深度解析NLP文本摘要技术:定义、应用与PyTorch实战
在本文中,我们深入探讨了自然语言处理中的文本摘要技术,从其定义、发展历程,到其主要任务和各种类型的技术方法。文章详细解析了抽取式、生成式摘要,并为每种方法提供了PyTorch实现代码。最后,文章总结了摘要技术的意义和未来的挑战,强调了其在信息过载时代的重要性。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。

1. 概述
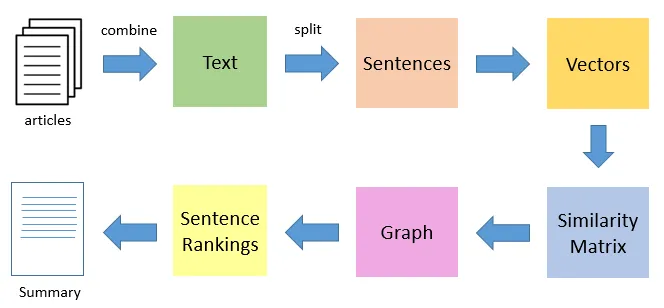
文本摘要是自然语言处理(NLP)的一个重要分支,其核心目的是提取文本中的关键信息,生成简短、凝练的内容摘要。这不仅有助于用户快速获取信息,还能有效地组织和归纳大量的文本数据。
1.1 什么是文本摘要?
文本摘要的目标是从一个或多个文本源中提取主要思想,创建一个短小、连贯且与原文保持一致性的描述性文本。
例子: 假设有一篇新闻文章,描述了一个国家领导人的访问活动,包括他的行程、会面的外国领导人和他们讨论的议题。文本摘要的任务可能是生成一段如下的摘要:“国家领导人A于日期B访问了国家C,并与领导人D讨论了E议题。”
1.2 为什么需要文本摘要?
随着信息量的爆炸性增长,人们需要处理的文本数据量也在快速增加。文本摘要为用户提供了一个高效的方法,可以快速获取文章、报告或文档的核心内容,无需阅读整个文档。
例子: 在学术研究中,研究者们可能需要查阅数十篇或数百篇的文献来撰写文献综述。如果每篇文献都有一个高质量的文本摘要,研究者们可以迅速了解每篇文献的主要内容和贡献,从而更加高效地完成文献综述的撰写。
文本摘要的应用场景非常广泛,包括但不限于新闻摘要、学术文献摘要、商业报告摘要和医学病历摘要等。通过自动化的文本摘要技术,不仅可以提高信息获取的效率,还可以在多种应用中带来巨大的商业价值和社会效益。
2. 发展历程
文本摘要的历史可以追溯到计算机科学和人工智能的早期阶段。从最初的基于规则的方法,到现今的深度学习技术,文本摘要领域的研究和应用都取得了长足的进步。
2.1 早期技术
在计算机科学早期,文本摘要主要依赖基于规则和启发式的方法。这些方法主要根据特定的关键词、短语或文本的句法结构来提取关键信息。
例子: 假设在一个新闻报道中,频繁出现的词如“总统”、“访问”和“协议”可能会被认为是文本的关键内容。因此,基于这些关键词,系统可能会从文本中选择包含这些词的句子作为摘要的内容。
2.2 统计方法的崛起
随着统计学方法在自然语言处理中的应用,文本摘要也开始利用TF-IDF、主题模型等技术来自动生成摘要。这些方法在某种程度上改善了摘要的质量,使其更加接近人类的思考方式。
例子: 通过TF-IDF权重,可以识别出文本中的重要词汇,然后根据这些词汇的权重选择句子。例如,在一篇关于环境保护的文章中,“气候变化”和“可再生能源”可能具有较高的TF-IDF权重,因此包含这些词汇的句子可能会被选为摘要的一部分。
2.3 深度学习的应用
近年来,随着深度学习技术的发展,尤其是循环神经网络(RNN)和变压器(Transformers)的引入,文本摘要领域得到了革命性的提升。这些技术能够捕捉文本中的深层次语义关系,生成更为流畅和准确的摘要。
例子: 使用BERT或GPT等变压器模型进行文本摘要,模型不仅仅是根据关键词进行选择,而是可以理解文本的整体含义,并生成与原文内容一致但更为简洁的摘要。
2.4 文本摘要的演变趋势
文本摘要的方法和技术持续在进化。目前,研究的焦点包括多模态摘要、交互式摘要以及对抗生成网络在摘要生成中的应用等。
例子: 在一个多模态摘要任务中,系统可能需要根据给定的文本和图片生成一个摘要。例如,对于一个报道某项体育赛事的文章,系统不仅需要提取文本中的关键信息,还需要从与文章相关的图片中提取重要内容,将二者结合生成摘要。
3. 主要任务
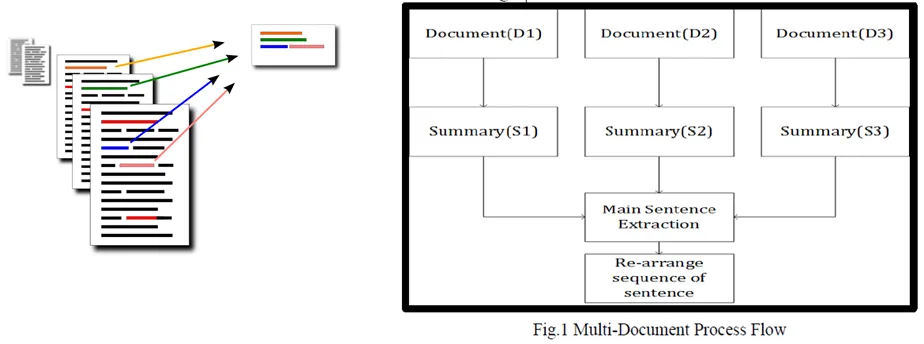
文本摘要作为自然语言处理的一部分,其主要任务涉及多个方面,旨在满足不同的应用需求。以下是文本摘要中的几个关键任务,以及相关的定义和示例。
3.1 单文档摘要
这是文本摘要的最基本形式,从一个给定的文档中提取关键信息,生成一个简洁的摘要。
定义: 对一个单独的文档进行处理,提取其核心信息,生成一个凝练的摘要。
例子: 从一篇关于某地震事件的新闻报道中提取关键信息,生成摘要:“日期X,在Y地区发生了Z级地震,导致A人受伤,B人死亡。”
3.2 多文档摘要
该任务涉及从多个相关文档中提取和整合关键信息,生成一个综合摘要。
定义: 对一组相关的文档进行处理,合并它们的核心信息,生成一个综合的摘要。
例子: 从五篇关于同一项技术大会的报道中提取关键信息,生成摘要:“在日期X的技术大会上,公司Y、Z和W分别发布了他们的最新产品,并讨论了未来技术的发展趋势。”
3.3 信息性摘要 vs. 背景摘要
信息性摘要重点关注文档中的主要新闻或事件,而背景摘要则关注为读者提供背景或上下文信息。
定义: 信息性摘要提供文档的核心内容,而背景摘要提供与该内容相关的背景或上下文信息。
例子:
- 信息性摘要:“国家A和国家B签署了贸易协议。”
- 背景摘要:“国家A和国家B自去年开始进行贸易谈判,旨在增加两国间的商品和服务交易。”
3.4 实时摘要
这是一种生成动态摘要的任务,特别是当信息源持续更新时。
定义: 根据不断流入的新信息,实时地更新并生成摘要。
例子: 在一项体育赛事中,随着比赛的进行,系统可以实时生成摘要,如:“第一节结束,队伍A领先队伍B 10分。队伍A的球员C已经得到15分。”
4. 主要类型
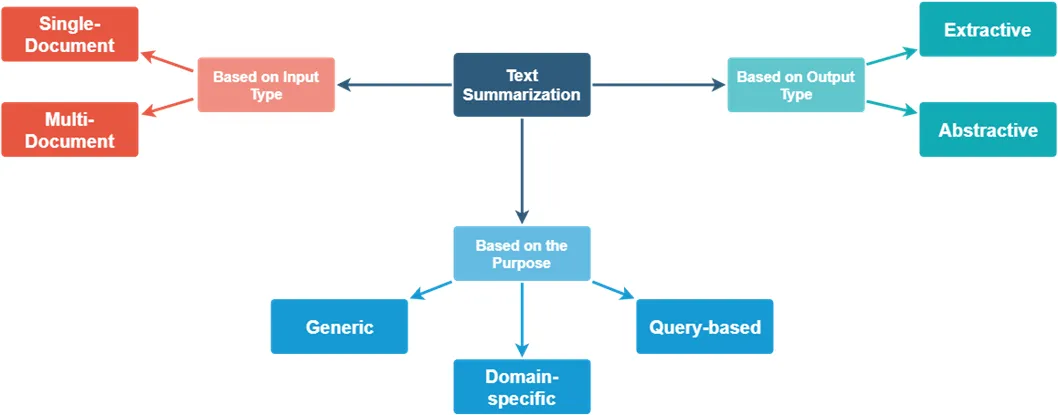
文本摘要可以根据其生成方式和特点划分为多种类型。以下是文本摘要领域中的主要类型及其定义和示例。
4.1 抽取式摘要
这种类型的摘要直接从原文中提取句子或短语来构成摘要,而不生成新的句子。
定义: 直接从原始文档中选择性地提取句子或短语,以生成摘要。
例子:
原文: “北京是中国的首都。它有着悠久的历史和丰富的文化遗产。故宫、长城和天安门都是著名的旅游景点。”
抽取式摘要: “北京是中国的首都。故宫、长城和天安门都是著名的旅游景点。”
4.2 生成式摘要
与抽取式摘要不同,生成式摘要会产生新的句子,为读者提供更为简洁和流畅的文本摘要。
定义: 基于原始文档的内容,生成新的句子来构成摘要。
例子:
原文: “北京是中国的首都。它有着悠久的历史和丰富的文化遗产。故宫、长城和天安门都是著名的旅游景点。”
生成式摘要: “北京,中国的首都,以其历史遗迹如故宫、长城和天安门而闻名。”
4.3 指示性摘要
这种类型的摘要旨在提供文档的大致内容,通常较为简短。
定义: 对文档进行快速概括,给出主要内容的简短描述。
例子:
原文: “微软公司是一家总部位于美国的跨国技术公司。它是世界上最大的软件制造商,并且生产多种消费电子产品。”
指示性摘要: “微软是一家大型的美国技术公司,生产软件和消费电子。”
4.4 信息性摘要
这种摘要提供更详细的信息,通常较长,涵盖文档的多个方面。
定义: 提供文档的详细内容概括,涵盖文档的核心信息。
例子:
原文: “微软公司是一家总部位于美国的跨国技术公司。它是世界上最大的软件制造商,并且生产多种消费电子产品。”
信息性摘要: “位于美国的微软公司是全球最大的软件生产商,同时还制造了多种消费电子产品。”
5. 抽取式文本摘要
抽取式文本摘要方法通过从原始文档中直接提取句子或短语来形成摘要,而不重新构造新的句子。
5.1 定义
定义: 抽取式文本摘要是从原始文档中选择性地提取句子或短语以生成摘要的过程。该方法通常依赖于文档中句子的重要性评分。
例子:
原文: “北京是中国的首都。它有着悠久的历史和丰富的文化遗产。故宫、长城和天安门都是著名的旅游景点。”
抽取式摘要: “北京是中国的首都。故宫、长城和天安门都是著名的旅游景点。”
5.2 抽取式摘要的主要技术
- 基于统计:使用词频、逆文档频率等统计方法为文档中的句子分配重要性分数。
- 基于图:如TextRank算法,将句子视为图中的节点,基于它们之间的相似性建立边,并通过迭代过程为每个句子分配得分。
5.3 Python实现
下面是一个简单的基于统计的抽取式摘要的Python实现:
import re
from collections import defaultdict
from nltk.tokenize import word_tokenize, sent_tokenize
def extractive_summary(text, num_sentences=2):
# 1. Tokenize the text
words = word_tokenize(text.lower())
sentences = sent_tokenize(text)
# 2. Compute word frequencies
frequency = defaultdict(int)
for word in words:
if word.isalpha(): # ignore non-alphabetic tokens
frequency[word] += 1
# 3. Rank sentences
ranked_sentences = sorted(sentences, key=lambda x: sum([frequency[word] for word in word_tokenize(x.lower())]), reverse=True)
# 4. Get the top sentences
return ' '.join(ranked_sentences[:num_sentences])
# Test
text = "北京是中国的首都。它有着悠久的历史和丰富的文化遗产。故宫、长城和天安门都是著名的旅游景点。"
print(extractive_summary(text))
输入:原始文本
输出:抽取的摘要
处理过程:该代码首先计算文档中每个词的频率,然后根据其包含的词频为每个句子分配重要性得分,并返回得分最高的句子作为摘要。
6. 生成式文本摘要
与直接从文档中提取句子的抽取式摘要方法不同,生成式文本摘要旨在为原始文档内容生成新的、更简洁的表达。
6.1 定义
定义: 生成式文本摘要涉及利用原始文档内容创造新的句子和短语,为读者提供更为简洁且相关的信息。
例子:
原文: “北京是中国的首都。它有着悠久的历史和丰富的文化遗产。故宫、长城和天安门都是著名的旅游景点。”
生成式摘要: “北京,中国的首都,以其历史遗迹如故宫、长城和天安门而闻名。”
6.2 主要技术
- 序列到序列模型 (Seq2Seq):这是一种深度学习方法,通常用于机器翻译任务,但也被广泛应用于生成式摘要。
- 注意力机制:在Seq2Seq模型中加入注意力机制可以帮助模型更好地关注原始文档中的重要部分。
6.3 PyTorch实现
下面是一个简单的Seq2Seq模型的概述,由于其复杂性,这里只提供一个简化版本:
import torch
import torch.nn as nn
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hidden_dim):
super(Encoder, self).__init__()
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.GRU(emb_dim, hidden_dim)
def forward(self, src):
embedded = self.embedding(src)
outputs, hidden = self.rnn(embedded)
return hidden
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hidden_dim):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.GRU(emb_dim + hidden_dim, hidden_dim)
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, input, hidden, context):
input = input.unsqueeze(0)
embedded = self.embedding(input)
emb_con = torch.cat((embedded, context), dim=2)
output, hidden = self.rnn(emb_con, hidden)
prediction = self.out(output.squeeze(0))
return prediction, hidden
# 注: 这是一个简化的模型,仅用于展示目的。在实际应用中,您需要考虑添加更多细节,如注意力机制、优化器、损失函数等。
输入: 原始文档的词向量序列
输出: 生成的摘要的词向量序列
处理过程: 编码器首先将输入文档转换为一个固定大小的隐藏状态。然后,解码器使用这个隐藏状态作为上下文,逐步生成摘要的词向量序列。
7. 总结
随着科技的迅速发展,自然语言处理已从其原始的文本处理任务进化为复杂的多模态任务,如我们所见,文本摘要正是其中的一个明显例子。从基本的抽取式和生成式摘要到现今的多模态摘要,每一个阶段都反映了我们对信息和知识的不断深化和重新定义。
重要的是,我们不仅仅要关注技术如何实现这些摘要任务,更要明白为什么我们需要这些摘要技术。摘要是对大量信息的简化,它可以帮助人们快速捕获主要观点、节省时间并提高效率。在一个信息过载的时代,这种能力变得尤为重要。
但是,与此同时,我们也面临着一个挑战:如何确保生成的摘要不仅简洁,而且准确、客观,并且不失真。这需要我们不断完善和调整技术,确保其在各种场景下都能提供高质量的摘要。
关注TechLead,分享AI全维度知识。作者拥有10+年互联网服务架构、AI产品研发经验、团队管理经验,同济本复旦硕,复旦机器人智能实验室成员,阿里云认证的资深架构师,项目管理专业人士,上亿营收AI产品研发负责人。
如有帮助,请多关注
TeahLead KrisChang,10+年的互联网和人工智能从业经验,10年+技术和业务团队管理经验,同济软件工程本科,复旦工程管理硕士,阿里云认证云服务资深架构师,上亿营收AI产品业务负责人。
深度解析NLP文本摘要技术:定义、应用与PyTorch实战的更多相关文章
- 基于TextRank算法的文本摘要
本文介绍TextRank算法及其在多篇单领域文本数据中抽取句子组成摘要中的应用. TextRank 算法是一种用于文本的基于图的排序算法,通过把文本分割成若干组成单元(句子),构建节点连接图,用句子之 ...
- 华为全栈AI技术干货深度解析,解锁企业AI开发“秘籍”
摘要:针对企业AI开发应用中面临的痛点和难点,为大家带来从实践出发帮助企业构建成熟高效的AI开发流程解决方案. 在数字化转型浪潮席卷全球的今天,AI技术已经成为行业公认的升级重点,正在越来越多的领域为 ...
- 深度解析SDN——利益、战略、技术、实践(实战派专家力作,业内众多专家推荐)
深度解析SDN——利益.战略.技术.实践(实战派专家力作,业内众多专家推荐) 张卫峰 编 ISBN 978-7-121-21821-7 2013年11月出版 定价:59.00元 232页 16开 ...
- fastText、TextCNN、TextRNN……这里有一套NLP文本分类深度学习方法库供你选择
https://mp.weixin.qq.com/s/_xILvfEMx3URcB-5C8vfTw 这个库的目的是探索用深度学习进行NLP文本分类的方法. 它具有文本分类的各种基准模型,还支持多标签分 ...
- 斯坦福NLP课程 | 第15讲 - NLP文本生成任务
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
- 深度解析VC中的消息(转发)
http://blog.csdn.net/chenlycly/article/details/7586067 这篇转发的文章总结的比较好,但是没有告诉我为什么ON_MESSAGE的返回值必须是LRES ...
- NLP文本分类
引言 其实最近挺纠结的,有一点点焦虑,因为自己一直都期望往自然语言处理的方向发展,梦想成为一名NLP算法工程师,也正是我喜欢的事,而不是为了生存而工作.我觉得这也是我这辈子为数不多的剩下的可以自己去追 ...
- 万字总结Keras深度学习中文文本分类
摘要:文章将详细讲解Keras实现经典的深度学习文本分类算法,包括LSTM.BiLSTM.BiLSTM+Attention和CNN.TextCNN. 本文分享自华为云社区<Keras深度学习中文 ...
- mybatis 3.x源码深度解析与最佳实践(最完整原创)
mybatis 3.x源码深度解析与最佳实践 1 环境准备 1.1 mybatis介绍以及框架源码的学习目标 1.2 本系列源码解析的方式 1.3 环境搭建 1.4 从Hello World开始 2 ...
- 【AI in 美团】深度学习在文本领域的应用
背景 近几年以深度学习技术为核心的人工智能得到广泛的关注,无论是学术界还是工业界,它们都把深度学习作为研究应用的焦点.而深度学习技术突飞猛进的发展离不开海量数据的积累.计算能力的提升和算法模型的改进. ...
随机推荐
- iptables简要介绍及使用iptables实践NAT技术
简介 iptables的文章多如牛毛,但是,我读了一些,发现虽然成体系,但是不便理解,今天就结合自己的理解,好好讲解下,另外,我们也会使用iptables来实验一个nat地址转换的demo,nat转换 ...
- Qt+GDAL开发笔记(一):在windows系统mingw32编译GDAL库、搭建开发环境和基础Demo
前言 麒麟系统上做全球北斗定位终端开发,调试工具要做一个windows版本方便校对,北斗GPS发过来的是大地坐标,应用需要的是经纬度坐标,所以需要转换,可以使用公式转换,但是之前涉及到了另一个sh ...
- javascript中一些难以理解的专有名词 2(也不是很专有)
作用域链 让人迷惑的例子 function foo() {console.log(v)} function foo1() { var v = "v1" foo() console. ...
- mysql根据.frm和.ibd文件恢复数据表
忠人之事受人之托 起因是因为一位朋友的数据库服务器被重装了,只剩下一个zbp_post.frm和zbp_post.ibd文件.咨询我能不能恢复,确实我只用过mysqldump这种工具导出数据 然后进行 ...
- RocketMq消费原理及源码解析
消费原理概览 先简单说下常见的rocketMq的部署方式,上图中broker为真正计算和存储消息的地方,而nameServer负责维护broker地 图中右侧consume message部分即是本文 ...
- [jmeter]简介与安装
简介 JMeter是开源软件Apache基金会下的一个性能测试工具,用来测试部署在服务器端的应用程序的性能. 安装 安装jmeter 从 官网 下载jmeter的压缩包 安装jdk并配置 JAVA_H ...
- redis数据持久化之RDB和AOF
前言 redis虽然是内存缓存程序,但是可以将内存中的数据保存到硬盘上,从而实现数据保存.目前有两种redis数据持久化方式,分别是RDB和AOF. RDB模式 RDB之简介 RDB(redis da ...
- Git-更换服务器问题
一.Permission denied (publickey) git指令出现Permission denied (publickey),是ssh key过期的问题,需要对ssh key进行更新,所有 ...
- java与es8实战之三:Java API Client有关的知识点串讲
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 本篇概览 本篇是<java与es8实战>系 ...
- 代码随想录算法训练营第二十八天| 93.复原IP地址 78.子集 90.子集II
93.复原IP地址 卡哥建议:本期本来是很有难度的,不过 大家做完 分割回文串 之后,本题就容易很多了 题目链接/文章讲解:https://programmercarl.com/0093.%E5% ...