python利用flux基本读写influxDB
1、读取
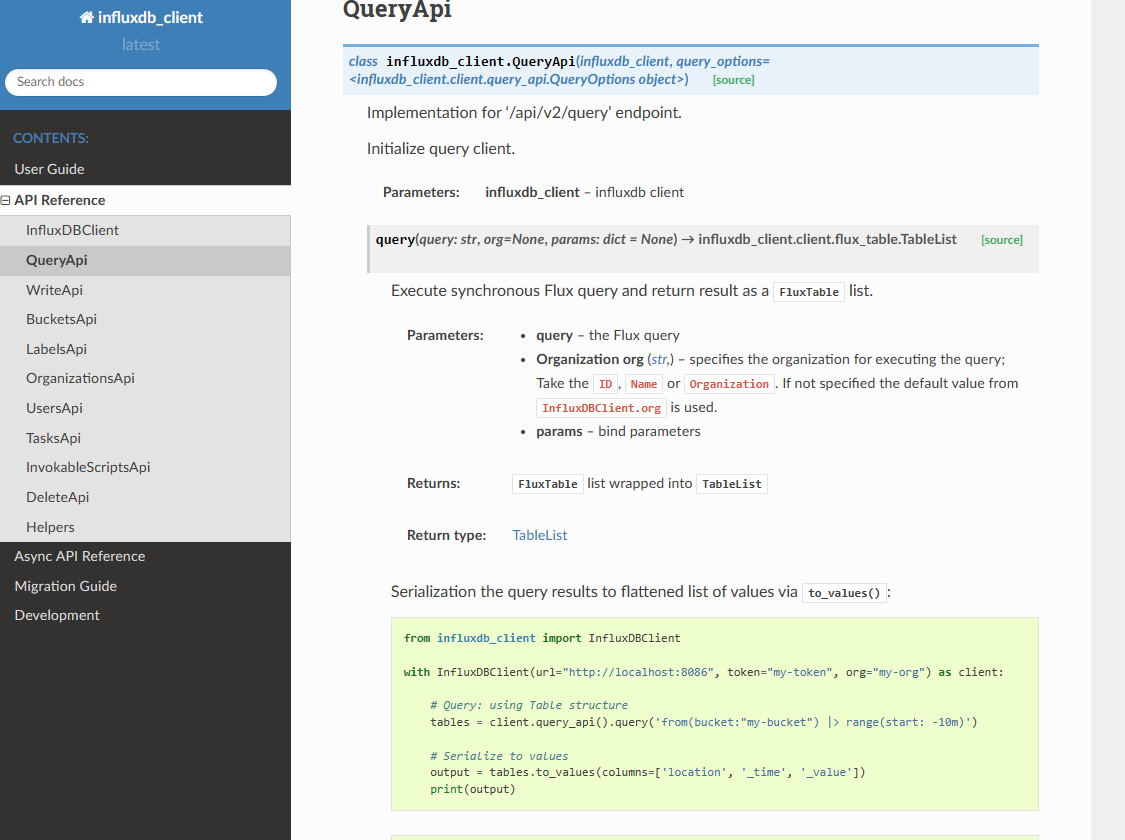
QuerApi 形式
python 利用 flux 语句查询 influxdb 数据。
https://influxdb-client.readthedocs.io/en/latest/api.html#queryapi
代码
from influxdb_client import InfluxDBClient
client = InfluxDBClient(url="http://...:8086",
token='',
org="*")
query_api = client.query_api()
data_frame = query_api.query('from(bucket: "test")'
'|> range(start: 2000-01-01T00:00:00Z, stop: 2000-01-02T00:00:00Z)'
'|> filter(fn: (r) => r["_measurement"] == "test")'
'|> filter(fn: (r) => r["_field"] == "heat" or r["_field"] == "cool")'
'|> aggregateWindow(every: 10m, fn: mean, createEmpty: false)'
'|> yield(name: "mean")')
print(data_frame.to_string())说明
● url:为数据库的地址与端口
● token:为连接的密匙,(类似形式:K4***************************************Sng==)
在 Load Data 栏中选择 API Tokens 进入创建密匙


● org:为数据库的组织名
● query()括号内的为 influxDB 支持的 flux 数据查询语法
InfluxDB 2.0 的数据查询语法 - InfluxDB - 大象笔记 (sunzhongwei.com)
(76条消息) 【InfluxDB V2.0】介绍与使用,flux查询、数据可视化_xbl丶的博客-CSDN博客_influxdb 可视化
也可由 influxdb 网页自动生成,方法如下:

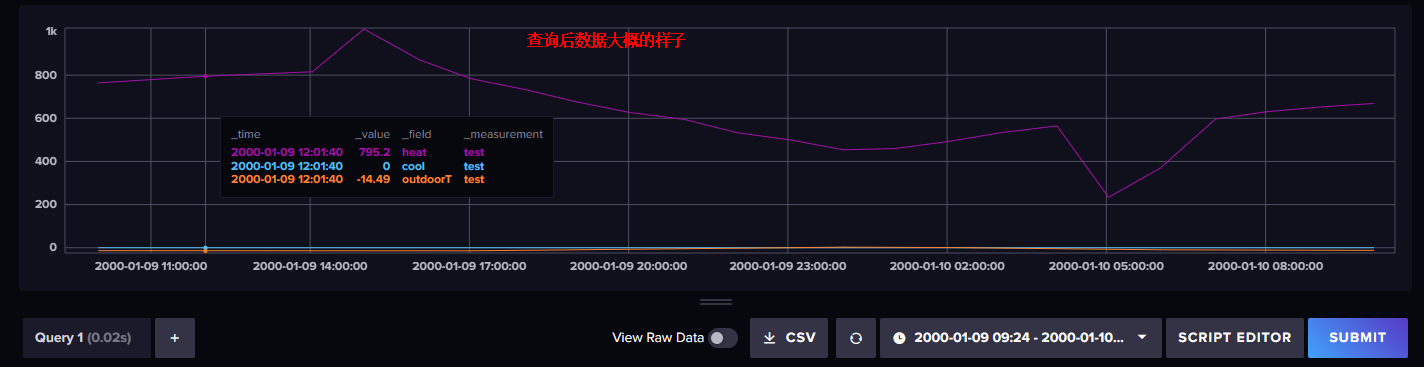
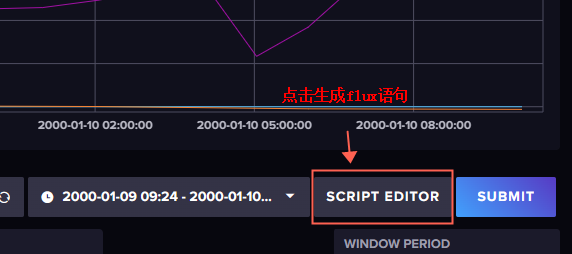
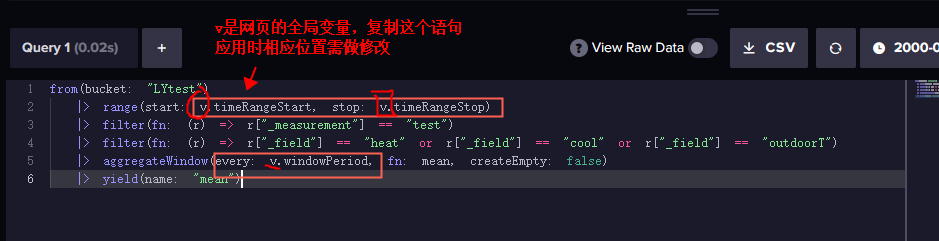
数据返回
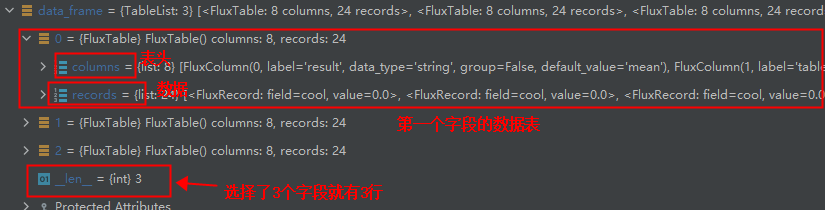
扩展
to JSONSerialize to JSON
output = tables.to_json(indent=5)
print(output)
to CSV
query()函数改成 query_csv()Query: using CSV iterator
csv_iterator = client.query_api().query_csv('from(bucket:"my-bucket") |> range(start: -10m)')
Serialize to values
output = csv_iterator.to_values()
print(output)
to pandas dataframe
query()函数改成 query_data_frame(),同时 flux 语句增加一行‘|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")’用于返回数据表的规范化。而且最好只读取一项字段的数据,不然会出现告警。Post 的读取形式
InfluxDB v2.6 API documentation (influxdata.com)
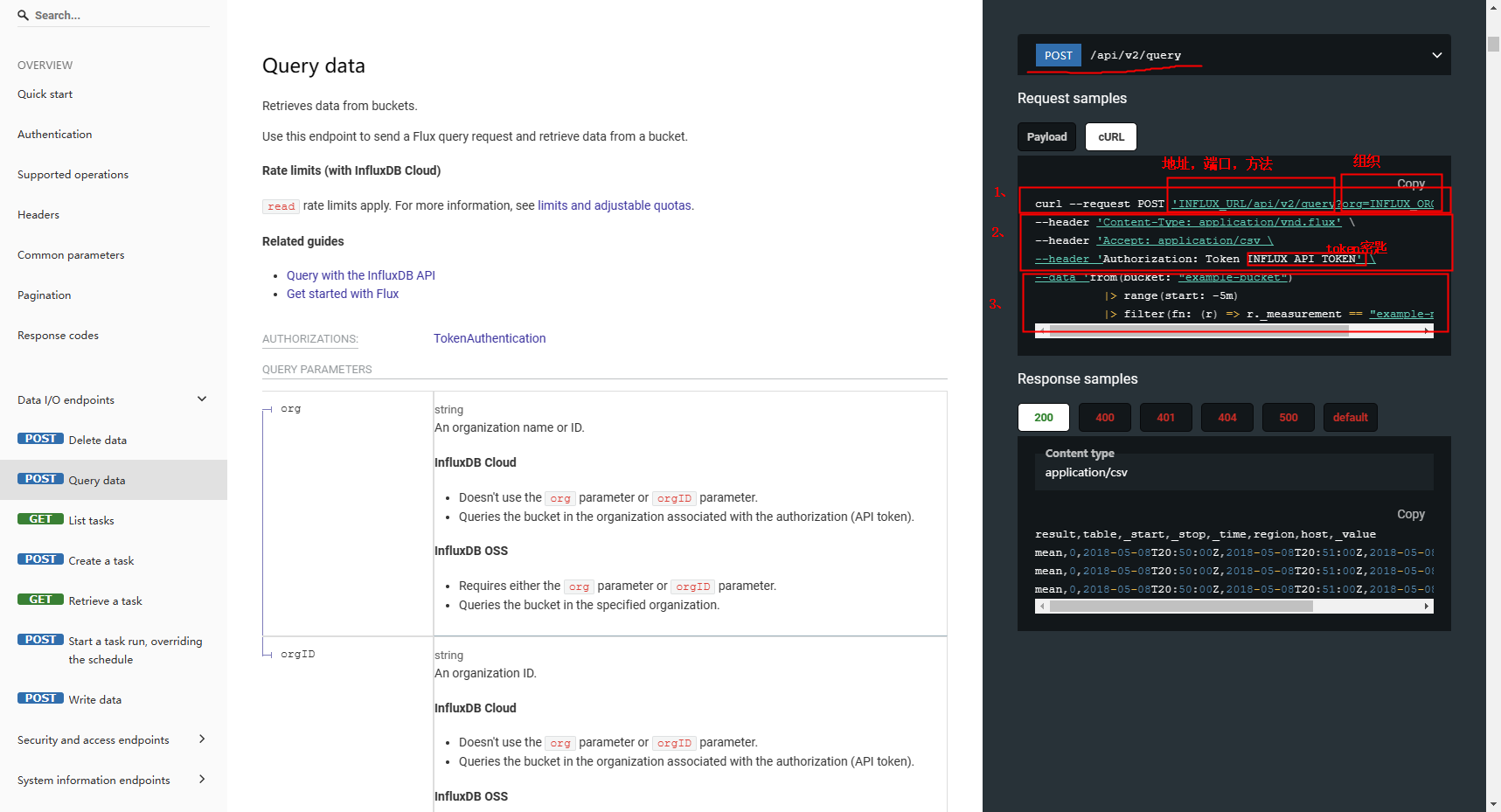
在 postman 中测试
● Post 的地址: 192.168.*.:8086/api/v2/query?org=组织
● headers 填写:
--header 'Content-Type: application/vnd.flux'
--header 'Accept: application/csv
--header 'Authorization: Token INFLUX_API_TOKEN'
其中INFLUX_API_TOKEN'替换为获取的 token 密匙

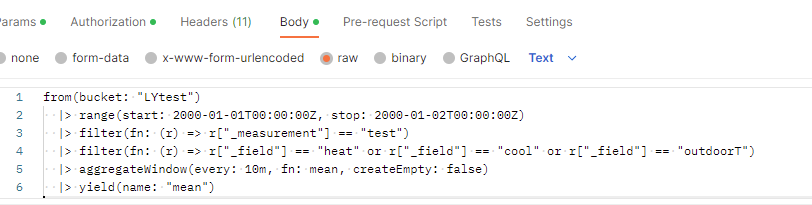
● 在 body 中选择 ray 然后填写 flux 查询语句。
python利用flux基本读写influxDB的更多相关文章
- python:利用configparser模块读写配置文件
在自动化测试过程中,为了提高脚本的可读性和降低维护成本,将一些通用信息写入配置文件,将重复使用的方法写成公共模块进行封装,使用时候直接调用即可. 这篇博客,介绍下python中利用configpars ...
- python基础之文件读写
python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使用os模块的一些方法如下: 得到 ...
- [Python] 利用Django进行Web开发系列(二)
1 编写第一个静态页面——Hello world页面 在上一篇博客<[Python] 利用Django进行Web开发系列(一)>中,我们创建了自己的目录mysite. Step1:创建视图 ...
- python利用or在列表解析中调用多个函数.py
python利用or在列表解析中调用多个函数.py """ python利用or在列表解析中调用多个函数.py 2016年3月15日 05:08:42 codegay & ...
- python使用xlrd模块读写Excel文件的方法
本文实例讲述了python使用xlrd模块读写Excel文件的方法.分享给大家供大家参考.具体如下: 一.安装xlrd模块 到python官网下载http://pypi.python.org/pypi ...
- 第二篇:python基础之文件读写
python基础之文件读写 python基础之文件读写 本节内容 os模块中文件以及目录的一些方法 文件的操作 目录的操作 1.os模块中文件以及目录的一些方法 python操作文件以及目录可以使 ...
- python 利用 ogr 写入shp文件,数据格式
python 利用 ogr 写入 shp 文件, 定义shp文件中的属性字段(field)的数据格式为: OFTInteger # 整型 OFTIntegerList # 整型list OFTReal ...
- 使用Python对Excel进行读写操作
学习Python的过程中,我们会遇到Excel的读写问题.这时,我们可以使用xlwt模块将数据写入Excel表格中,使用xlrd模块从Excel中读取数据.下面我们介绍如何实现使用Python对Exc ...
- python之文件的读写和文件目录以及文件夹的操作实现代码
这篇文章主要介绍了python之文件的读写和文件目录以及文件夹的操作实现代码,需要的朋友可以参考下 为了安全起见,最好还是给打开的文件对象指定一个名字,这样在完成操作之后可以迅速关闭文件,防止一些无用 ...
- Python利用pandas处理Excel数据的应用
Python利用pandas处理Excel数据的应用 最近迷上了高效处理数据的pandas,其实这个是用来做数据分析的,如果你是做大数据分析和测试的,那么这个是非常的有用的!!但是其实我们平时在做 ...
随机推荐
- 推荐两款HTTP请求Mock利器
1.背景 在日常测试过程中或者研发开发过程中,目前接口暂时没有开发完成,测试人员又要提前介入接口测试中,测试人员不仅仅只是简单的编写测试用例,也可以通过一些mock的方法进行来提前根据接口测试的情况进 ...
- 重新点亮linux 命令树————用户和用户组管理[六]
前言 简单整理一下用户和用户组管理. 正文 主要是介绍下面的命令: useradd 新建用户 userdel 删除用户 passwd 修改用户面 usermod 修改用户属性 chage 修改用户属性 ...
- 深入探讨下SSR与CSR有啥不同
随着互联网技术的迅速发展,用户对网页的加载速度和交互体验有了更高的期待.作为开发者,我们常常需要在服务器端渲染(SSR)与客户端渲染(CSR)之间做出选择.这两种渲染方式各有特点,适用于不同的场景和需 ...
- 建设工程工程量清单计价规范2008最新分析报告ppt
2008版<计价规范>颁布的背景 国务院从2003年起,在全国范围开展清理拖欠工程款.清理拖欠农民工工资的活动.最高人民法院于2004年9月29日发布了<关于审理建设工程施工合同纠纷 ...
- 顺通鞋业MES生产工单管理系统软件
顺通鞋业MES管理系统的"生产执行"是办公室和车间信息交互的枢纽,是一款针对大型鞋业生产企业开发的可配置化智能制造管理系统.工人可以通过车间终端(如安装在机器旁的固定工业触摸屏或移 ...
- 【产品能力深度解读】连续入围Gartner魔力象限的Quick BI有何魔力?
简介: 国际权威分析机构Gartner发布2021年商业智能和分析平台魔力象限报告,阿里云Quick BI再度入选,并继续成为该领域魔力象限唯一入选的中国企业. Quick BI凭借在增强分析能力上的 ...
- 使用AirFlow调度MaxCompute
简介: airflow是Airbnb开源的一个用python编写的调度工具,基于有向无环图(DAG),airflow可以定义一组有依赖的任务,按照依赖依次执行,通过python代码定义子任务,并支持各 ...
- MSBuild 输出日志可视化工具 MSBuild Structured Log Viewer 简介
感谢 Vatsan Madhavan 小伙伴推荐的 MSBuild 输出日志可视化工具,这个工具可以使用漂亮的 WPF 界面预览 MSBuild 复杂的输出内容 这是一个完全开源的工具,请看 Kiri ...
- 17.prometheus服务发现&基于文件的服务发现
一.服务发现 Prometheus 中是如何使用服务发现来查找和抓取目标的.我们知道在 Prometheus 配置文件中可以通过一个 static_configs 来配置静态的抓取任务,但是在云环境下 ...
- pde复习笔记 第一章 波动方程 第六节 能量不等式、波动方程解的唯一性和稳定性
能量不等式 这一部分需要知道的是能量的表达式 \[E(t)=\int_{0}^{l}u_{t}^{2}+a^{2}u_{x}^{2} dx \] 一般而言题目常见的问法是证明能量是减少的,也就是我们需 ...