原创:CentOS6.4配置solr 4.7.2+IK分词器
本文原创,转载请注明出处
相关资源下载:http://pan.baidu.com/s/1pJPpiqv
1.首先说明一下 solr是java语言开发的企业级应用服务器,所以你首先安装好jdk,配置好java的运行环境,然后solr提供一套wapapp,类似于一个后台
对外提供服务,所以你也 应该安装好 网站的一个运行环境tomcat,在此掠过。本环境安装的路径如下:
jdk :/usr/local/jdk tomcat :/usr/local/tomcat
环境说明:centos-6.4+jdk6.0+tomcat-6+solr-4.7.2[如果安装4.9版本的,则提示不兼容,它是用java高版本编译的,低版本下运行不起来]
网上说的拷贝这包,那包的都不靠谱,为甚么要拷贝,也没有说清楚。下载完 solr-4.7.2后解压
2. solr其实分两部分,一部分是网站也就是那个 dist/solr-4.7.2.war[有人说是example/webapps/solr.war 这个经测试不对,也许是版本原因吧]
另一部分就是solr自己的程序包,在example/solr (这里你要注意了,如果单单是吧这个文件夹拷走是不对了,应为它要引用 contrib和dist文件夹里的jar包)
在此引用的:solr-4.7.2\solr-4.7.2\example\solr\collection1\conf\solrconfig.xml 里
<lib dir="../../../contrib/extraction/lib" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-cell-\d.*\.jar" /> <lib dir="../../../contrib/clustering/lib/" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-clustering-\d.*\.jar" /> <lib dir="../../../contrib/langid/lib/" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-langid-\d.*\.jar" /> <lib dir="../../../contrib/velocity/lib" regex=".*\.jar" />
<lib dir="../../../dist/" regex="solr-velocity-\d.*\.jar" />
实战部分:①:将solr-4.7.2\solr-4.7.2\dist\solr-4.7.2.war 拷贝到tomcat的webapps 下,一定要改成solr.war 我的是/usr/local/tomcat/webapps/solr.war,重启tomcat后,tomcat会制动给你
解压成solr.后续看下边。
② 将solr-4.7.2\solr-4.7.2\contrib 和solr-4.7.2\solr-4.7.2\dist 目录拷贝到solr-4.7.2\solr-4.7.2\example\solr 下,然后修改以上的配置文件 ../../../ 变成../../../
PS:你怎么拷贝都成,只要这个配置文件的相对路径能找到那两个文件夹下的jar包,修改完之后,将example\solr 打包成 solr.zip 【rar在linux上无法解包】
然后把这个solr.zip 上传到/usr/local/tomcat/下 unzip solr.zip 一下
③ 修改/usr/local/tomcat/webapps/solr/WEB-INF/web.xml 文件 找到以下节点 将其替换
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/tomcat/solr</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
solr/home 就是咱 刚才上传的那个zip包,重启tomcat,输入 http://localhost:8080/solr OK,搞定。 3.配置安装中文分词IKanalyzer
1) 解压IK Analyzer 2012FF_hf1.zip,获得IK Analyzer 2012FF_hf1.将该目录下的
IKAnalyzer.cfg.xml,
IKAnalyzer2012FF_u1.jar,
stopword.dic
放到之前安装TOMCAT_HOME/webapps/solr/WEB-INF/lib/目录下,比如我这里是/usr/local/tomcat/webapps/solr/WEB-INF/lib/
2) 修改 /usr/local/tomcat/solr/collection1/conf/schema.xml 在<type></types>中增加如下内容
<fieldType name="text_ik" class="solr.TextField">
<analyzer type="index" isMaxWordLength="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
<analyzer type="query" isMaxWordLength="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/>
</fieldType>
然后随便找一个field 例如 <field name="author" type="text_ik" indexed="true" stored="true"/> 将type值变成text_ik 原来是[text_general]
ok,可以测试了
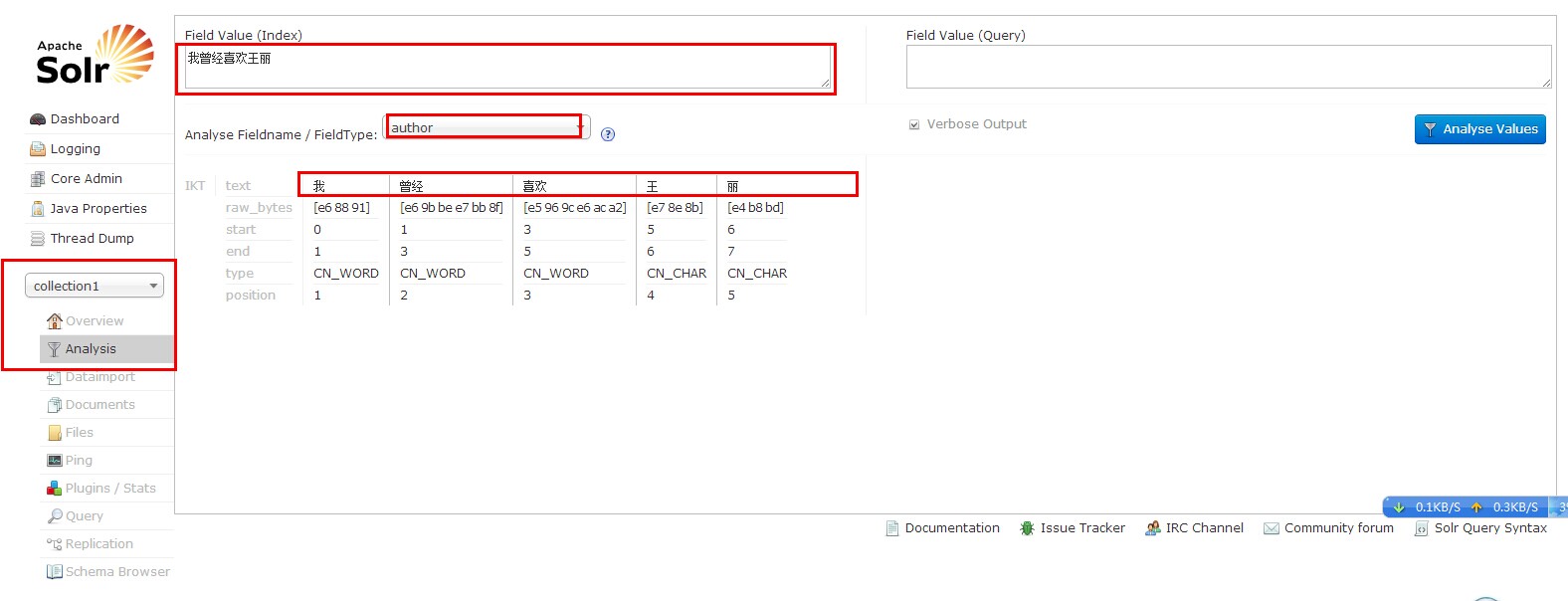
分出来了吧,弄不出来,可以contact me QQ:769871707
#有可能遇到的问题:
从solr-4.7.2\example\lib\ext复制所有的jar到tomcat/lib下,并复制solr-7.2\example\resources\log4j.properties到tomcat/lib下(有关日志的说明,见http://wiki.apache.org/solr/SolrLogging),须知,solr-4.7.2.jar并没有自带日志打印组件,因此这个步骤不执行,可能引起“org.apache.catalina.core.StandardContext filterStart SEVERE: Exception starting filter SolrRequestFilter org.apache.solr.common.SolrException: Could not find necessary SLF4j logging jars.”异常;
原创:CentOS6.4配置solr 4.7.2+IK分词器的更多相关文章
- Solr4.4入门,介绍Solr的安装、IK分词器的配置及高亮查询结果(转)
一.Windows下安装solr-4.4.0 1. 下载solr.4.4 2. 下载绿色版tomcat6.0.18 3. 解压下载的solr到d:\study\solr,将dist目录下的sol ...
- 13.solr学习速成之IK分词器
IKAnalyzer简介 IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包. IKAnalyzer特性 a. 算法采用“正向迭代最细粒度切分算法”,支持细粒度和最大词长两 ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一.
在这里一下讲解着三个的安装和配置, 是因为solr需要使用tomcat和IK分词器, 这里会通过图文教程的形式来详解它们的安装和使用.注: 本文属于原创文章, 如若转载,请注明出处, 谢谢.关于设置I ...
- [Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例二.
为了更好的排版, 所以将IK分词器的安装重启了一篇博文, 大家可以接上solr的安装一同查看.[Linux]Linux下安装和配置solr/tomcat/IK分词器 详细实例一: http://ww ...
- solr英文使用的基本分词器和过滤器配置
solr英文应用的基本分词器和过滤器配置 英文应用分词器和过滤器一般配置顺序 索引(index): 1:空格 WhitespaceTokenizer 2:过滤词(停用词,如:on.of.a.an ...
- Solr(四)Solr实现简单的类似百度搜索高亮功能-1.配置Ik分词器
配置Ik分词器 一 效果图 二 实现此功能需要添加分词器,在这里使用比较主流的IK分词器. 1 没有配置IK分词器,用solr自带的text分词它会把一句话分成单个的字. 2 配置IK分词器,的话它会 ...
- Solr 06 - Solr中配置使用IK分词器 (配置schema.xml)
目录 1 配置中文分词器 1.1 准备IK中文分词器 1.2 配置schema.xml文件 1.3 重启Tomcat并测试 2 配置业务域 2.1 准备商品数据 2.2 配置商品业务域 2.3 配置s ...
- solr配置相关:约束文件及引入ik分词器
schema.xml: solr约束文件 Solr中会提前对文档中的字段进行定义,并且在schema.xml中对这些字段的属性进行约束,例如:字段数据类型.字段是否索引.是否存储.是否分词等等 < ...
- solr配置同义词,停止词,和扩展词库(IK分词器为例)
定义 同义词:搜索结果里出现的同义词.如我们输入”还行”,得到的结果包括同义词”还可以”. 停止词:在搜索时不用出现在结果里的词.比如is .a .are .”的”,“得”,“我” 等,这些词会在句子 ...
随机推荐
- android.intent.action.MAIN 与 android.intent.category.LAUNCHER 的验证理解 (转)
原文地址:android.intent.action.MAIN 与 android.intent.category.LAUNCHER 的验证理解 作者: 第一种情况:有MAIN,无LAUNCHER,程 ...
- IIS-如果外网访问不到 域名
如果访问不到 域名 , 可以 给域名的目录 增加“IIS_IUSERS”权限.
- JSON浅总
我们在以前的学习中了解到XML是一种结构化的数据表示方式,一种可扩展标记语言!可以把XML理解成一个微型的结构化的小的数据库,保存一些小型的数据和传输数据,有严格的显示限制.但是XML语句有些冗长和繁 ...
- HBase伪分布式环境下,HBase的API操作,遇到的问题
在hadoop2.5.2伪分布式上,安装了hbase1.0.1.1的伪分布式 利用HBase的API创建个testapi的表时,提示 Exception in thread "main&q ...
- eclipse下导入工程的小问题
- C# 通用上传文件类
1.Upfile.aspx: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="U ...
- PO3281 Dining(最大流)
如果只有食物或者饮料那就是个二分图最大匹配. 三个真想不出来..然后看题解..从源点到食物到牛到饮料到汇点,这样建图. 所以思维不能太局限了,不懂得把食物和饮料放到牛两边,以为牛吃食物饮料.食物饮料被 ...
- WPF之TextBox
1. TextBox实现文字垂直居中 TextBox纵向长度比较长但文字字体比较小的时候,在输入时就会发现文字不是垂直居中的. 而使用中我们发现,TextBox虽然可以设置文字的水平对齐方式,但却没有 ...
- codeforces round #201 Div2 A. Difference Row
#include <iostream> #include <vector> #include <algorithm> using namespace std; in ...
- MongoBD解决没有自动增长ID 的问题
Sequence Numbers:序列号传统的数据库中,通常用一个递增的序列来提供主键,在 MongoDB中用 ObjectId 的来代替,我们可以通过如下的函数来获取主键 function coun ...