itembase协同过滤的详细介绍
◆版权声明:本文出自胖喵~的博客,转载必须注明出处。
转载请注明出处:https://www.cnblogs.com/by-dream/p/9016289.html
前言
通常我们在网购的时候会遇到这样的情况,当我们买了一个物品A后,网站上可能会给你推荐一些和A相似的物品。这样的推荐就是典型的协同过滤算法,今天就来给大家说说协同过滤算法。
算法概念
协调过滤算法一般有两种,一种是基于物品的,一种是基于用户的,基于物品的是itembase,基于用户的是userbase,简单来说,基于物品的是当用户购买了物品A,如果发现A和C的相似度比较高,就给用户推荐物品C,基于用户的推荐是如果用户1和用户2相似度高,用户2买了物品A而用户1没有买,那么就给用户1推荐物品A。是不是很好理解。今天我主要说说itembase。
简单的推荐
刚才讲到itembase是根据物品的相似度来进行推荐,那么怎么计算物品的相似度呢?我们看一个简单的例子。
下面是一个用户的观看电影的行为的数据:

上面的表格反应的是:
用户1看了电影 A、B;
用户2看了电影 A、C;
用户3看了电影 A、B、C;
后面的打分我们可以先忽略,因为得分都是一样的。
那么对于电影来说,被人看过的统计就是
电影A:1、2、3
电影B:1、3
电影C:2、3
这里我们利用jaccard公式(下方)来计算电影A和B的距离:

那么A和B的 jaccard = (A交B)/(A并B) = [1,3] / [1,2,3] = 2/3
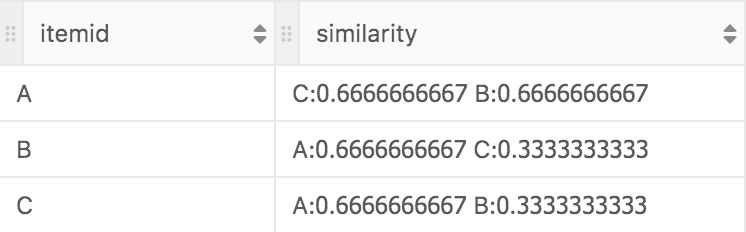
后面依次类我们可以算出A、B、C分别和另外两个jaccard系数。
这个时候,当一个用户看了电影B ,而我们要决定给他推荐电影A或者C的时候,我们就能很明显的看出来B和A之间的jaccard系数更大,固推荐电影A。
带用户打分权重的推荐
上面的流程中,不知道大家有没有注意到,我们忽略了一步,那就是用户对这个电影的打分,我们并没有用上。而现实生活中很有可能会出现这样的问题:我看了一个电影A和电影F,我对电影A打分特别低,但是电影A和电影B的相似度非常高,而我看电影F之后,我对电影F的打分相当的高,但是电影F和电影E之间的相似度是一般高(低于电影A和B的相似度),而如果我们还是用上面的算法的话,那么推荐给我的就是电影B了,而事实上我可能更想看的是电影E。那么如何解决这个问题呢,我们继续看。
这里我得用一个复杂的例子来讲解一下,假如我们有如下数据源:

首先第一步,我们需要构造一个item的同现矩阵。
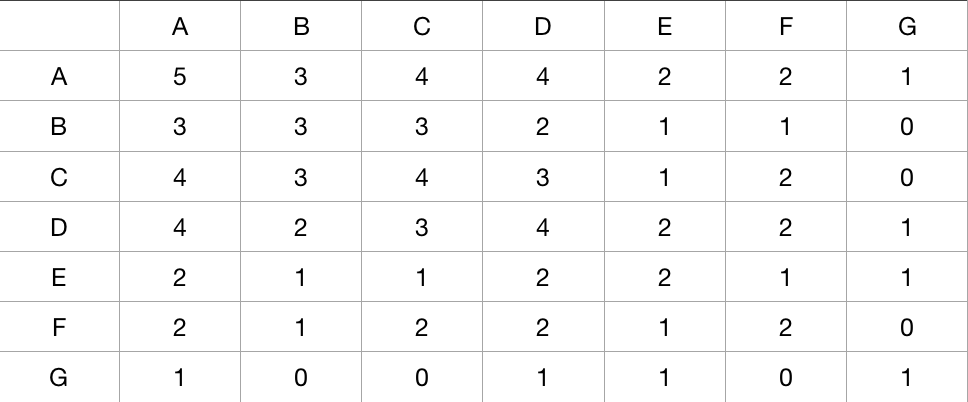
这里讲一下同现矩阵的构造方法:
[A, A] 这个地方的值代表的是 A这部电影一共出现了多少次,我们数数可以看到一共是5次,固这里值为5;
[A, B] 和 [B, A] 的值是相同的,代表的是,A和B同时被一个人观看的次数,我们可以看到用户1、2、5同时看过A和B电影,固这个值就是3;
[C, G] 类型这样的就是说,没有人同时看过C和G这两部电影。
构造完同现矩阵后,这时候,我们可以得到每一个人的打分,再构造一个评分矩阵,这里为了演示过程,我以用户4为例。
首先构造评分矩阵,这里需要注意,没有看过的电影直接记为0即可,即矩阵为:[5, 0, 3, 4.5, 0, 4, 0]
这里我们将 同现矩阵 * 评分矩阵 得到最终的得分矩阵 :

我们看下我标黑的这一列,最终的数值是 3*5+3*0+3*3+2*5+1*0+1*4+0*0 = 38,这一行代表的是B这个电影推荐给用户4的得分是38,由于我们知道用户4没有看过B、E、G,而B的得分是最高的,因此最后我们给B推荐的时候,就会优先推荐B电影。
由于同现矩阵中的数据代表是电影之间的相互权重,固在最终相乘的时候,权重高并且得分高的最终就能得到高分,这也符合推荐相似的且是用户爱看的电影。
itembase协同过滤的详细介绍的更多相关文章
- Mahout实现基于用户的协同过滤算法
Mahout中对协同过滤算法进行了封装,看一个简单的基于用户的协同过滤算法. 基于用户:通过用户对物品的偏好程度来计算出用户的在喜好上的近邻,从而根据近邻的喜好推测出用户的喜好并推荐. 图片来源 程序 ...
- Mahout 协同过滤 itemBase RecommenderJob源码分析
来自:http://blog.csdn.net/heyutao007/article/details/8612906 Mahout支持2种 M/R 的jobs实现itemBase的协同过滤 I.Ite ...
- 从item-base到svd再到rbm,多种Collaborative Filtering(协同过滤算法)从原理到实现
http://blog.csdn.net/dark_scope/article/details/17228643 〇.说明 本文的所有代码均可在 DML 找到,欢迎点星星. 一.引入 推荐系统(主要是 ...
- IO流分类详细介绍和各种字节流类介绍与使用 过滤流 字节流
Java基础笔记 – IO流分类详细介绍和各种字节流类介绍与使用 过滤流 字节流本文由 arthinking 发表于627 天前 ⁄ Java基础 ⁄ 评论数 1 ⁄ 被围观 2,036 views+ ...
- [Recommendation System] 推荐系统之协同过滤(CF)算法详解和实现
1 集体智慧和协同过滤 1.1 什么是集体智慧(社会计算)? 集体智慧 (Collective Intelligence) 并不是 Web2.0 时代特有的,只是在 Web2.0 时代,大家在 Web ...
- 【转载】协同过滤 & Spark机器学习实战
因为协同过滤内容比较多,就新开一篇文章啦~~ 聚类和线性回归的实战,可以看:http://www.cnblogs.com/charlesblc/p/6159187.html 协同过滤实战,仍然参考:h ...
- CF(协同过滤算法)
1 集体智慧和协同过滤 1.1 什么是集体智慧(社会计算)? 集体智慧 (Collective Intelligence) 并不是 Web2.0 时代特有的,只是在 Web2.0 时代,大家在 Web ...
- Mahout之(二)协同过滤推荐
协同过滤 —— Collaborative Filtering 协同过滤简单来说就是根据目标用户的行为特征,为他发现一个兴趣相投.拥有共同经验的群体,然后根据群体的喜好来为目标用户过滤可能感兴趣的内容 ...
- 协同过滤(CF)算法
1 集体智慧和协同过滤 1.1 什么是集体智慧(社会计算)? 集体智慧 (Collective Intelligence) 并不是 Web2.0 时代特有的,只是在 Web2.0 时代,大家在 Web ...
随机推荐
- 通过html<map>标签给图片加链接
前面我们有谈到了通过图片定位给一张图片添加多个链接,现在用另外一种方法来实现,用html<map>标签给图片加链接 <img src="/images/hlj.jpg&qu ...
- [Err]1418 This function has none of DETERMINISTIC,NO SQL,or R
----------------------------------------------------------------------------------------------- ...
- [py][mx]实现按照课程机构排名,按照学习人数排名
原型是 实现效果 因为要按照这两个指标排名, 模型中现在还没有这2个字段(整数),所以需要修改模型. 修改模型,添加2个排序指标的字段 class CourseOrg(models.Model): . ...
- ADB 清除Android手机缓存区域日志
原文地址http://blog.csdn.net/u013166958/article/details/79096221 Android系统的不同部分提供了四个不同log缓存区: /dev/log/m ...
- 20145202马超 2016-2017-2 《Java程序设计》第8周学习总结
20145202马超 2016-2017-2 <Java程序设计>第8周学习总结 教材学习内容总结 第十四章 NIO与NIO2 NIO使用频道(channel)来衔接数据节点,对数据区的标 ...
- this指向 - Node环境
1.全局上下文中 this /* 1.全局上下文中的 this node环境下: 严格模式下: {} {} 报错 非严格模式下:{} {} {} */ 'use strict'; // 严格模式 // ...
- 免费美女视频聊天,多人视频会议功能加强版本(Fms3和Flex开发(附源码))
Flex,Fms3系列文章导航 Flex,Fms3相关文章索引 本篇是视频聊天,会议开发实例系列文章的第4篇,该系列所有文章链接如下: http://www.cnblogs.com/aierong/a ...
- Http请求中Content-Type
1. Content-Type MediaType,即是Internet Media Type,互联网媒体类型:也叫做MIME类型,在Http协议消息头中,使用Content-Type来表示具体请求 ...
- 学习java的一点体会
在这几天的做实验.读书.写笔记的过程中我发现一个问题,就是我的知识面太窄,就比如说,学的知识都是一块一块的,没有能力去把它串起来,虽然学的很快,也写笔记总结,但马上就忘了,我想java是一个体系,需要 ...
- 2017-2018-1 JaWorld 第八周作业
2017-2018-1 JaWorld 第八周作业 团队分工 成员 分工 陈是奇 统计成员工具选择 马平川 类图 王译潇 编码规范 李昱兴 用例图 林臻 状态图 张师瑜 推进工作进展.写博客 UML ...