SQL Server 根据一个表数据修改另外一个表数据
今天在写代码的时候发现一个有趣的问题,同时也暴露了之前写的代码有问题,还好之前没有出现重复的情况,及时发现了这个问题,及时改了回来,不然就GG了
下面先上代码,再给大家解说一下


CREATE TABLE #t1 (id INT,value int)
CREATE TABLE #t2 (id INT,value int) INSERT #t1(id,value)
VALUES( 1, 1 ),
( 2, 2 ),
( 3, 3 ),
( 4, 4 ) INSERT #t2(id,value)
VALUES( 1, 1 ),
( 1, 2 ),
( 1, 3 ) SELECT * FROM #t1
SELECT * FROM #t2 --;
--WITH t1 AS(
--SELECT b.id,SUM(a.value) value FROM #t2 a INNER JOIN #t1 b ON b.id = a.id GROUP BY b.id) --UPDATE #t1 SET #t1.value= a.value+b.value FROM #t1 a INNER JOIN t1 b ON b.id = a.id UPDATE #t1 SET #t1.value= a.value+t.value FROM #t1 a INNER JOIN #t2 t ON t.id = a.id SELECT * FROM #t1 DROP TABLE #t1
DROP TABLE #t2
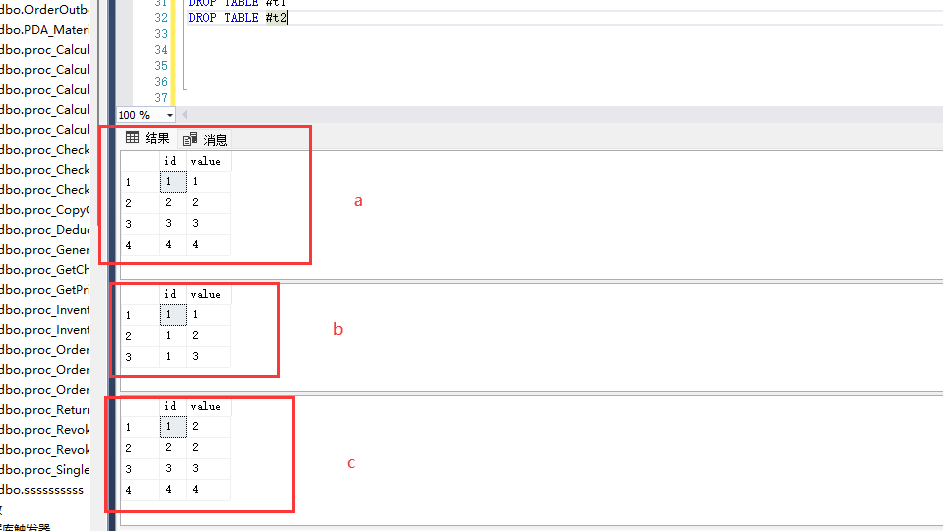
其实当你看代码就知道,我想根据b表修改a表,按我们的思维,a表id=1的有一条记录,b表id=1的有三条,
这样级联修改以后应该c结果中id=1的值应该是7才对,但是只有2,说明是a表里面的1加了b表里面的value=1 的第一条记录,我在SQL交流群里面问了一下
有人说a表只有一条记录,b表有三条记录,只匹配了第一条,然后我就试了一下,在a表中造了三条记录
CREATE TABLE #t1 (id INT,value int)
CREATE TABLE #t2 (id INT,value int) INSERT #t1(id,value)
VALUES( 1, 1 ),
( 1, 2 ),
( 1, 3 ),
( 4, 4 ) INSERT #t2(id,value)
VALUES( 1, 1 ),
( 1, 2 ),
( 1, 3 ) SELECT * FROM #t1
SELECT * FROM #t2 --;
--WITH t1 AS(
--SELECT b.id,SUM(a.value) value FROM #t2 a INNER JOIN #t1 b ON b.id = a.id GROUP BY b.id) --UPDATE #t1 SET #t1.value= a.value+b.value FROM #t1 a INNER JOIN t1 b ON b.id = a.id UPDATE #t1 SET #t1.value= a.value+t.value FROM #t1 a INNER JOIN #t2 t ON t.id = a.id SELECT * FROM #t1 DROP TABLE #t1
DROP TABLE #t2
然后出现一件很神奇的事
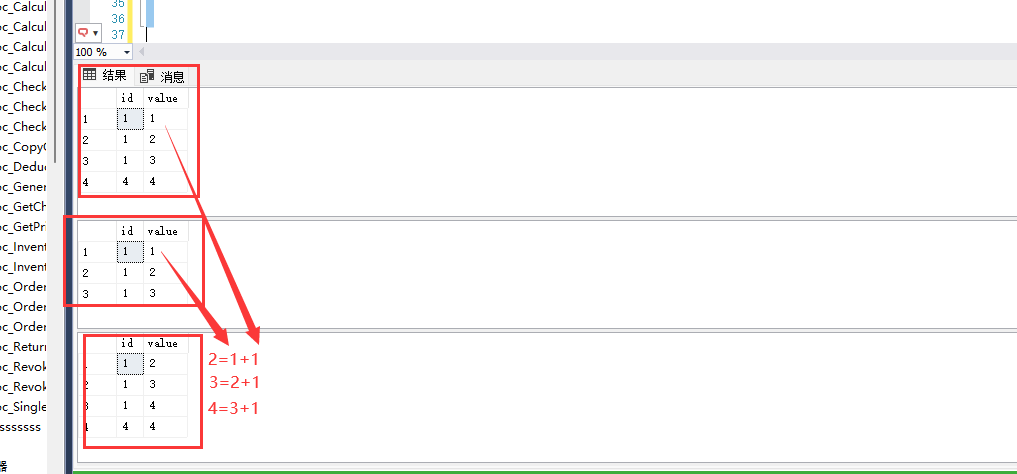
可以看见,即使a表有三条,匹配的b表依旧只有是第一条
所以及时看见这个坑,阿西吧,又是踩坑的一天,还好检查代码发现了问题
经过修正后的代码,有三种解决方案,第一子查询汇总修改,第二用 CTE(CTE表示公用表表达式,是一个临时命名结果集,始终返回结果集)语法解决,第三种使用循环,
具体使用看实际情况,因为我的级联修改是在循环外,所以就用前两种,我一般使用CTE 语法修改,这个语法用法还是很普遍很爽的,但是使用有限制,脱离主体只能使用一次,
如果你要用多次,建议使用临时表或者表变量(个人推荐表变量,具体使用还是要看情况,差异还是挺大的,有时间我为大家写一篇这三种的异同的随便)
不哔哔,直接上代码
CREATE TABLE #t1 (id INT,value int)
CREATE TABLE #t2 (id INT,value int) INSERT #t1(id,value)
VALUES( 1, 1 ),
( 2, 2 ),
( 3, 3 ),
( 4, 4 ) INSERT #t2(id,value)
VALUES( 1, 1 ),
( 1, 2 ),
( 1, 3 ) SELECT * FROM #t1
SELECT * FROM #t2 --;
--WITH t1 AS(
--SELECT b.id,SUM(a.value) value FROM #t2 a INNER JOIN #t1 b ON b.id = a.id GROUP BY b.id) --UPDATE #t1 SET #t1.value= a.value+b.value FROM #t1 a INNER JOIN t1 b ON b.id = a.id UPDATE #t1 SET #t1.value= a.value+t.value FROM #t1 a INNER JOIN (SELECT id,SUM(value) value FROM #t2 WHERE #t2.id=id GROUP BY id)t ON t.id = a.id SELECT * FROM #t1 DROP TABLE #t1
DROP TABLE #t2
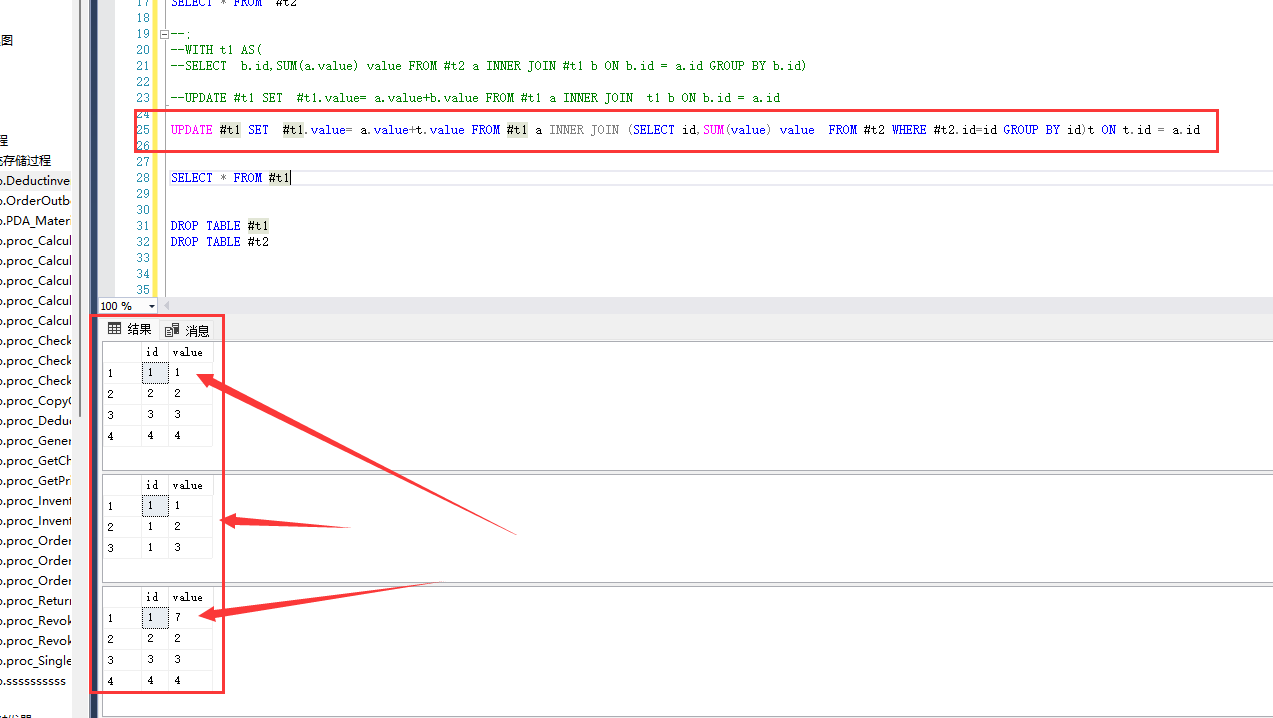
这就舒服了,终于实现了我要的效果,这是使用子查询的
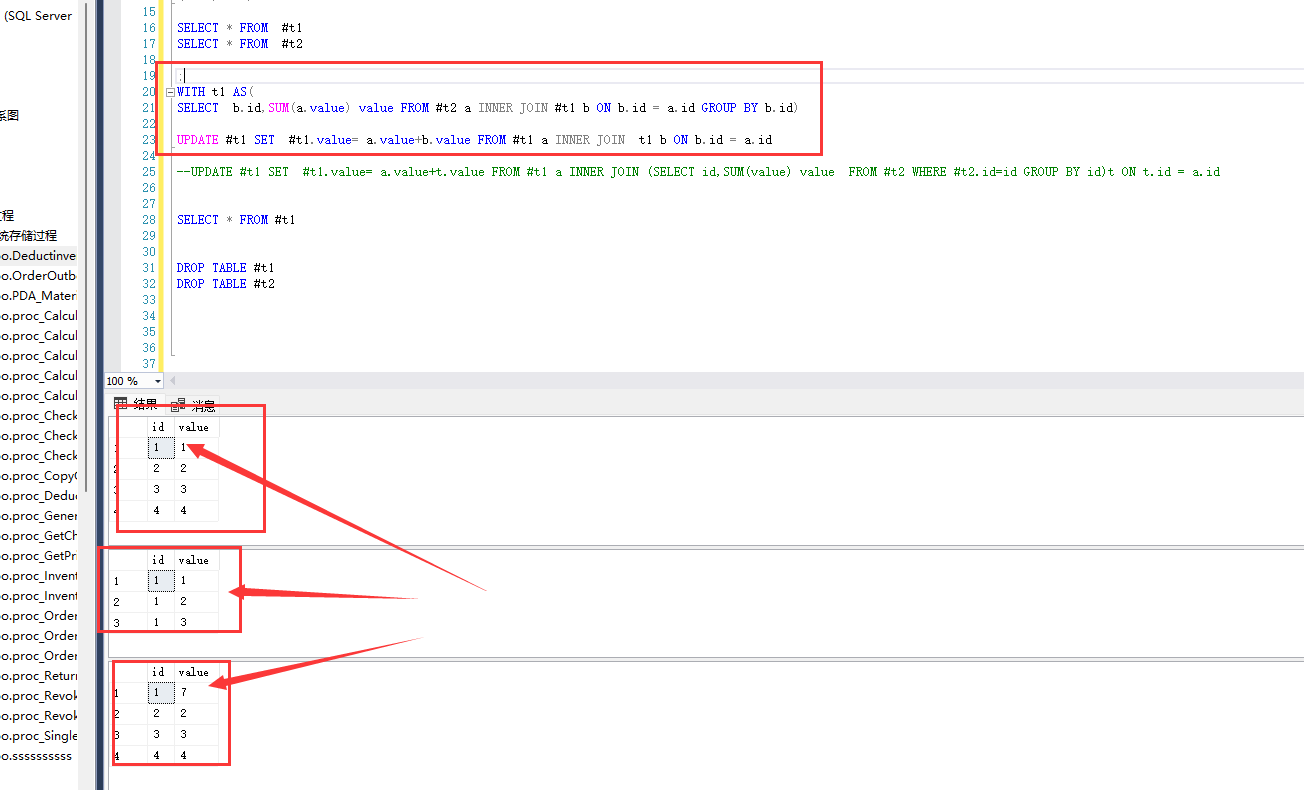
这就比较爽了,至于循环就自己下去试一下,可以用游标,也可以用while循环
游标直接修改就行了,用while循环,要先给参考表一个行号,可以用 ROW_NUMBER() 实现
具体看自己,今天分享结束了,想想就后怕,这么大个坑,出问题就GG了,今天分享出来,也希望给大家一个参考
SQL Server 根据一个表数据修改另外一个表数据的更多相关文章
- Sql Server 中将由逗号“,”分割的一个字符串转换为一个表集,并应用到 in 条件中
Sql Server 中将由逗号“,”分割的一个字符串,转换为一个表,并应用与 in 条件 ,,) 这样的语句和常用,但是如果in 后面的 1,2,3是变量怎么办呢,一般会用字符串连接的方式构造sql ...
- SQL SERVER 使用BULK Insert将txt文件中的数据批量插入表中(1)
1/首先建立数据表 CREATE TABLE BasicMsg( RecvTime FLOAT NOT NULL , --接收时间,不存在时间相同的数据 AA INT NOT NULL, --24位地 ...
- 在SQL Server 2008 Management Studio中修改表字段顺序
有时我们可能需要为一个已存在的数据库表添加字段,并且想让这个字段默认排的靠前一些,这时就需要为表字段重新进行排序,默认情况下在Management Studio中调整顺序并保存时会提示"不允 ...
- 在SQL Server 2018 Management Studio中修改表字段顺序
有时我们可能需要为一个已存在的数据库表添加字段,并且想让这个字段默认排的靠前一些,这时就需要为表字段重新进行排序,默认情况下在Management Studio中调整顺序并保存时会提示“不允许保存更改 ...
- SQL Server 游标运用:查看所有数据库所有表大小信息(Sizes of All Tables in All Database)
原文:SQL Server 游标运用:查看所有数据库所有表大小信息(Sizes of All Tables in All Database) 一.本文所涉及的内容(Contents) 本文所涉及的内容 ...
- SQL Server 2008 安装过程中遇到“性能计数器注册表配置单元一致性”检查失败 问题的解决方法
操作步骤: 1. 在 Microsoft Windows 2003 或 Windows XP 桌面上,依次单击"开始"."运行",然后在"打开&quo ...
- SQL Server— 存在检测、建库、 建表、约束、外键、级联删除
/******************************************************************************** *主题: SQL Server- 存 ...
- SQL SERVER 2005中如何获取日期(一个月的最后一日、上个月第一天、最后一天、一年的第一日等等)
原文:[转]SQL SERVER 2005中如何获取日期(一个月的最后一日.上个月第一天.最后一天.一年的第一日等等) 在网上找到的一篇文章,相当不错哦O(∩_∩)O~ //C#本周第一天 ...
- sql server 使用链接服务器连接Oracle,openquery查询数据
对接问题描述:不知道正式库oracle数据库账户密码,对方愿意在对方的客户端上输入账号和密码,但不告诉我们 解决方案:使用一台sql server作为中间服务器,可以通过转存数据到sql serv ...
- 在sql server中建存储过程,如果需要参数是一个可变集合怎么处理?
在sql server中建存储过程,如果需要参数是一个可变集合的处理 原存储过程,@objectIds 为可变参数,比如 110,98,99 ALTER PROC [dbo].[Proc_totalS ...
随机推荐
- 如何在Java中做基准测试?JMH使用初体验
大家好,我是王有志,欢迎和我聊技术,聊漂泊在外的生活.快来加入我们的Java提桶跑路群:共同富裕的Java人. 最近公司在搞新项目,由于是实验性质,且不会直接面对客户的项目,这次的技术选型非常激进,如 ...
- 关于微人事中POI导入文件到数据库的异常以及自己的一些技术心得
前言 在近四个月的时间里面,我的微人事项目才逐渐接近尾声,在昨天的测试接口中出现了两次数组越界以及一次空指针异常,三处异常我都通过吊事bug根据项目实际情况解决了,但是在空指针异常那里还是带有疑问,起 ...
- 基于SqlSugar的开发框架循序渐进介绍(26)-- 实现本地上传、FTP上传、阿里云OSS上传三者合一处理
在前面介绍的随笔<基于SqlSugar的开发框架循序渐进介绍(7)-- 在文件上传模块中采用选项模式[Options]处理常规上传和FTP文件上传>中介绍过在文件上传处理的过程中,整合了本 ...
- RDIFramework.NET开发框架用户字典助力Saas数据字典应用
1.概述 在某些特殊应用(如:SaaS)中,系统内置的字典项有可能不能完全满足用户的需求,他们需要自己定义相应的数据项,我们框架完全支持这类应用,用户字典管理主界面如下图所示. 2.功能展示 需要说明 ...
- cocos2d-x场景间参数传递
1>使用全局变量 这个就不详细说明了. 2>切换时传递 2.1>在secondScene.h 中加入成员变量,如 int sceneNum; 并在 ...
- 笔记:C++学习之旅---引用
笔记:C++学习之旅---引用 什么是引用? 引用就是别名,引用并非对象,相反的,他只是为一个已经存在的对象所起的另外一个名字. /*引用就是别名*/ #include <iostream> ...
- 苦苦搞了半个通宵才搞定的直接使用Sliverlight将文件PUT到阿里云OSS
为了公司的项目,小的我各种折腾啊,不过高兴的是实现了Silverlight直接提交至阿里云OSS的文件上传,文件上传再也不用通过服务器中转了. 研究SDK发现还有个Node-oss.js,但还没进行测 ...
- Linux修改系统时间(手动/自动同步)
一.手动修改 1.在终端窗口中输入date来查看系统当前的时间. 2.使用命令:"date -s 完整日期时间(YYYY-MM-DD hh:mm:ss)" 3.最后使用命令:&qu ...
- 2023-05-11:给你一个 m x n 的二进制矩阵 grid, 每个格子要么为 0 (空)要么为 1 (被占据), 给你邮票的尺寸为 stampHeight x stampWidth。 我们想将
2023-05-11:给你一个 m x n 的二进制矩阵 grid, 每个格子要么为 0 (空)要么为 1 (被占据), 给你邮票的尺寸为 stampHeight x stampWidth. 我们想将 ...
- 2022-02-15:扫地机器人。 房间(用格栅表示)中有一个扫地机器人。 格栅中的每一个格子有空和障碍物两种可能。 扫地机器人提供4个API,可以向前进,向左转或者向右转。每次转弯90度。 当扫地机
2022-02-15:扫地机器人. 房间(用格栅表示)中有一个扫地机器人. 格栅中的每一个格子有空和障碍物两种可能. 扫地机器人提供4个API,可以向前进,向左转或者向右转.每次转弯90度. 当扫地机 ...