推荐算法——距离算法
迁移到:http://www.bdata-cap.com/newsinfo/1741432.html
本文内容
- 用户评分表
- 曼哈顿(Manhattan)距离
- 欧式(Euclidean)距离
- 余弦相似度(cos simliarity)
推荐算法以及数据挖掘算法,计算“距离”是必须的~最近想搭一个推荐系统,看了一些资料和书《写给程序员的数据挖掘指南》,此书不错,推荐大家看看,讲解得很透彻,有理论有代码,还有相关网站。看完后,你立刻就能把推荐算法应用在你的项目中~
本文先主要说明如何计算物品或用户之间的“距离”,陆续会介绍推荐算法本身~
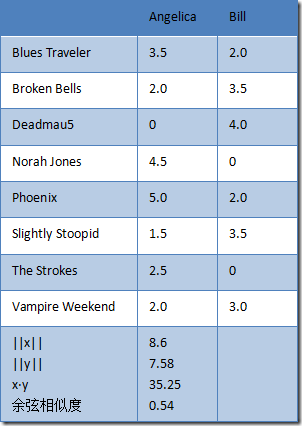
用户评分表
大体上,推荐算法可以有两种简单的思路:一是相似的用户,二是相似的物品。
前者,把与你相似的用户喜欢(或购买或评价高)的商品推荐给你,也就是说,如果你跟某个用户的喜好比较接近,那么就可以把这个用户喜欢的,而你不知道(或没浏览过,或没购买过等等)的物品推荐给你。什么叫“喜好接近”,就是对某些物品的评价也好,购买也罢,都比较接近,就认为,你和他喜好相同~
前者的缺陷在于,用户的评价毕竟是少数,想想,你评价过(显式评价)的物品有多少!大多数还是隐式评价,所谓隐式评价,如果你购买一个物品,那显然你会喜欢他,不然也不会买~因此,利用相似的用户是有局限性的。不如利用相似的物品来推荐。
下面“距离”算法主要针对计算用户之间的距离(相似性)。
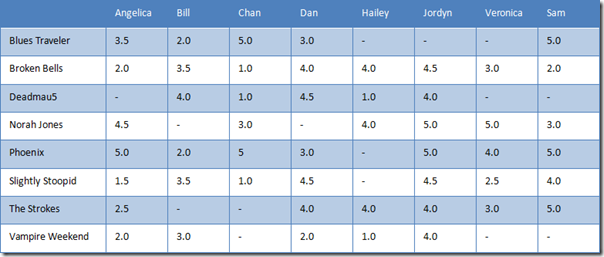
假设,8个用户对8个乐队进行评分,如下表所示。横向是用户,纵向是乐队。
表 1 用户评分表
曼哈顿(Manhattan)距离
计算距离最简单的方法是曼哈顿距离。假设,先考虑二维情况,只有两个乐队 x 和 y,用户A的评价为(x1,y1),用户B的评价为(x2,y2),那么,它们之间的曼哈顿距离为
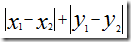
因此,Angelica 与 Bill 之间的曼哈顿距离如下表所示。
表 2 Angelica 与 Bill 的曼哈顿距离

那么,Angelica 与 Bill 之间的曼哈顿距离为 9,即第二列减第三列的绝对值,最后累加。
注意,必须是这两个用户都评分的乐队。
可以推广到n个乐队,即n维向量,用户 A(x1,x2,…,xn),用户B(y1,y2,…,yn) ,那么它们之间的曼哈顿距离为
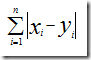
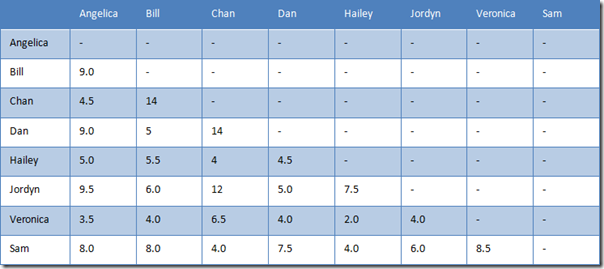
则用户之间的曼哈顿距离如下表所示。
表 3 用户之间的曼哈顿距离
曼哈顿距离的最大好处就是简单,只是加减法而已。如果有几百万个用户,计算起来会很快。
不仅可以扩展到 n 个乐队,当然也可以扩展到 m 个用户,它们可以形成一个矩阵。下面的其他距离同理。
Netflix 当初出 100 万美元奖励给能提升推荐算法 10% 准确率的团队或人,而赢得奖金的人就是使用了一种叫奇异矩阵分解的方法~
欧式(Euclidean)距离
除了曼哈顿距离外,还可以计算两个用户之间的欧式距离。
还是先考虑两个乐队 x 和 y 的情况,假设,用户A=(x1,y1),用户B=(x2,y2),那么它们之间的欧式距离:
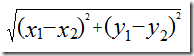
Angelica 与 Bill 之间的曼哈顿距离如下表所示。
表 4 Angelica 与 Bill 的欧式距离
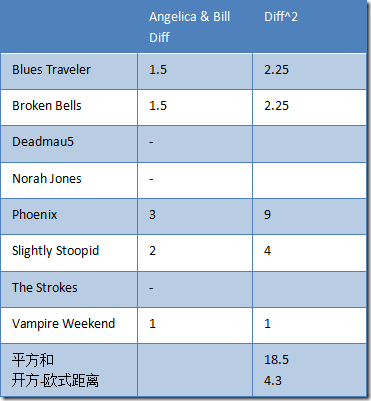
推广到 n 个乐队,用户 A(x1,x2,…,xn),用户B(y1,y2,…,yn)
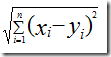
表 5 用户之间的欧式距离
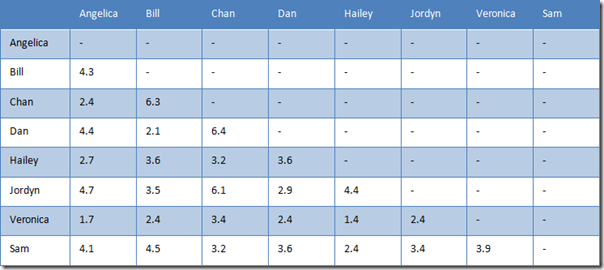
但曼哈顿距离和欧式距离,有个缺点。对比一下 Hailey 与 Veronica 和 Jordyn,Hailey 与前者只有两个乐队评过分,而与后者是五个。换句话说,Hailey 与 Veronica 的距离是基于二维的,而 Hailey 与 Jordyn 是基于五维。想想都觉得有问题。
所以,曼哈顿距离和欧式距离适合数据比较稠密、缺失值比较少的情况。如果缺失值很多,余弦相似度就比较合适。
曼哈顿距离和欧式距离,有通用公式,称为闵可夫斯基距离(Minkowski Distance)。
余弦相似度(cos simliarity)
假设,有两个乐队,用户A=(x1,y1),用户B=(x2,y2),那么他们之间的余弦相识度为:
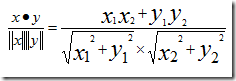
表 6 Angelica 与 Bill 的余弦相似度
推广到n维,用户A和B,对n个乐队的评分分别为(x1,x2,...,xn)和(y1,y2,...,yn),则他们之间的余弦相似度为
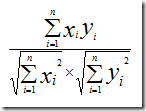
源代码 dis.py
#
# dis.py
#
from math import *
teams = [
"Blues Traveler",
"Broken Bells",
"Deadmau5",
"Norah Jones",
"Phoenix",
"Slightly Stoopid",
"The Strokes",
"Vampire Weekend"
]
users = {
"Angelica": {
"Blues Traveler": 3.5,
"Broken Bells": 2,
"Norah Jones": 4.5,
"Phoenix": 5,
"Slightly Stoopid": 1.5,
"The Strokes": 2.5,
"Vampire Weekend": 2
},
"Bill": {
"Blues Traveler": 2,
"Broken Bells": 3.5,
"Deadmau5": 4,
"Phoenix": 2,
"Slightly Stoopid": 3.5,
"Vampire Weekend": 3
},
"Chan": {
"Blues Traveler": 5,
"Broken Bells": 1,
"Deadmau5": 1,
"Norah Jones": 3,
"Phoenix": 5,
"Slightly Stoopid": 1
},
"Dan": {
"Blues Traveler": 3,
"Broken Bells": 4,
"Deadmau5": 4.5,
"Phoenix": 3,
"Slightly Stoopid": 4.5,
"The Strokes": 4,
"Vampire Weekend": 2
},
"Hailey": {
"Broken Bells": 4,
"Deadmau5": 1,
"Norah Jones": 4,
"The Strokes": 4,
"Vampire Weekend": 1
},
"Jordyn": {
"Broken Bells": 4.5,
"Deadmau5": 4,
"Norah Jones": 5,
"Phoenix": 5,
"Slightly Stoopid": 4.5,
"The Strokes": 4,
"Vampire Weekend": 4
},
"Sam": {
"Blues Traveler": 5,
"Broken Bells": 2,
"Norah Jones": 3,
"Phoenix": 5,
"Slightly Stoopid": 4,
"The Strokes": 5
},
"Veronica": {
"Blues Traveler": 3,
"Norah Jones": 5,
"Phoenix": 4,
"Slightly Stoopid": 2.5,
"The Strokes": 3
}
}
def manhattan(rating1, rating2):
"""Computes the Manhattan distance. Both rating1 and rating2 are dictionaries
of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += abs(rating1[key] - rating2[key])
commonRatings = True
if commonRatings:
return distance
else:
return -1 #Indicates no ratings in common
def euclidean(rating1, rating2):
"""Computes the euclidean distance. Both rating1 and rating2 are dictionaries
of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += pow(rating1[key] - rating2[key],2)
commonRatings = True
if commonRatings:
return sqrt(distance)
else:
return -1 #Indicates no ratings in common
def minkowski(rating1, rating2, r):
"""Computes the minkowski distance. Both rating1 and rating2 are dictionaries
of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
distance = 0
commonRatings = False
for key in rating1:
if key in rating2:
distance += pow(abs(rating1[key] - rating2[key]),r)
commonRatings = True
if commonRatings:
return pow(distance, 1.0/r)
else:
return -1 #Indicates no ratings in common
def cosineSimilarity (rating1, rating2):
"""Computes the Cosine Similarity distance. Both rating1 and rating2 are dictionaries
of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
sum_xy = 0
sum_sqr_x = 0
sum_sqr_y = 0
for key in teams:
if key in rating1 and key in rating2:
sum_xy += rating1[key]* rating2[key]
sum_sqr_x += pow(rating1[key], 2)
sum_sqr_y += pow(rating2[key], 2)
elif key not in rating1 and key in rating2:
sum_xy += 0
sum_sqr_x += 0
sum_sqr_y += pow(rating2[key], 2)
elif key in rating1 and key not in rating2:
sum_xy += 0
sum_sqr_x += pow(rating1[key], 2)
sum_sqr_y += 0
else:
sum_xy += 0
sum_sqr_x += 0
sum_sqr_y += 0
if sum_sqr_x ==0 or sum_sqr_y==0:
return -1 #Indicates no ratings in common
else:
return sum_xy / (sqrt(sum_sqr_x) * sqrt(sum_sqr_y))
def pearson(rating1, rating2):
"""Computes the pearson distance. Both rating1 and rating2 are dictionaries
of the form {'The Strokes': 3.0, 'Slightly Stoopid': 2.5}"""
sum_xy = 0
sum_x = 0
sum_y = 0
sum_x2 = 0
sum_y2 = 0
n = 0
for key in rating1:
if key in rating2:
n += 1
x = rating1[key]
y = rating2[key]
sum_xy += x * y
sum_x += x
sum_y += y
sum_x2 += pow(x, 2)
sum_y2 += pow(y, 2)
# now compute denominator
denominator = sqrt(sum_x2 - pow(sum_x, 2) / n) * sqrt(sum_y2 - pow(sum_y, 2) / n)
if denominator == 0:
return 0
else:
return (sum_xy - (sum_x * sum_y) / n) / denominator
推荐算法——距离算法的更多相关文章
- Atitti knn实现的具体四个距离算法 欧氏距离、余弦距离、汉明距离、曼哈顿距离
Atitti knn实现的具体四个距离算法 欧氏距离.余弦距离.汉明距离.曼哈顿距离 1. Knn算法实质就是相似度的关系1 1.1. 文本相似度计算在信息检索.数据挖掘.机器翻译.文档复制检测等领 ...
- java 根据经纬度坐标计算两点的距离算法
/** * @Desc 根据经纬度坐标计算两点的距离算法<br> * @Author yangzhenlong <br> * @Data 2018/5/9 18:38 */ p ...
- Levenshtein字符串距离算法介绍
Levenshtein字符串距离算法介绍 文/开发部 Dimmacro KMP完全匹配算法和 Levenshtein相似度匹配算法是模糊查找匹配字符串中最经典的算法,配合近期技术栏目关于算法的探讨,上 ...
- Python实现的计算马氏距离算法示例
Python实现的计算马氏距离算法示例 本文实例讲述了Python实现的计算马氏距离算法.分享给大家供大家参考,具体如下: 我给写成函数调用了 python实现马氏距离源代码: # encod ...
- 网络流入门--最大流算法Dicnic 算法
感谢WHD的大力支持 最早知道网络流的内容便是最大流问题,最大流问题很好理解: 解释一定要通俗! 如右图所示,有一个管道系统,节点{1,2,3,4},有向管道{A,B,C,D,E},即有向图一张. ...
- 数据聚类算法-K-means算法
深入浅出K-Means算法 摘要: 在数据挖掘中,K-Means算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法. K-Mea ...
- 最短路径算法-Dijkstra算法的应用之单词转换(词梯问题)(转)
一,问题描述 在英文单词表中,有一些单词非常相似,它们可以通过只变换一个字符而得到另一个单词.比如:hive-->five:wine-->line:line-->nine:nine- ...
- 变易算法 - STL算法
欢迎访问我的新博客:http://www.milkcu.com/blog/ 原文地址:http://www.milkcu.com/blog/archives/mutating-algorithms.h ...
- (转)最短路算法--Dijkstra算法
转自:http://blog.51cto.com/ahalei/1387799 上周我们介绍了神奇的只有五行的Floyd最短路算法,它可以方便的求得任意两点的最短路径,这称为“多源最短 ...
随机推荐
- JSP 中文乱码显示处理解决方案
来源: <http://blog.csdn.net/joyous/article/details/1504274> JSP 中文乱码显示处理解决方案 分类: 所有 Web前端 J2EE20 ...
- JS-定时器换背景
<!DOCTYPE HTML><html><head><meta http-equiv="Content-Type" content=&q ...
- error C2275: “XXX”: 将此类型用作表达式非法
在移植c++代码到c的时候,经常会出现一个奇怪的错误,error C2275: “XXX”: 将此类型用作表达式非法 表达式非法,这个错误是由于c的编译器要求将变量的申明放在一个函数块的头部,而c++ ...
- step by step 之餐饮管理系统五(Util模块)------附上篇日志模块源码
这段时间一直在修改日志模块,现在基本上写好了,也把注释什么的都加上了,昨天邮件发送给mark的园友一直报失败,老是退回来,真是报歉,如下图所示:
- PHP如何连接Access数据库
PHP代码: <?php $connstr="DRIVER={Microsoft Access Driver (*.mdb)}; DBQ=" .realpath(" ...
- 看起来像一个输入框的input,实际上是有两个input
看起来像一个输入框的input,实际上是有两个input
- OpenGL(一)——入门学习
概要 1. 为什么使用OpenGL 2. 在VS2008上搭建环境 3. 一个简单的例程 OpenGL相较于DirectX的优越性 1. 与C语言紧密结合 OpenGL命令最初就是用C语言函数来进行描 ...
- java 继承多态的一些理解不和不理解
1.向上转型的一个误区 一直以为Child 继承Parent以后, Parent p = new Child(); p可以调用Child类中拓展Parent的方法,原来必须在强制转换成Child类才 ...
- 个性二维码开源专题<基础篇>
二维码原理介绍: 二维码为什么是黑白相间的?黑色表示二进制的“1”,白色表示二进制的“0” “我们之所以对二维码进行扫描能读出那么多信息,就是因为这些信息被编入了二维码之中.”黄海平说,“制作二维码输 ...
- Mac OS X上尝试编译CoreCLR源代码
CoreCLR登陆GitHub之后,体验CoreCLR首当其冲的方式就是在自己的电脑上编译它,昨天分别在Windows与Linux上成功编译了CoreCLR,详见: 1)Windows上成功编译Cor ...