大数据Hadoop的HA高可用架构集群部署
1 概述
在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持NameNode的HA高可用,NameNode的高可用是通过集群中冗余两个NameNode,并且这两个NameNode分别部署到不同的服务器中,其中一个NameNode处于Active状态,另外一个处于Standby状态,如果主NameNode出现故障,那么集群会立即切换到另外一个NameNode来保证整个集群的正常运行,那么接下来本文将重要介绍该如何搭建Hadoop的HA集群。
该环境是在 大数据平台Hadoop的分布式集群环境搭建 的基础上完成的
2 集群HA部署节点列表
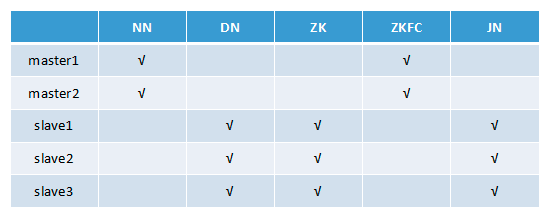
注:Hadoop版本: Hadoop 2.7.5
NN(NameNode 名称节点)、DN(DataNode 数据节点)、ZK(Zookeeper)、ZKFC(ZKFailoverController)、JN(JournalNode 元数据共享节点)、RM(ResourceManager 资源管理器)、DM(DataManager 数据节点管理器)

3 安装Zookeeper集群
(1) 首先在slave1中安装
a)下载zookeeper-3.4.9.tar.gz包
b)解压:tar -zxvf zookeeper-3.4.9.tar.gz
c)cd zookeeper-3.4.9/conf
d)cp zoo_sample.cfg zoo.cfg
e)修改zoo.cfg配置文件
tickTime=2000
dataDir=/home/hadoop/app/zookeeper/data
clientPort=2181
initLimit=10
syncLimit=5
server.1=slave1:2888:3888
server.2=slave2:2888:3888
server.3=slave3:2888:3888(2)拷贝相同的一份zookeeper-3.4.9到slave2、slave3服务
(3)配置Zookeeper的环境变量并分别启动即可完成Zookeeper集群的部署
4 开始配置
(1)修改hdfs-site.xml,内容如下:
<configuration>
<!--HDFS HA的逻辑服务名称配置-->
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
<!--NameNode的唯一标识服务名,注意这里namenodes.masters中的masters必须是上面的dfs.nameservices中的逻辑服务名,下面同理-->
<property>
<name>dfs.ha.namenodes.masters</name>
<value>master1,master2</value>
</property>
<!--NameNode的rpc监听地址-->
<property>
<name>dfs.namenode.rpc-address.masters.master1</name>
<value>master1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.masters.master2</name>
<value>master2:8020</value>
</property>
<!--NameNode的http地址配置-->
<property>
<name>dfs.namenode.http-address.masters.master1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.masters.master2</name>
<value>master2:50070</value>
</property>
<!--NameNode的edits文件的共享地址配置,及JournalNodes的节点配置-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://slave1:8485;slave2:8485;slave3:8485/masters</value>
</property>
<!--指定JournalNode在本地磁盘存放数据的位置-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/journal</value>
</property>
<!--配置将由DFS客户端使用的Java类的名称,以确定哪个NameNode当前正在服务于客户端请求-->
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--HA切换时的免密登录的秘钥访问路径配置-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--开启NameNode失败自动切换-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--配置HDFS的DataNode的备份数量-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/hdfs/data</value>
</property>
<!--HDFS访问是否开启权限控制-->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>(2)修改core-site.xml文件,内容如下:
<configuration>
<!--这里的masters值需与hdfs-site.xml中的dfs.nameservices配置项的值相同-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<!-- 配置hadoop的临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-HA/data/tmp</value>
</property>
<!--Zookeeper服务配置-->
<property>
<name>ha.zookeeper.quorum</name>
<value>slave1:2181,slave2:2181,slave3:2181</value>
</property>
<!--表示客户端连接服务器失败尝试的次数-->
<property>
<name>ipc.client.connect.max.retries</name>
<value>10</value>
</property>
<!--表示客户端每次连接服务器需要等待的毫秒数,默认1s,如不配置则使用start-dfs.sh启动可能会导致NameNode连接JournalNode超时,如果单独一个个节点启动则无需此配置项-->
<property>
<name>ipc.client.connect.retry.interval</name>
<value>10000</value>
</property>
</configuration>(3)修改slaves文件,内容如下:
slave1
slave2
slave35 初始化集群和启动
(1)分别启动三个JournalNode
$hadoop-daemon.sh start journalnode(2)在其中一个NameNode节点中初始化NameNode,这里选择master1上的NameNode
$hdfs namenode -format(3)启动第2步初始化好的NameNode服务
$hadoop-daemon.sh start namenode(4)在master2服务器中运行下面命令来同步master1上的NameNode的元数据
$hdfs namenode -bootstrapStandby(5)在其中一个NameNode节点中初始化ZKFC的状态,这里选择master1上的NameNode
$hdfs zkfc -formatZK(6)启动Hadoop的HA集群
$start-dfs.sh6 测试是否切换成功
(1)通过浏览器中查看 http:master1:50070 和 http:master2:50070 可以确定哪个NameNode处理激活状态
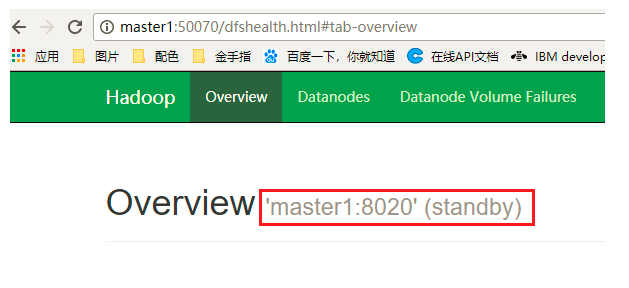
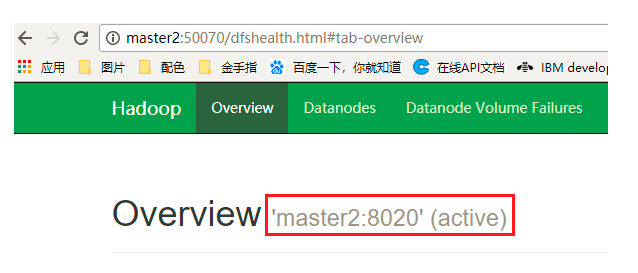
(2)如上图master2的状态为active,则通过kill杀死master2中的NameNode进程,然后查看master1中的NameNode是否由standby状态转换为了active状态,是的话说明切换成功!
注:在测试Hadoop的HA切换中,发现切换失败,在kill掉NameNode的节点中查看日志:
vi hadoop-2.7.5/logs/hadoop-hadoop-zkfc-master2.log
发现报错:PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8020 via ssh: bash: fuser: 未找到命令
解决办法:缺少psmisc依赖包,每个NameNode节点服务器上安装即可:
yum install psmisc
大数据Hadoop的HA高可用架构集群部署的更多相关文章
- 大数据技术之HA 高可用
HDFS HA高可用 1.1 HA概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件的HA ...
- 大数据学习笔记——Hbase高可用+完全分布式完整部署教程
Hbase高可用+完全分布式完整部署教程 本篇博客承接上一篇sqoop的部署教程,将会详细介绍完全分布式并且是高可用模式下的Hbase的部署流程,废话不多说,我们直接开始! 1. 安装准备 部署Hba ...
- openstack高可用集群21-生产环境高可用openstack集群部署记录
第一篇 集群概述 keepalived + haproxy +Rabbitmq集群+MariaDB Galera高可用集群 部署openstack时使用单个控制节点是非常危险的,这样就意味着单个节 ...
- 搭建Hadoop的HA高可用架构(超详细步骤+已验证)
一.集群的规划 Zookeeper集群: 192.168.182.12 (bigdata12)192.168.182.13 (bigdata13)192.168.182.14 (bigdata14) ...
- MongoDB高可用架构集群管理(一)
MongoDB数据库核心的两个特点:第一个特点是副本集的自动切换,保证数据的高可靠.服务的高可用:第二个特点是自动分片.服务的横向扩展能力. (一)副本集架构 MongoDB的副本集是一组保持相同数据 ...
- hadoop3.1.1 HA高可用分布式集群安装部署
1.环境介绍 涉及到软件下载地址:https://pan.baidu.com/s/1hpcXUSJe85EsU9ara48MsQ 服务器:CentOS 6.8 其中:2 台 namenode.3 台 ...
- HA 高可用mysql集群
注意问题: 1.保持mysql用户和组的ID号是一致的: 2.filesystem 共享存储必须要有写入权限: 3.删除资源必须先删除约束,在删除资源: 1.安装数据库,这里使用maridb数据库: ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
- [转]搭建高可用mongodb集群(四)—— 分片
按照上一节中<搭建高可用mongodb集群(三)—— 深入副本集>搭建后还有两个问题没有解决: 从节点每个上面的数据都是对数据库全量拷贝,从节点压力会不会过大? 数据压力大到机器支撑不了的 ...
随机推荐
- EXP-00032: Non-DBAs may not export other users
Connected to: Oracle Database 10g Enterprise Edition Release 10.2.0.4.0 - 64bit ProductionWith the P ...
- vi编辑器的命令详情
选定文本块,使用v复制选定块到缓冲区,使用y复制整行,用yy在同一编辑窗打开第二个文件,用:sp [filename]在多个编辑文件之间切换,用^ww剪切块,用d剪切整行用dd粘贴缓冲区中的内容,用p ...
- yarn-site.xml
要保证spark on yarn的稳定性,避免报错,就必须保证正确的配置,尤其是yarn-site.xml. 首先来理解一下yarn-site.xml各个参数的意义(引自董的博客) 注:下面<v ...
- canvas学习笔记1
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- Webserver管理系列:12、开启关闭Ping命令
有些时候站点打开速度会非常慢,我们要排查故障所在.须要用到Ping命令.可是Windows Server 2008防火墙默认是关闭Ping的 我们能够通过下面方法开启Ping 打开防火墙->高级 ...
- TTransport 概述
TTransport TTransport主要作用是定义了IO读写操作以及本地缓存的操作,下面来看TIOStreamTransport是如何实现的. public abstract class TTr ...
- gluoncv 训练自己的数据集,进行目标检测
跑了一晚上的模型,实在占GPU资源,这两天已经有很多小朋友说我了.我选择了其中一个参数. https://github.com/dmlc/gluon-cv/blob/master/scripts/de ...
- Linux环境搭建多项目SVN
1.安装SVN #yum install subversion 2.创建版本库文件夹 #mkdir -p /var/svn/repos/pro1 (/var/svn/repos是根路径,pro1是项目 ...
- 20155203 2016-2017-4 《Java程序设计》第9周学习总结
20155203 2016-2017-4 <Java程序设计>第9周学习总结 教材学习内容总结 课堂内容 两个类如果有公共的部分要放在父类中,多次复用.当我们用父类或接口去声明对象的引用生 ...
- 通讯协议(一)HTTP协议
协议是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则,超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送到客户端的浏览器.目前我们使 ...