mongodb聚合 group
MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。有点类似sql语句中的 count(*)。
基本语法为:db.collection.aggregate( [ <stage1>, <stage2>, ... ] )
现在在mycol集合中有以下数据:
{ "_id" : 1, "name" : "tom", "sex" : "男", "score" : 100, "age" : 34 } { "_id" : 2, "name" : "jeke", "sex" : "男", "score" : 90, "age" : 24 } { "_id" : 3, "name" : "kite", "sex" : "女", "score" : 40, "age" : 36 } { "_id" : 4, "name" : "herry", "sex" : "男", "score" : 90, "age" : 56 } { "_id" : 5, "name" : "marry", "sex" : "女", "score" : 70, "age" : 18 } { "_id" : 6, "name" : "john", "sex" : "男", "score" : 100, "age" : 31 }
1、$sum 计算总和。
Sql: select sex,count(*) from mycol group by sex
MongoDb: db.mycol.aggregate([{group: {_id: '
sex', personCount: {$sum: 1}}}])

Sql: select sex,sum(score) totalScore from mycol group by sex
MongoDb: db.mycol.aggregate([{group: {_id: '
sex', totalScore: {
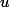



score'}}}])

2、$avg 计算平均值
Sql: select sex,avg(score) avgScore from mycol group by sex
Mongodb: db.mycol.aggregate([{group: {_id: '
sex', avgScore: {

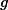
score'}}}])

3、$max 获取集合中所有文档对应值得最大值。
Sql: select sex,max(score) maxScore from mycol group by sex
Mongodb: db.mycol.aggregate([{group: {_id: '
sex', maxScore : {
score'}}}])

4、$min 获取集合中所有文档对应值得最小值。
Sql: select sex,min(score) minScore from mycol group by sex
Mongodb: db.mycol.aggregate([{group: {_id: '
sex', minScore : {
score'}}}])

5、$push 把文档中某一列对应的所有数据插入值到一个数组中。
Mongodb: db.mycol.aggregate([{group: {_id: '
sex', scores : {
score'}}}])

6、$addToSet 把文档中某一列对应的所有数据插入值到一个数组中,去掉重复的
db.mycol.aggregate([{group: {_id: '
sex', scores : {
score'}}}])

7、 $first 根据资源文档的排序获取第一个文档数据。
db.mycol.aggregate([{group: {_id: '
sex', firstPerson : {
name'}}}])

8、 $last 根据资源文档的排序获取最后一个文档数据。
db.mycol.aggregate([{group: {_id: '
sex', lastPerson : {
name'}}}])

9、全部统计 null
db.mycol.aggregate([{group:{_id:null,totalScore:{
push:'$score'}}}])

例子
现在在t2集合中有以下数据:
{ "country" : "china", "province" : "sh", "userid" : "a" } { "country" : "china", "province" : "sh", "userid" : "b" } { "country" : "china", "province" : "sh", "userid" : "a" } { "country" : "china", "province" : "sh", "userid" : "c" } { "country" : "china", "province" : "bj", "userid" : "da" } { "country" : "china", "province" : "bj", "userid" : "fa" }
需求是统计出每个country/province下的userid的数量(同一个userid只统计一次)
过程如下。
首先试着这样来统计:
db.t2.aggregate([ { group: {"_id": { "country" : "
country", "prov": "province"} , "number":{
sum:1}} } ])
结果是错误的:

原因是,这样来统计不能区分userid相同的情况 (上面的数据中sh有两个 userid = a)
为了解决这个问题,首先执行一个group,其id 是 country, province, userid三个field:
db.t2.aggregate([ { group: {"_id": { "country" : "
country", "province": "
userid" } } } ])

可以看出,这步的目的是把相同的userid只剩下一个。
然后第二步,再第一步的结果之上再执行统计:
db.t2.aggregate([ { group: {"_id": { "country" : "
country", "province": " userid" } } } , { group: {"_id": { "country" : "_id.country", "province": "_id.province" }, count : {
sum : 1 } } } ])
这回就对了

加入一个$project操作符,把_id去掉
db.t2.aggregate([ { group: {"_id": { "country" : "
country", "province": " userid" } } } , { group: {"_id": { "country" : "_id.country", "province": "_id.province" }, count: {sum : 1 } } }, { project : {"_id": 0, "country" : "
_id.country", "province" : "$_id.province", "count" : 1}} ])
最终结果如下:

管道的概念
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数。
MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
表达式:处理输入文档并输出。表达式是无状态的,只能用于计算当前聚合管道的文档,不能处理其它的文档。
这里我们介绍一下聚合框架中常用的几个操作:
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
:用于过滤数据,只输出符合条件的文档。
- match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
1、$project实例
db.mycol.aggregate({$project:{name : 1, score : 1}})
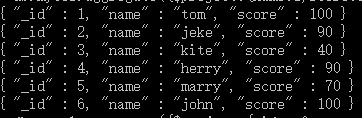
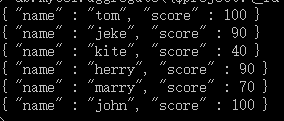
这样的话结果中就只还有_id,name和score三个字段了,默认情况下_id字段是被包含的,如果要想不包含_id话可以这样:
db.mycol.aggregate({$project:{_id : 0, name : 1, score : 1}})
2、$match实例
用于获取分数大于
小于并且小于
的记录,然后将符合条件的记录送到下一阶段
group管道操作符进行处理
db.mycol.aggregate([{match :{score: {
gt: 30, lt: 100}}},{group:{_id:'sex',count:{
sum:1}}}])

mongodb聚合 group的更多相关文章
- mongodb MongoDB 聚合 group
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- mongodb MongoDB 聚合 group(转)
MongoDB 聚合 MongoDB中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果.有点类似sql语句中的 count(*). 基本语法为:db.col ...
- MongoDB 聚合Group(一)
原文:http://blog.csdn.net/congcong68/article/details/45012717 一.简介 db.collection.group()使用JavaScript,它 ...
- MongoDB 聚合管道(Aggregation Pipeline)
管道概念 POSIX多线程的使用方式中, 有一种很重要的方式-----流水线(亦称为"管道")方式,"数据元素"流串行地被一组线程按顺序执行.它的使用架构可参考 ...
- Mongodb学习笔记四(Mongodb聚合函数)
第四章 Mongodb聚合函数 插入 测试数据 ;j<;j++){ for(var i=1;i<3;i++){ var person={ Name:"jack"+i, ...
- 浅析mongodb中group分组
这篇文章主要介绍了浅析mongodb中group分组的实现方法及示例,非常的简单实用,有需要的小伙伴可以参考下. group做的聚合有些复杂.先选定分组所依据的键,此后MongoDB就会将集合依据选定 ...
- MongoDB 聚合
聚合操作过程中的数据记录和计算结果返回.聚合操作分组值从多个文档,并可以执行各种操作,分组数据返回单个结果.在SQL COUNT(*)和group by 相当于MongoDB的聚集. aggregat ...
- MongoDB聚合
--------------------MongoDB聚合-------------------- 1.aggregate(): 1.概念: 1.简介 ...
- MongoDB 聚合分组取第一条记录的案例及实现
关键字:MongoDB: aggregate:forEach 今天开发同学向我们提了一个紧急的需求,从集合mt_resources_access_log中,根据字段refererDomain分组,取分 ...
随机推荐
- adb connect 192.168.1.10 failed to connect to 192.168.1.10:5555
adb connect 192.168.1.10 输出 failed to connect to 关闭安卓端Wi-Fi,重新打开连接即可
- tp5.1报错 页面错误!请稍后再试
修改框架中convention.php // 应用调试模式 'app_debug' => true, 修改app.php不一定有效.
- 如何优雅地发布Hexo博客
前言 就目前而言,我所知道的发布Hexo的博客有如下几种: 1.原始方式,也就是在服务器上编写md文件,然后利用hexo g来生成,详见:hexo从零开始到搭建完整: 2.利用github+hook来 ...
- QWebEngineView_CssVariables
1.测试代码,参考网址:http://blog.sina.com.cn/s/blog_1508519340102wgq0.html 2.测试下来,结果: 2.1.Qt5.6开始,没有 WebKit了. ...
- Java Spring-注解进行属性注入
2017-11-06 21:19:43 一.Spring的注解装配BeanSpring2.5 引入使用注解去定义Bean @Component 描述Spring框架中Bean Spring的框架中提供 ...
- 如何以Root权限在Pycharm上Run、Debug
Pycharm官网提问:https://intellij-support.jetbrains.com/hc/en-us/community/posts/206587695-How-to-run-deb ...
- 个人知识管理系统Version1.0开发记录(12)
最近碰到个问题,在五个工作日内阅读一个百万行左右代码量的新项目集合,如何解决呢? 第一个工作日,环境观察.待在那个项目组,看项目成员们在做些什么事情,开发,测试,聊天,或多或少可以收集到一些项目相关的 ...
- 知识梳理——CSS篇
css引入方法 内嵌 <head> <meta charset="UTF-8"> <title>Document</title> & ...
- 转载:【Oracle 集群】RAC知识图文详细教程(八)--Oracle 11G RAC数据库安装
文章导航 集群概念介绍(一) ORACLE集群概念和原理(二) RAC 工作原理和相关组件(三) 缓存融合技术(四) RAC 特殊问题和实战经验(五) ORACLE 11 G版本2 RAC在LINUX ...
- Artix-7 50T FPGA试用笔记之Create a simple MicroBlaze System
前言:之前笔者的试用博文提到安富利这块板子非常适合MicroBlaze开发,同时网上关于MicroBlaze的资料非常少(或含糊不清),没有一篇能完整介绍VIVADO SDK的设计流程,所以笔者带来这 ...