表结构
SQL>DESC emp;
2. 查询所有列
SQL>SELECT * FROM emp;
3. 查询指定列
SQL>SELECT empmo, ename, mgr FROM emp;
SQL>SELECT DISTINCT mgr FROM emp; 只显示结果不同的项
4. 查询指定行
SQL>SELECT * FROM emp WHERE job='CLERK';
5. 使用算术表达式
SQL>SELECT ename, sal*13+nvl(comm,0) FROM emp;
nvl(comm,1)的意思是,如果comm中有值,则nvl(comm,1)=comm; comm中无值,则nvl(comm,1)=0。
SQL>SELECT ename, sal*13+nvl(comm,0) year_sal FROM emp; (year_sal为别名,可按别名排序)
SQL>SELECT * FROM emp WHERE hiredate>'01-1月-82';
6. 使用like操作符(%,_)
%表示一个或多个字符,_表示一个字符,[charlist]表示字符列中的任何单一字符,[^charlist]或者[!charlist]不在字符列中的任何单一字符。
SQL>SELECT * FROM emp WHERE ename like 'S__T%';
7. 在where条件中使用In
SQL>SELECT * FROM emp WHERE job IN ('CLERK','ANALYST');
8. 查询字段内容为空/非空的语句
SQL>SELECT * FROM emp WHERE mgr IS/IS NOT NULL;
9. 使用逻辑操作符号
SQL>SELECT * FROM emp WHERE (sal>500 or job='MANAGE') and ename like 'J%';
10. 将查询结果按字段的值进行排序
SQL>SELECT * FROM emp ORDER BY deptno, sal DESC; (按部门升序,并按薪酬降序)
二、复杂查询
1. 数据分组(max,min,avg,sum,count)
SQL>SELECT MAX(sal),MIN(age),AVG(sal),SUM(sal) from emp;
SQL>SELECT * FROM emp where sal=(SELECT MAX(sal) from emp));
SQL>SELEC COUNT(*) FROM emp;
2. group by(用于对查询结果的分组统计) 和 having子句(用于限制分组显示结果)
SQL>SELECT deptno,MAX(sal),AVG(sal) FROM emp GROUP BY deptno;
SQL>SELECT deptno, job, AVG(sal),MIN(sal) FROM emp group by deptno,job having AVG(sal)<2000;
对于数据分组的总结:
a. 分组函数只能出现在选择列表、having、order by子句中(不能出现在where中)
b. 如果select语句中同时包含有group by, having, order by,那么它们的顺序是group by, having, order by。
c. 在选择列中如果有列、表达式和分组函数,那么这些列和表达式必须出现在group by子句中,否则就是会出错。
使用group by不是使用having的前提条件。
3. 多表查询
SQL>SELECT e.name,e.sal,d.dname FROM emp e, dept d WHERE e.deptno=d.deptno order by d.deptno;
SQL>SELECT e.ename,e.sal,s.grade FROM emp e,salgrade s WHER e.sal BETWEEN s.losal AND s.hisal;
4. 自连接(指同一张表的连接查询)
SQL>SELECT er.ename, ee.ename mgr_name from emp er, emp ee where er.mgr=ee.empno;
5. 子查询(嵌入到其他sql语句中的select语句,也叫嵌套查询)
5.1 单行子查询
SQL>SELECT ename FROM emp WHERE deptno=(SELECT deptno FROM emp where ename='SMITH');查询表中与smith同部门的人员名字。因为返回结果只有一行,所以用“=”连接子查询语句
5.2 多行子查询
SQL>SELECT ename,job,sal,deptno from emp WHERE job IN (SELECT DISTINCT job FROM emp WHERE deptno=10);查询表中与部门号为10的工作相同的员工的姓名、工作、薪水、部门号。因为返回结果有多行,所以用“IN”连接子查询语句。
in与exists的区别: exists() 后面的子查询被称做相关子查询,它是不返回列表的值的。只是返回一个ture或false的结果,其运行方式是先运行主查询一次,再去子查询里查询与其对 应的结果。如果是ture则输出,反之则不输出。再根据主查询中的每一行去子查询里去查询。in()后面的子查询,是返回结果集的,换句话说执行次序和 exists()不一样。子查询先产生结果集,然后主查询再去结果集里去找符合要求的字段列表去。符合要求的输出,反之则不输出。
5.3 使用ALL
SQL>SELECT ename,sal,deptno FROM emp WHERE sal> ALL (SELECT sal FROM emp WHERE deptno=30);或SQL>SELECT ename,sal,deptno FROM emp WHERE sal> (SELECT MAX(sal) FROM emp WHERE deptno=30);查询工资比部门号为30号的所有员工工资都高的员工的姓名、薪水和部门号。以上两个语句在功能上是一样的,但执行效率上,函数会高 得多。
5.4 使用ANY
SQL>SELECT ename,sal,deptno FROM emp WHERE sal> ANY (SELECT sal FROM emp WHERE deptno=30);或SQL>SELECT ename,sal,deptno FROM emp WHERE sal> (SELECT MIN(sal) FROM emp WHERE deptno=30);查询工资比部门号为30号的任意一个员工工资高(只要比某一员工工资高即可)的员工的姓名、薪水和部门号。以上两个语句在功能上是 一样的,但执行效率上,函数会高得多。
5.5 多列子查询
SQL>SELECT * FROM emp WHERE (job, deptno)=(SELECT job, deptno FROM emp WHERE ename='SMITH');
5.6 在from子句中使用子查询
SQL>SELECT emp.deptno,emp.ename,emp.sal,t_avgsal.avgsal FROM emp,(SELECT emp.deptno,avg(emp.sal) avgsal FROM emp GROUP BY emp.deptno) t_avgsal where emp.deptno=t_avgsal.deptno AND emp.sal>t_avgsal.avgsal ORDER BY emp.deptno;
5.7 分页查询
数据库的每行数据都有一个对应的行号,称为rownum.
SQL>SELECT a2.* FROM (SELECT a1.*, ROWNUM rn FROM (SELECT * FROM emp ORDER BY sal) a1 WHERE ROWNUM<=10) a2 WHERE rn>=6;
指定查询列、查询结果排序等,都只需要修改最里层的子查询即可。
5.8 用查询结果创建新表
SQL>CREATE TABLE mytable (id,name,sal,job,deptno) AS SELECT empno,ename,sal,job,deptno FROM emp;
5.9 合并查询(union 并集, intersect 交集, union all 并集+交集, minus差集)
SQL>SELECT ename, sal, job FROM emp WHERE sal>2500 UNION(INTERSECT/UNION ALL/MINUS) SELECT ename, sal, job FROM emp WHERE job='MANAGER';
合并查询的执行效率远高于and,or等逻辑查询。
5.10 使用子查询插入数据
SQL>CREATE TABLE myEmp(empID number(4), name varchar2(20), sal number(6), job varchar2(10), dept number(2)); 先建一张空表;
SQL>INSERT INTO myEmp(empID, name, sal, job, dept) SELECT empno, ename, sal, job, deptno FROM emp WHERE deptno=10; 再将emp表中部门号为10的数据插入到新表myEmp中,实现数据的批量查询。
5.11 使用了查询更新表中的数据
SQL>UPDATE emp SET(job, sal, comm)=(SELECT job, sal, comm FROM emp where ename='SMITH') WHERE ename='SCOTT';

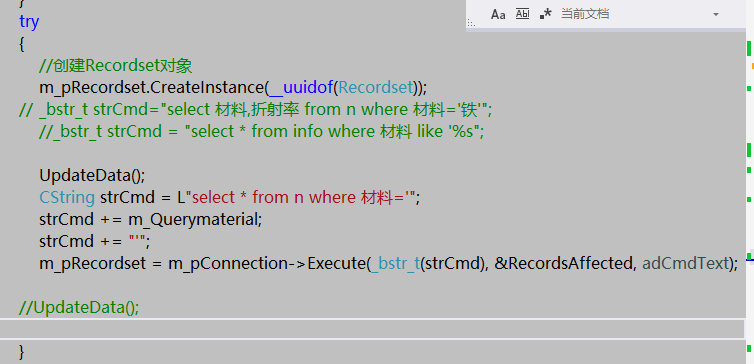
//创建Recordset对象
m_pRecordset.CreateInstance(__uuidof(Recordset));
// _bstr_t strCmd="select 材料,折射率 from n where 材料='铁'";
//_bstr_t strCmd = "select * from info where 材料 like '%s"; UpdateData();
CString strCmd = L"select * from n where 材料 like '%";
strCmd += m_Querymaterial;
strCmd += "%'";
m_pRecordset = m_pConnection->Execute(_bstr_t(strCmd), &RecordsAffected, adCmdText);
//创建Recordset对象
m_pRecordset.CreateInstance(__uuidof(Recordset));
// _bstr_t strCmd="select 材料,折射率 from n where 材料='铁'";
//_bstr_t strCmd = "select * from info where 材料 like '%s"; UpdateData();
CString strCmd = L"select * from n where 材料='";
strCmd += m_Querymaterial;
strCmd += "'";
m_pRecordset = m_pConnection->Execute(_bstr_t(strCmd), &RecordsAffected, adCmdText); //UpdateData();
SQL中查询语句的使用的更多相关文章
- 如何在SQL Server查询语句(Select)中检索存储过程(Store Procedure)的结果集?
如何在SQL Server查询语句(Select)中检索存储过程(Store Procedure)的结果集?(2006-12-14 09:25:36) 与这个问题具有相同性质的其他描述还包括:如何 ...
- SQL逻辑查询语句执行顺序 需要重新整理
一.SQL语句定义顺序 1 2 3 4 5 6 7 8 9 10 SELECT DISTINCT <select_list> FROM <left_table> <joi ...
- SQL中常见语句
SQL中常见语句笔记: --替换字段中的回车符和换行符 ) ), '') --删除表命令 DROP TABLE [dbo].[MGoods_Test] --删除表中数据命令 DELETE FROM [ ...
- ORACLE中查询语句的执行顺及where部分条件执行顺序测试
Oracle中的一些查询语句及其执行顺序 原文地址:https://www.cnblogs.com/likeju/p/5039115.html 查询条件: 1)LIKE:模糊查询,需要借助两个通配符, ...
- python 3 mysql sql逻辑查询语句执行顺序
python 3 mysql sql逻辑查询语句执行顺序 一 .SELECT语句关键字的定义顺序 SELECT DISTINCT <select_list> FROM <left_t ...
- mysql第四篇--SQL逻辑查询语句执行顺序
mysql第四篇--SQL逻辑查询语句执行顺序 一.SQL语句定义顺序 SELECT DISTINCT <select_list> FROM <left_table> < ...
- SQLServer2005中查询语句的执行顺序
SQLServer2005中查询语句的执行顺序 --1.from--2.on--3.outer(join)--4.where--5.group by--6.cube|rollup--7.havin ...
- 【SQL】查询语句中in和exists的区别
in in可以分为三类: 一. 形如select * from t1 where f1 in ( &apos:a &apos:, &apos:b &apos:),应该和 ...
- SQL Server SQL高级查询语句小结(转)
--select select * from student; --all 查询所有 select all sex from student; --distinct 过滤重复 select disti ...
随机推荐
- SQL server插入数据后,如何获取自增长字段的值?
insert into Tb_People(uname,era,amount) values( '兆周','老年','10000') select @@identity --当运行完插入语句后,执行s ...
- Java IP地址字符串与BigInteger的转换, 支持IPv6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 3 ...
- centos7搭建python3并和python2共存
注意事项:1.非root帐号加上sudo2.centos7自带Python 2.7.5是不能卸载的,很多系统级软件依赖这个 安装依赖# yum -y groupinstall "Develo ...
- JavaScript高级 面向对象(4)--值类型和引用类型
说明(2017.3.30): 1. 变量只存数据本身就是值类型,如var a = 123, var a = "123"; 变量存的是一个引用,数据存在别的地方,就是引用类型,如数 ...
- VBA学习笔记(5)--事件,记录每次操作改动
说明(2017.3.24): 1. 记录sheet1里面的每次改动,和改动时间! 2. 不能记录大范围的删除.改动,会提示“类型不匹配” Private Sub Worksheet_Change(By ...
- kafka的分区模式?
当别人问这个问题的时候,别人肯定是想你是否看过源码.是否针对不同场景改过kafka的分区模式 这是别人最想知道的是,你的message如何负载均衡的发送给topic的partition 我们用kafk ...
- 【Unity/Kinect】使用KinectManager的一般流程
想要从Kinect读取到数据,然后使用数据,通常是以下流程: using UnityEngine; using System.Collections; /// <summary> /// ...
- 设计和开发ETL系统(一)——ETL过程综述
在这部分将按照设计和实现ETL系统的流程展开,将上一个部分的那些子系统按照提取数据.清洗和一致化.向呈现服务器提交以及管理ETL环境等四个方面进行了分类.(是不是说对ETL主要就是掌握这四个方面的内容 ...
- iOS边练边学--tableView的批量操作
一.tableView批量操作方法一:(自定义) <1>在storyboard中添加imageView控件,用来操作当cell被选中后显示图标 <2>拖线,在自定义控件类中与i ...
- GDI+(一):GDI+ 绘图基础
一.GDI+绘图基础 编写图形程序时需要使用GDI(Graphics Device Interface,图形设备接口),从程序设计的角度看,GDI包括两部分:一部分是GDI对象,另一部分是GDI函数. ...