有关索引的DMV
转自:http://www.cnblogs.com/CareySon/archive/2012/05/17/2505981.html#commentform
有关索引的DMV
1.查看那些被大量更新,却很少被使用的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, s.user_updates
, s.system_seeks + s.system_scans + s.system_lookups
AS [System usage]
INTO #TempUnusedIndexes
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempUnusedIndexes
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, s.user_updates
, s.system_seeks + s.system_scans + s.system_lookups
AS [System usage]
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND s.user_seeks = 0
AND s.user_scans = 0
AND s.user_lookups = 0
AND i.name IS NOT NULL
ORDER BY s.user_updates DESC'
SELECT TOP 20 * FROM #TempUnusedIndexes ORDER BY [user_updates] DESC
DROP TABLE #TempUnusedIndexes
结果如图:
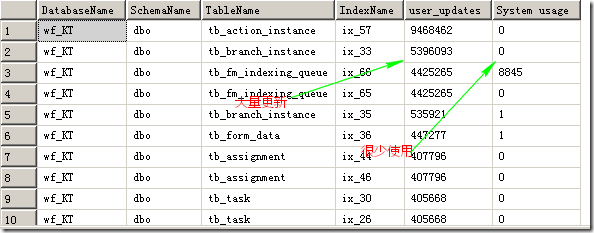
这类索引应该被Drop掉
最高维护代价的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_updates ) AS [update usage]
, (s.user_seeks + s.user_scans + s.user_lookups) AS [Retrieval usage]
, (s.user_updates) -
(s.user_seeks + s.user_scans + s.user_lookups) AS [Maintenance cost]
, s.system_seeks + s.system_scans + s.system_lookups AS [System usage]
, s.last_user_seek
, s.last_user_scan
, s.last_user_lookup
INTO #TempMaintenanceCost
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempMaintenanceCost
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_updates ) AS [update usage]
, (s.user_seeks + s.user_scans + s.user_lookups)
AS [Retrieval usage]
, (s.user_updates) -
(s.user_seeks + user_scans +
s.user_lookups) AS [Maintenance cost]
, s.system_seeks + s.system_scans + s.system_lookups AS [System usage]
, s.last_user_seek
, s.last_user_scan
, s.last_user_lookup
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
AND (s.user_seeks + s.user_scans + s.user_lookups) > 0
ORDER BY [Maintenance cost] DESC'
SELECT top 20 * FROM #TempMaintenanceCost ORDER BY [Maintenance cost] DESC
DROP TABLE #TempMaintenanceCost
结果如图:
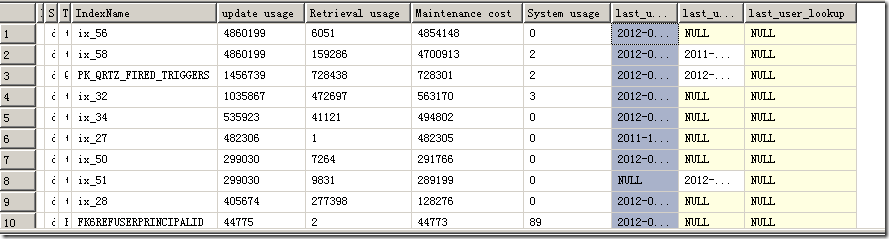
Maintenance cost高的应该被Drop掉
使用频繁的索引
--使用频繁的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_seeks + s.user_scans + s.user_lookups) AS [Usage]
, s.user_updates
, i.fill_factor
INTO #TempUsage
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempUsage
SELECT TOP 20
DB_NAME() AS DatabaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, (s.user_seeks + s.user_scans + s.user_lookups) AS [Usage]
, s.user_updates
, i.fill_factor
FROM sys.dm_db_index_usage_stats s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
ORDER BY [Usage] DESC'
SELECT TOP 20 * FROM #TempUsage ORDER BY [Usage] DESC
DROP TABLE #TempUsage
结果如图
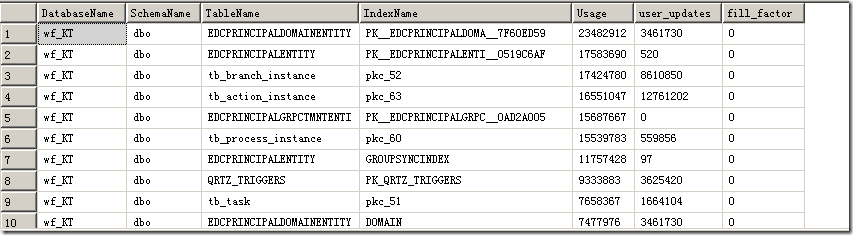
这类索引需要格外注意,不要在优化的时候干掉
碎片最多的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %]
INTO #TempFragmentation
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempFragmentation
SELECT TOP 20
DB_NAME() AS DatbaseName
, SCHEMA_NAME(o.Schema_ID) AS SchemaName
, OBJECT_NAME(s.[object_id]) AS TableName
, i.name AS IndexName
, ROUND(s.avg_fragmentation_in_percent,2) AS [Fragmentation %]
FROM sys.dm_db_index_physical_stats(db_id(),null, null, null, null) s
INNER JOIN sys.indexes i ON s.[object_id] = i.[object_id]
AND s.index_id = i.index_id
INNER JOIN sys.objects o ON i.object_id = O.object_id
WHERE s.database_id = DB_ID()
AND i.name IS NOT NULL
AND OBJECTPROPERTY(s.[object_id], ''IsMsShipped'') = 0
ORDER BY [Fragmentation %] DESC'
SELECT top 20 * FROM #TempFragmentation ORDER BY [Fragmentation %] DESC
DROP TABLE #TempFragmentation
结果如下:
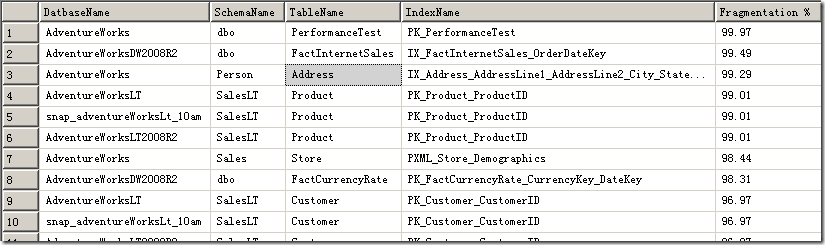
这类索引需要Rebuild,否则会严重拖累数据库性能
自上次SQL Server重启后,找出完全没有使用的索引
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(O.Schema_ID) AS SchemaName
, OBJECT_NAME(I.object_id) AS TableName
, I.name AS IndexName
INTO #TempNeverUsedIndexes
FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id
WHERE 1=2
EXEC sp_MSForEachDB 'USE [?];
INSERT INTO #TempNeverUsedIndexes
SELECT
DB_NAME() AS DatbaseName
, SCHEMA_NAME(O.Schema_ID) AS SchemaName
, OBJECT_NAME(I.object_id) AS TableName
, I.NAME AS IndexName
FROM sys.indexes I INNER JOIN sys.objects O ON I.object_id = O.object_id
LEFT OUTER JOIN sys.dm_db_index_usage_stats S ON S.object_id = I.object_id
AND I.index_id = S.index_id
AND DATABASE_ID = DB_ID()
WHERE OBJECTPROPERTY(O.object_id,''IsMsShipped'') = 0
AND I.name IS NOT NULL
AND S.object_id IS NULL'
SELECT * FROM #TempNeverUsedIndexes
ORDER BY DatbaseName, SchemaName, TableName, IndexName
DROP TABLE #TempNeverUsedIndexes
结果如图:
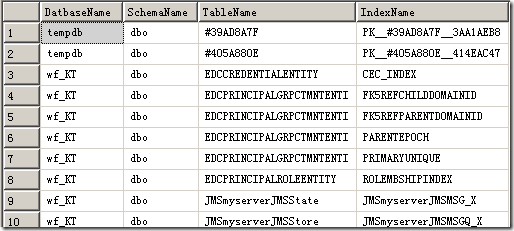
这类索引应该小心对待,不能一概而论,要看是什么原因导致这种问题
查看索引统计的相关信息
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT
ss.name AS SchemaName
, st.name AS TableName
, s.name AS IndexName
, STATS_DATE(s.id,s.indid) AS 'Statistics Last Updated'
, s.rowcnt AS 'Row Count'
, s.rowmodctr AS 'Number Of Changes'
, CAST((CAST(s.rowmodctr AS DECIMAL(28,8))/CAST(s.rowcnt AS
DECIMAL(28,2)) * 100.0)
AS DECIMAL(28,2)) AS '% Rows Changed'
FROM sys.sysindexes s
INNER JOIN sys.tables st ON st.[object_id] = s.[id]
INNER JOIN sys.schemas ss ON ss.[schema_id] = st.[schema_id]
WHERE s.id > 100
AND s.indid > 0
AND s.rowcnt >= 500
ORDER BY SchemaName, TableName, IndexName
结果如下:
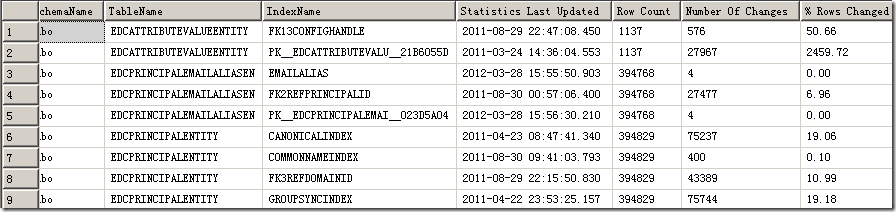
因为查询计划是根据统计信息来的,索引的选择同样取决于统计信息,所以根据统计信息更新的多寡可以看出数据库的大体状况,20%的自动更新对于大表来说非常慢。
有关索引的DMV的更多相关文章
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 有关索引的DMV(转)
转自:http://www.cnblogs.com/CareySon/archive/2012/05/17/2505981.html 1.查看那些被大量更新,却很少被使用的索引 SET TRANSAC ...
- SQL Server 索引知识-应用,维护
创建聚集索引 a索引键最好唯一(如果不唯一会隐形建立uniquier列(4字节)确保唯一,也就是这列都会复制到所有非聚集索引中) b聚集索引列所占空间应尽量小(否则也会使非聚集索引的空间变大) c聚集 ...
- EF+MVC+cod First项目性能优化总结
1.EF:this.Configuration.UseDatabaseNullSemantics = true; //关闭数据库null比较行为 2.实体必填字段要加:[Required]属性,可定长 ...
- SQL Server学习路径(文章目录)
SQL Server文章目录 SQL Server文章目录(学习路径) 转自:http://www.cnblogs.com/CareySon/archive/2012/05/08/2489748.h ...
- SQL Server数据库的软硬件性能瓶颈
在过去十年里,很多复杂的企业应用都是用Microsoft SQL Server进行开发和部署的.如今,SQL Server已经成为现代业务应用的基石,并且它还是很多大公司业务流程的核心.SQL Ser ...
- 第七章——DMVs和DMFs(2)——用DMV和DMF监控索引性能
原文:第七章--DMVs和DMFs(2)--用DMV和DMF监控索引性能 本文继续介绍使用DMO来监控,这次讲述的是监控索引性能.索引是提高查询性能的关键性手段.即使你的表上有合适的索引,你也要时时刻 ...
- 译:Missing index DMV的 bug可能会使你失去理智---慎重看待缺失索引DMV中的信息
注: 本文译自https://www.sqlskills.com/blogs/paul/missing-index-dmvs-bug-that-could-cost-your-sanity/ 原文作者 ...
- 译:SQL Server的Missing index DMV的 bug可能会使你失去理智---慎重看待缺失索引DMV中的信息
注: 本文译自https://www.sqlskills.com/blogs/paul/missing-index-dmvs-bug-that-could-cost-your-sanity/ 原文作者 ...
随机推荐
- angular 程序架构
- docker 存储驱动之 overlay2
overlay2 简介 OverlayFS是一种和AUFS很类似的文件系统,与AUFS相比,OverlayFS有以下特性: 1) 更简单地设计 2) 从3.18开始,就进入了Linux内核主线 3) ...
- Syncthing源码解析 - 第三方库
1,AudriusButkevicius/cli 网址:https://github.com/AudriusButkevicius/cli 2,bkaradzic/go-lz4 网址:https:// ...
- 关于gcd和exgcd的一点心得,保证看不懂(滑稽)
网上看了半天……还是没把欧几里得算法和扩展欧几里得算法给弄明白…… 然后想了想自己写一篇文章好了…… 参考文献:https://www.cnblogs.com/hadilo/p/5914302.htm ...
- jmeter—解决响应乱码问题
问题: 当响应数据或响应页面没有设置编码时,jmeter会按照jmeter.properties文件中,sampleresult.default.encoding 设置的格式解析默认ISO-88 ...
- vue + ElementUI 表格筛选框的高度设置,超出一定高度,显示滚动条
相信有很多小伙伴遇到过这个问题,首先还是来看图片,筛选框我做了处理,所以和官网的有点小差别 官方网站和个人网站对比图如下: 代码如下:(F12找到该元素的class,设置高度) .el-table-f ...
- Commands that may modify the data set are disabled, because this instance is configured to report errors during writes if RDB snapshotting fails (stop-writes-on-bgsave-error option)
今天运行Redis时发生错误,错误信息如下: org.springframework.dao.InvalidDataAccessApiUsageException: MISCONF Redis is ...
- oracle创建表空间、用户、权限
原链接:https://www.cnblogs.com/wxm-bk/p/6510654.html oracle 创建临时表空间/表空间,用户及授权 1:创建临时表空间 create tempor ...
- Python的垃圾回收机制以及引用计数
Python中的计数引用 在Python中,由于Python一门动态的语言,内部采用的指针形式对数据进行标记的,并不像c/c++那样,通过指定的数据类型并分配相应的数据空间,Python中定义的变量名 ...
- mysql工具——mysqlcheck(MYISAM)
基本介绍 演示: 使用optimize的时候,可能会出现 Table does not support optimize, doing recreate + analyze instead 这时候参考 ...