在Ubuntu14.04操作系统的宿主机中,安装docker17.06.3,将宿主机的操作系统制作成docker基础镜像,之后使用自制的基础镜像在docker中启动3个容器,分配固定IP,再在3个容器中配置solrCloud集群。
关键点:docker17.06.3安装,docker自制镜像及相关容器操作,docker分配固定IP及添加端口映射,solrCloud集群部署等
注:solrCloud采用的solr内置jetty,需要单独配置zookeeper
容器IP及名称见下表:
|
编号
|
静态IP
|
容器名称
|
|
1
|
172.18.0.11
|
server1
|
|
2
|
172.18.0.12
|
server2
|
|
3
|
172.18.0.13
|
server3
|
一、在宿主机安装docker最新版
1.更新apt-get
apt-get update
2.安装curl工具
apt-get install curl
3.获取并安装docker最新版
curl -fsSL https://get.docker.com/ | sh
4.查看docker版本
docker -v
二、在宿主机制作Ubuntu14.10基础镜像ubuntu-self
1.将本机操作系统打包成tar文件
tar --numeric-owner --exclude=/proc --exclude=/sys -cvf ubuntu-self.tar /
2.将制作的tar文件导入docker镜像库中,并命令为:ubuntu-self:
cat ubuntu-self.tar | docker import - ubuntu-self
3.现在可以运行它了:
docker run -i -t ubuntu-self
注:官方提供的镜像库中Ubuntu无法sudo,不太好用,这里我自己利用本机的操作系统生成了一个基础纯净版镜像,命名为ubuntu-self,大小约3.5G,里面没有安装任何软件。
三、配置宿主机的hosts文件,以便利用ssh登录容器
1.修改hosts文件,添加如下内容:
vi /etc/hosts
172.18.0.11 server1
172.18.0.12 server2
172.18.0.13 server3
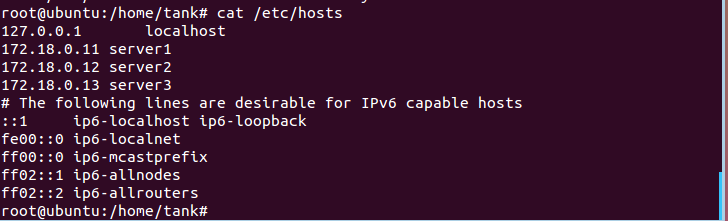
2.查看hosts文件
cat /etc/hosts
四、启动一个容器,设置静态IP,命名为server1
1.在宿主机上创建自定义网络
docker network create --subnet=172.18.0.0/16 search_network
备注:这里选取了172.18.0.0网段,也可以指定其他任意空闲的网段,search_network为自定义网桥的名字,可自己任意取名。
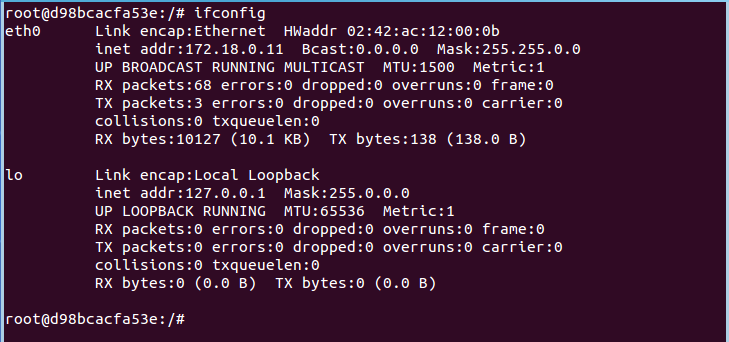
2.利用docker启动容器server1,分配固定IP 172.18.0.11,并将容器的8983端口与宿主机8983进行映射,以便可以从外部访问容器
docker run -itd --name server1 --net search_network --ip 172.18.0.11 -p 8983:8983 ubuntu-self /bin/bash
注:该命令执行完之后直接进入到server1的命令行界面,主机名称变为docker分配的随机字符串,查看ip是否为静态,执行结果如下图所示:
五、继续操作,在容器server1中配置ssh服务
1.aptget升级
apt-get update
2.安装openssh服务
apt-get install openssh-server
3.开启ssh服务
sudo /etc/init.d/ssh start
4.设置ssh开机启动
vi /etc/rc.local
添加如下内容:
service ssh start
4.退出容器,在宿主机中采用ssh登录
exit
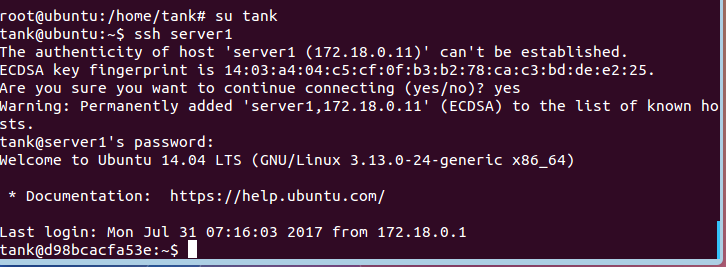
5.在宿主机切换到tank用户(root登录ssh需要修改ssh配置文件,这里用tank用户登录更方便些),并ssh到容器server1
su tank
ssh server1
六、在容器server1中安装jdk1.8并配置java环境变量
1.解压缩文件
tar -zxvf jdk1.8.0_141.tar.gz -C /usr/local/java/
2.向/etc/profile文件中追加下面内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_141
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=$PATH:${JAVA_HOME}/bin
3.让文件生效
source /etc/profile
4.验证java成功安装
java -version
七、在容器server1中安装配置zookeeper-3.4.10
1.解压zookeeper 安装包到/usr/local目录中
tar -zxvf zookeeper-3.4.10.tar.gz -C /usr/local/
2.创建zookeeper的data和logs目录,确保拥有读写权限
mkdir /home/tank/zookeeper/data
mkdir /home/tank/zookeeper/log
3.将zookeeper安装目录下conf文件夹中的zoo_sample.cfg重命名为zoo.cfg
4.修改zoo.cfg内容,zoo.cfg配置完后如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/tank/zookeeper/data
dataLogDir=/home/tank/zookeeper/log
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=172.18.0.11:2888:3888
server.2=172.18.0.12:2888:3888
server.3=172.18.0.13:2888:3888
5.进入/home/tank/zookeeper/data中,新建myid文件,写入1
注:其他两个节点的myid内容应分别是2和3
八、在容器server1中安装配置solr-6.6.0
1.解压solr-6.6.0.tgz到/usr/local目录下
tar -zxvf solr-6.6.0.tgz -C /usr/local/
2.创建solrCloud根目录solr_cloud_home文件夹
mkdir /usr/local/solrCloud/solr_cloud_home
3.复制/usr/local/solr-6.6.0/server/solr/目录下的文件到solr_cloud_home中
cp /usr/local/solr-6.6.0/server/solr/* /usr/local/solrCloud/solr_cloud_home/
查看solr_cloud_home目录,如图所示:
ls
4.创建配置存放目录solr_cloud_collection文件夹
mkdir /usr/local/solrCloud/solr_cloud_collection
5.复制/usr/local/solr-6.6.0/example/example-DIH/solr/solr/目录下的文件到solr_cloud_collection/cloud_core中
mkdir /usr/local/solr_cloud_collection/cloud_core
cp /usr/local/solr-6.6.0/example/example-DIH/solr/solr/* /usr/local/solr_cloud_collection/cloud_core/
ls
九、在宿主机提交容器server1为新的镜像,命名为ubuntu-self-solr
sudo docker commit server1 ubuntu-self-solr
docker images
十、利用上一步生成的镜像启动容器server2,server3
1.在宿主机启动容器server2,设置IP为172.18.0.12
docker run -itd --name server2 --net search_network --ip 172.18.0.12 ubuntu-self-solr /bin/bash
2.将容器server2中/home/tank/zookeeper/data/myid内容由1改为2
3.退出容器server2,回到宿主机
exit
3.在宿主机启动容器server3,设置IP为172.18.0.13
docker run -itd --name server3 --net search_network --ip 172.18.0.13 ubuntu-self-solr /bin/bash
4.将容器server3中/home/tank/zookeeper/data/myid内容由1改为3
5.退出容器server3,回到宿主机
exit
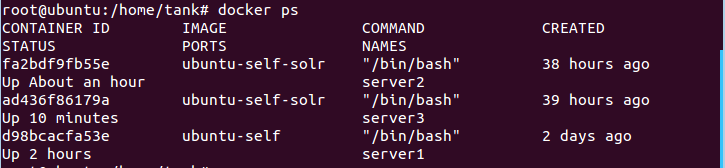
6.在宿主机中查看docker容器运行情况
docker ps
十一、在宿主机ssh登录容器server1,server2,server3 并分别启动zookeeper
ssh server1
cd /usr/local/zookeeper-3.4.10/
bin/zkServer.sh start
/usr/local/zookeeper-3.4.10/bin/zkServer.sh start
注:在server2,server3上同样执行此操作
十二、在宿主机ssh登录容器server1,server2,server3并启动solr
1.ssh登录server1,cloud模式下启动solr
ssh server1
cd /usr/local/solr-6.6.0
bin/solr start -cloud -p 8983 -s "/usr/local/solrCloud/solr_cloud_home/" -z "172.18.0.11:2181,172.18.0.12:2181,172.18.0.13:2181"
2.打开宿主机浏览器,访问页面http://172.18.0.11:8983/solr/,可以进入solr页面即代表启动成功
注:在server2,server3上同样执行此操作
十三、在容器server1上创建Collection(只需要在一台solr节点上操作)
1、由solr命令建立索引,这里索引命名为:cloudsuite_web_search
进入solr/bin目录,使用solr命令:
cd /usr/local/solr-6.6.0
bin/solr create_collection -c cloudsuite_web_search -shards 3 -replicationFactor 3 -d /usr/local/solrCloud/solr_cloud_collection/cloud_core/conf -p 8983
-c 核心名称tar
-shards 分片数量
- replicationFactor 副本数量 (一般指有几台solr集群)
2.将solr提供的xml示例文件上传至索引
bin/post -c cloudsuite_web_search *.xml
十四、在宿主机上通过浏览器访问solrCloud集群,验证操作成功
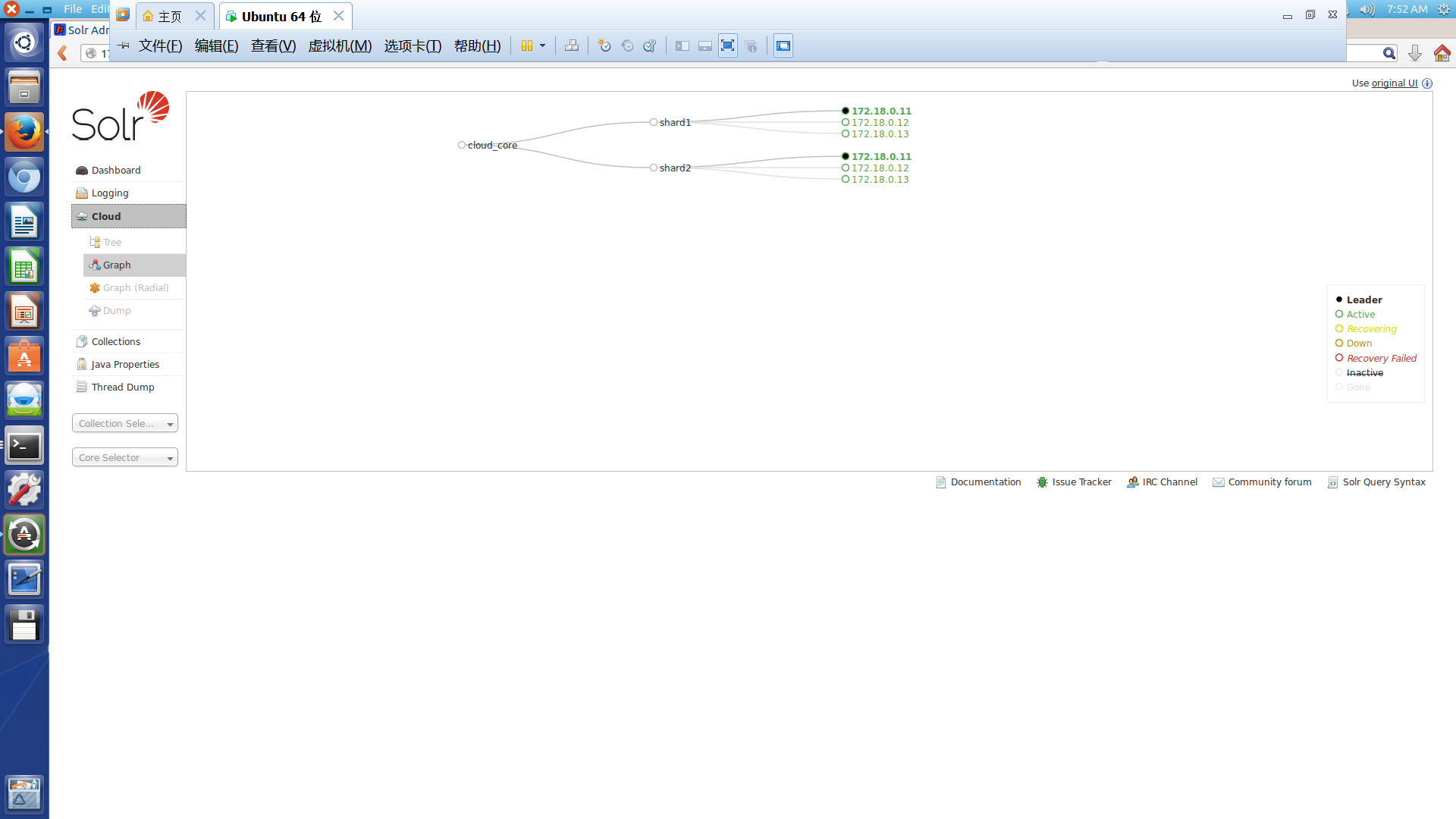
安装成功后,无论从哪个节点访问8983端口,均可以看到cloud的拓扑模式,如下所示


- linux下利用httpd搭建tomcat集群,实现负载均衡
公司使用运营管理平台是单点tomcat,使用量大,或者导出较大的运营数据时,会造成平台不可用,现在需要搭建tomcat集群,调研后,决定使用apache的httpd来搭建tomcat集群.以下是搭建步 ...
- 利用Docker搭建Redis集群
Redis集群搭建 运行Redis镜像 分别使用以下命令启动3个Redis docker run --name redis-6379 -p 6379:6379 -d hub.c.163.com/lib ...
- docker搭建etcd集群环境
其实关于集群网上说的方案已经很多了,尤其是官网,只是这里我个人只有一个虚拟机,在开发环境下建议用docker-compose来搭建etcd集群. 1.拉取etcd镜像 docker pull quay ...
- docker 搭建zookeeper集群和kafka集群
docker 搭建zookeeper集群 安装docker-compose容器编排工具 Compose介绍 Docker Compose 是 Docker 官方编排(Orchestration)项目之 ...
- 【solr】Solr5.5.4+Zookeeper3.4.6+Tomcat8搭建SolrCloud集群
Solr5.5.4+Zookeeper3.4.6+Tomcat8搭建SolrCloud集群 SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力 ...
- 使用Docker搭建Spark集群(用于实现网站流量实时分析模块)
上一篇使用Docker搭建了Hadoop的完全分布式:使用Docker搭建Hadoop集群(伪分布式与完全分布式),本次记录搭建spark集群,使用两者同时来实现之前一直未完成的项目:网站日志流量分析 ...
- 使用Docker搭建Hadoop集群(伪分布式与完全分布式)
之前用虚拟机搭建Hadoop集群(包括伪分布式和完全分布式:Hadoop之伪分布式安装),但是这样太消耗资源了,自学了Docker也来操练一把,用Docker来构建Hadoop集群,这里搭建的Hado ...
- 庐山真面目之十二微服务架构基于Docker搭建Consul集群、Ocelot网关集群和IdentityServer版本实现
庐山真面目之十二微服务架构基于Docker搭建Consul集群.Ocelot网关集群和IdentityServer版本实现 一.简介 在第七篇文章<庐山真面目之七微服务架构Consul ...
- Elasticsearch使用系列-Docker搭建Elasticsearch集群
Elasticsearch使用系列-ES简介和环境搭建 Elasticsearch使用系列-ES增删查改基本操作+ik分词 Elasticsearch使用系列-基本查询和聚合查询+sql插件 Elas ...
随机推荐
- Winform开发之窗体显示、关闭与资源释放
Winform的窗体涉及到一般窗体(单文档窗体).MDI窗体.窗体之间的关系等,那么如果调用打开新窗体.如何关闭窗体.窗体资源的释放等都关系到软件运行的效率,本文一一介绍 1.窗体的显示 从一个窗体打 ...
- Python 使用Microsoft SQL Server数据库
软件环境: Windows 7 32bit Python 3.6 Download https://www.python.org/downloads/ 默认安装,并添加环境变量,一路Next ... ...
- winodws同步时间命令
首先,你应该判断你的两台域控制器,哪一台担任PDC角色(默认的域内权威的时间服务源). 判断方法很简单,单击“开始”,单击“运行”,键入dsa.msc,然后点确定.这时会打开“Active Direc ...
- GPU 服务器环境安装中一些基础note
GPU 服务器环境安装中一些基础note GPU 服务器: 添加组,用户,并为之新建主目录. c302@c302-dl:~$ sudo addgroup testgroup Adding group ...
- CenOS中的yum配置文件CentOS-Base.repo里面的参数都是何含义? souhu CentOS-Base.repo
souhu yum服务器CentOS-Base.repo 将$releasever替换为操作系统版本号 # CentOS-Base.repo # # The mirror system uses t ...
- RK3288 device descriptor read/64, error -32
CPU:RK3288 系统:Android 5.1 主板有两个USB接口,一个接USB摄像头,一个接身份证模块. 插入摄像头可以正常打开,再插入身份证模块时,摄像头就会卡主,而且身份证模块无法识别,内 ...
- 善待Erlang 代码 -- Xref 实践
Xref 是一个交叉引用工具,通过分析定义的函数间的调用关系,用于查找函数. 模块. 应用程序和版本之间的依赖关系. 通俗而言,Xref 可以检查代码中函数的调用关系.比如在 moduleA 中的 f ...
- 安卓控件获取器uiautomatorviewer初体验:"unable to connect to the adb. check if adb is installed correctly"
解决方法:转自:https://plus.google.com/108487870030743970488/posts/2TrMqs1ZGQv Challenge Accepted:1. Screen ...
- 1 预备知识--Hadoop简介
1 预备知识--Hadoop简介 Hadoop是Apache的一个开源的分布式计算平台,以HDFS分布式文件系统和MapReduce分布式计算框架为核心,为用户提供了一套底层透明的分布式基础设施Had ...
- servlet的登陆案例
Users.java package com.po; public class Users { private String username; private String password; pu ...