利用pytorch自定义CNN网络(一):torchvision工具箱
本文是利用pytorch自定义CNN网络系列的第一篇,主要介绍 torchvision工具箱及其使用,关于本系列的全文见这里。
笔者的运行设备与软件:CPU (AMD Ryzen 5 4600U) + pytorch (1.13,CPU版) + jupyter;
本文所用到的资源:链接:https://pan.baidu.com/s/1WgW3IK40Xf_Zci7D_BVLRg 提取码:1212
1. torchvision简介
torchvision是基于pytorch的工具箱,主要用来处理图像数据,其内包含一些常用的数据集、模型、图像转换等。torchvision工具箱主要包含以下四大模块:
- torchvision.models:提供深度学习中各种经典的网络结构、预训练好的模型,如:Alex-Net、VGG、ResNet、Inception等。
- torchvision.datasets:提供常用的数据集,设计上继承torch.utils.data.Dataset,主要包括:MNIST、CIFAR10/100、ImageNet、COCO等。
- torchvision.transforms:提供常用的数据预处理操作,主要包括对Tensor及PIL Image对象的操作。
- torchvision.utils:工具类,如保存张量作为图像到磁盘,给一个小批量创建一个图像网格。
2. torchvision.models简述
torchvision.models模块包含以下模型结构,AlexNet、VGG、GoogLeNet、ResNet、SqueezeNet、DenseNet等常用模型结构。其中,每个模型结构又可以根据卷积核大小、网络层深度等细分成不同的模型。例如,ResNet就提供了5种不同深度的模型,分别为resnet18、resnet34、resnet50、resnet101、resnet152。
2.1. 加载预训练模型及其参数权重
torchvision提供了各种模型的预训练模型,我们可以在此基础上针对性地调整,这大大减少了工作量。加载预训练模型的过程如下,这里以resnet18模型为例。
import torchvision
resnet18 = torchvision.models.resnet18(pretrained=True)
以上代码运行结果:
预训练模型加载完成后我们可以model.atate_dict()方法查看训练好的权重。
resnet18.state_dict()
部分运行结果:
现在,让我们进一步了解torchvision.models.resnet18()。
语法:torchvision.models.resnet18(*, weights: Union[torchvision.models.resnet.ResNet18_Weights, NoneType] = None, progress: bool = True, **kwargs: Any) ---> torchvision.models.resnet.ResNet
参数:Union---是否使用预训练权重,默认不使用;当pretrained=True,使用预训练权重。
备注:resnet18 = torchvision.models.resnet18(),表示随机初始化权重创建模型。
2.2. 加载预训练模型并自定义参数权重
我们也可以只加载模型的网络结构,然后置入自定义的参数权重(该参数权重一定要符合该网络结构)。
import torchvision
# 导入模型的网络结构,并随机初始化参数权重
resnet18 = torchvision.models.resnet18()
# 查看随机参数权重
resnet18.state_dict()
# 加载本地的参数权重
resnet18.load_state_dict(torch.load("D:\\Users\\CV learning\\pytorch\\data\\resnet18-f37072fd.pth"))
# 查看加载后的参数权重
resnet18.state_dict()
2.3. 调整预训练模型
预训练的模型有些层并不是直接能用,需要我们微微改一下,比如,resnet最后的全连接层是分1000类,而我们只有21类;或resnet第一层卷积接收的通道是3, 我们可能输入图片的通道是4,那么可以通过以下方法修改:
from torchvision import models
from torch import nn
resnet34 = models.resnet34(pretrained=True, num_classes=1000)
# 默认是ImageNet上的1000分类,这里修改最后的全连接层为10分类问题
resnet34.fc = nn.Linear(512, 10)
3. torchvision.datasets简述
提供常用的数据集,设计上继承torch.utils.data.Dataset,主要包括:MNIST、Fashion-MNIST、CIFAR10/100、ImageNet、COCO等。
3.1. 加载网络数据集
torchvision提供的数据集允许从网络上下载,具体使用方法如下,我们以加载Fashion-MNIST为例。
from torchvision import datasets
data_train = datasets.FashionMNIST("D:\\Users\\CV learning\\pytorch\\data\\",
download=True, train=False, transform=None)
现在,让我们详细了解一下torchvision.datasets.FashionMNIST()。
语法:torchvision.datasets.FashionMNIST(root, train=True, transform=None, target_transform=None, download=False)
参数:
root---存放MNIST/processed/training.pt和MNIST/processed/test.pt的数据集的根目录。即,存放下载的或是要加载的数据集的根目录。
train---可选,如果为True,则从training.pt创建数据集,否则从test.pt创建数据集。
transform---可选,即图像变换操作。
target_transform---可选,接受目标并对其进行转换的函数/转换。
download---可选,如果为true,则从internet下载数据集并将其放在根目录中。如果数据集已下载,则不会再次下载。
备注:不同数据集的对应的函数不同,详见Datasets — Torchvision 0.15 documentation。
3.2. 加载本地数据集
torchvision.datasets.ImageFolder可以用来加载本地数据集,它要求我们以下面这种格式来组织数据集的训练、验证或者测试图片。
语法:dataset=torchvision.datasets.ImageFolder(root, transform=None,target_transform=None, loader=, is_valid_file=None)
参数:
root---图片存储的根目录,即各类别文件夹所在目录的上一级目录。
transform---对图片进行预处理的操作(函数),原始图片作为输入,返回一个转换后的图片。
target_transform---对图片类别进行预处理的操作,输入为 target,输出对其的转换。 如果不传该参数,即对 target 不做任何转换,返回的顺序索引 0,1, 2…。root下的每个文件夹为一个类别。
loader---表示数据集加载方式,通常默认加载方式即可。
is_valid_file---获取图像文件的路径并检查该文件是否为有效文件的函数(用于检查损坏文件)
返回:返回的是一个dataset(也可以理解为Dataset的一个子类),它的结构就是[(img_data,class_id),(img_data,class_id),…]。
返回值的属性:
self.classes:用一个 list 保存类别名称。
self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应。
self.imgs:保存(img-path, class) tuple的 list。
备注:torchvision.datasets.ImageFolder()的源码链接:torchvision.datasets.folder — Torchvision 0.15 documentation
from torchvision.datasets import ImageFolder
from torchvision import transforms
transform = transforms.ToTensor()
root = "D:\\Users\\CV learning\\pytorch\\data\\an"
dataset = ImageFolder(root, transform=transform)
print(dataset[0])
print(dataset.classes) #根据分的文件夹的名字来确定的类别
print(dataset.class_to_idx) #按顺序为这些类别定义索引为0,1...
print(dataset.imgs) #返回从所有文件夹中得到的图片的路径以及其类别
'''
(tensor([[[0.7961, 0.7961, 0.8000, ..., 0.9412, 0.9373, 0.9333],
[0.7961, 0.7961, 0.8000, ..., 0.9451, 0.9412, 0.9333],
[0.7961, 0.7961, 0.8000, ..., 0.9451, 0.9412, 0.9373],
...,
[0.6000, 0.6000, 0.6000, ..., 0.0078, 0.0078, 0.0078],
[0.5961, 0.5961, 0.5961, ..., 0.0078, 0.0078, 0.0078],
[0.5922, 0.5922, 0.5922, ..., 0.0039, 0.0039, 0.0039]],
[[0.6431, 0.6431, 0.6471, ..., 0.7882, 0.7843, 0.7804],
[0.6431, 0.6431, 0.6471, ..., 0.7922, 0.7882, 0.7804],
[0.6431, 0.6431, 0.6471, ..., 0.7922, 0.7882, 0.7843],
...,
[0.4784, 0.4784, 0.4784, ..., 0.0078, 0.0078, 0.0078],
[0.4745, 0.4745, 0.4745, ..., 0.0078, 0.0078, 0.0078],
[0.4706, 0.4706, 0.4706, ..., 0.0039, 0.0039, 0.0039]],
[[0.3412, 0.3412, 0.3451, ..., 0.4784, 0.4745, 0.4706],
[0.3412, 0.3412, 0.3451, ..., 0.4824, 0.4784, 0.4706],
[0.3412, 0.3412, 0.3451, ..., 0.4824, 0.4784, 0.4745],
...,
[0.2157, 0.2157, 0.2157, ..., 0.0000, 0.0000, 0.0000],
[0.2118, 0.2118, 0.2118, ..., 0.0000, 0.0000, 0.0000],
[0.2078, 0.2078, 0.2078, ..., 0.0000, 0.0000, 0.0000]]]), 0)
['cat', 'dog']
{'cat': 0, 'dog': 1}
[('D:\\Users\\CV learning\\pytorch\\data\\an\\cat\\cat.0.jpg', 0),
('D:\\Users\\CV learning\\pytorch\\data\\an\\cat\\cat.1.jpg', 0),
('D:\\Users\\CV learning\\pytorch\\data\\an\\cat\\cat.2.jpg', 0),
('D:\\Users\\CV learning\\pytorch\\data\\an\\dog\\dog.0.jpg', 1),
('D:\\Users\\CV learning\\pytorch\\data\\an\\dog\\dog.1.jpg', 1),
('D:\\Users\\CV learning\\pytorch\\data\\an\\dog\\dog.2.jpg', 1)]
'''
4. torchvision.transforms简述
transforms包含了一些图像预处理操作,这些操作可以使用torchvison.transforms.Compose连在一起进行串联操作。这些操作有:
__all__ = ["Compose", "ToTensor", "ToPILImage", "Normalize", "Resize",
"CenterCrop", "Pad", "Lambda", "RandomApply", "RandomChoice", "RandomOrder",
"RandomCrop", "RandomHorizontalFlip", "RandomVerticalFlip", "RandomResizedCrop",
"RandomSizedCrop", "FiveCrop", "TenCrop", "LinearTransformation", "ColorJitter",
"RandomRotation", "RandomAffine", "Grayscale", "RandomGrayscale"]
- Compose():用来管理所有的transforms操作。
- ToTensor():把图片数据转换成张量并转化范围在[0,1]区间内。
- ToPILImage():将Tensor或numpy.ndarray转换为PIL Image。
- Normalize(mean, std):归一化(标准化)。具体见,pytorch中归一化transforms.Normalize的真正计算过程
- Resize(size):输入的PIL图像调整为指定的大小,参数可以为int或int元组。
- CenterCrop(size):将给定的PIL Image进行中心切割,得到指定size的tuple。
- Pad(padding, fill=0, padding_mode=‘constant’):对PIL边缘进行填充。
- RandomApply(transforms, p=0.5):随机选取变换。
- RandomCrop(size, padding=0):随机中心点切割。size可以是tuple也可以是Integer
- RandomHorizontalFlip():随机水平翻转给定的PIL Image。
- RandomVerticalFlip():随机垂直翻转给定的PIL Image。
- FiveCrop(size):将给定的PIL图像裁剪成4个角落区域和中心区域。
- RandomAffine(degrees, translate=None, scale=None):保持中心不变的图片进行随机仿射变化。
- Grayscale(num_output_channels=1):对图像进行灰度变换。
备注:torchvision.transforms.Compose()的源码链接:torchvision.transforms.transforms — Torchvision 0.15 documentation
我们可以将transfors.Compose类的实例化可以理解成生成一个图像变换器,实例化过程中传入的参数就是图像的变换操作,操作之间是串联关系。
import torch
import torchvision
from torchvision import transforms
from PIL import Image
import matplotlib.pyplot as plt
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((300, 300)),
transforms.RandomAffine(degrees=30),
transforms.RandomHorizontalFlip(),
transforms.ToPILImage()])
img = Image.open("D:\\Users\\CV learning\\opencv learning\\image\\lena.jpg")
imgs1 = transform(img)
imgs2 = transform(img)
imgs3 = transform(img)
plt.subplot(1, 3, 1), plt.imshow(imgs1), plt.title("img1")
plt.subplot(1, 3, 2), plt.imshow(imgs2), plt.title("img2")
plt.subplot(1, 3, 3), plt.imshow(imgs3), plt.title("img3")
plt.show()
运行结果:
注:需要注意的是transforms模块中类或函数的操作对象是torch.Tensor类或PIL.Image.Image类。
5. torchvision.utils简述
torchvision.utils模块主要介绍两个函数,即torchvision.utils.make_grid()和torchvision.utils.save_image()函数。
5.1. torchvision.utils.make_grid()
torchvision.utils.make_grid()将多张图像组合成一张网格图像,和九宫格图像挺像的。
语法:torchvision.utils.make_grid(tensor: Union[Tensor, List[Tensor]], nrow: int = 8, padding: int = 2, normalize: bool = False, value_range: Optional[Tuple[int, int]] = None, scale_each: bool = False, pad_value: float = 0.0, kwargs) ---> torch.Tensor
参数:**
tensor(Tensor or list)---4维张量(Tensor.shape=(B x C x H x W))或相同尺寸的图像。
nrow(int, 可选 )---网格中每行显示的图像数量。
padding(int, 可选)---图像之间的填充像素数。
normalize(bool, 可选)---如果为True,将网格图像使用value_range的最小值和最大值进行归一化。
value_range (tuple, 可选)---归一化图像的最小值和最大值。默认情况下,最小值和最大值从张量计算。
scale_each (bool, 可选)---缩放批中的每个图像 图像单独显示,而不是所有图像上的(最小值、最大值)。
pad_value (float, 可选)---填充像素的大小。
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision
import matplotlib.pyplot as plt
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((300, 300))])
root = "D:\\Users\\CV learning\\pytorch\\data\\an"
dataset = ImageFolder(root, transform=transform)
data_loder = DataLoader(dataset=dataset, batch_size=32, shuffle=True)
for imgs, label in data_loder:
img_tensor = torchvision.utils.make_grid(imgs, nrow=8, padding=10)
imgs = transforms.ToPILImage()(img_tensor)
plt.imshow(imgs)
运行结果如下: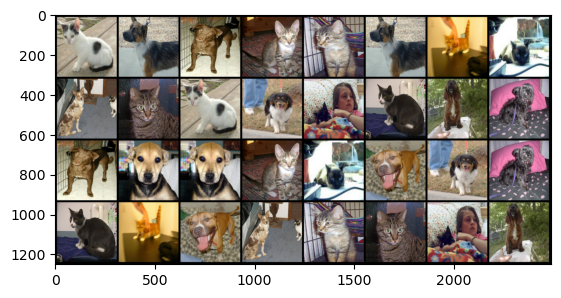
5.2. torchvision.utils.save_image()
torchvision.utils.save_image()函数只能保存RGB彩色图像,如果网络的输出是单通道灰度图像,则该函数依然会输出三个通道,每个通道的数值都是相同的,即“伪灰度图像”。
语法:torchvision.utils.save_image(tensor: Union[torch.Tensor, List[torch.Tensor]], fp: Union[str, pathlib.Path, BinaryIO], format: Union[str, NoneType] = None, kwargs) ---> None
参数:**
tensor(Tensor or list)---要保存的图像的张量。如果是B x C x H x W形式的四维张量,需要将其转换为网格图像进行保存。
fp (string or file object)---保存路径。
format (可选)--- 如果省略,则使用要使用的格式从文件名扩展名确定。如果使用文件对象而不是文件名,则应始终使用此参数。
from torchvision.datasets import ImageFolder
from torchvision import transforms
from torch.utils.data import DataLoader
import torchvision
transform = transforms.Compose([transforms.ToTensor(),
transforms.Resize((300, 300))])
root = "D:\\Users\\CV learning\\pytorch\\data\\an"
dataset = ImageFolder(root, transform=transform)
data_loder = DataLoader(dataset=dataset, batch_size=8, shuffle=True)
i=0
for imgs, label in data_loder:
img_tensor = torchvision.utils.make_grid(imgs, nrow=8, padding=10)
torchvision.utils.save_image(img_tensor, fp=f"D:\\Users\\CV learning\\pytorch\\data\\an\\{i}.jpg")
i+=1
6. 参考内容
- Pytorch torchvision库使用详情
- FashionMNIST — Torchvision 0.15 documentation
- torchvision.datasets.ImageFolder使用详解_HealthScience的博客-CSDN博客
- 【pytorch】transforms.Compose()使用
- make_grid — Torchvision 0.15 documentation
利用pytorch自定义CNN网络(一):torchvision工具箱的更多相关文章
- MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网络训练实现及比较(三)
版权声明:本文为博主原创文章,欢迎转载,并请注明出处.联系方式:460356155@qq.com 在前两篇文章MINIST深度学习识别:python全连接神经网络和pytorch LeNet CNN网 ...
- 07_利用pytorch的nn工具箱实现LeNet网络
07_利用pytorch的nn工具箱实现LeNet网络 目录 一.引言 二.定义网络 三.损失函数 四.优化器 五.数据加载和预处理 六.Hub模块简介 七.总结 pytorch完整教程目录:http ...
- Pytorch和CNN图像分类
Pytorch和CNN图像分类 PyTorch是一个基于Torch的Python开源机器学习库,用于自然语言处理等应用程序.它主要由Facebookd的人工智能小组开发,不仅能够 实现强大的GPU加速 ...
- ubuntu之路——day18 用pytorch完成CNN
本次作业:Andrew Ng的CNN的搭建卷积神经网络模型以及应用(1&2)作业目录参考这位博主的整理:https://blog.csdn.net/u013733326/article/det ...
- Pytorch写CNN
用Pytorch写了两个CNN网络,数据集用的是FashionMNIST.其中CNN_1只有一个卷积层.一个全连接层,CNN_2有两个卷积层.一个全连接层,但训练完之后的准确率两者差不多,且CNN_1 ...
- pytorch空间变换网络
pytorch空间变换网络 本文将学习如何使用称为空间变换器网络的视觉注意机制来扩充网络.可以在DeepMind paper 阅读更多有关空间变换器网络的内容. 空间变换器网络是对任何空间变换的差异化 ...
- Keras如何构造简单的CNN网络
1. 导入各种模块 基本形式为: import 模块名 from 某个文件 import 某个模块 2. 导入数据(以两类分类问题为例,即numClass = 2) 训练集数据data 可以看到,da ...
- [论文解读]CNN网络可视化——Visualizing and Understanding Convolutional Networks
概述 虽然CNN深度卷积网络在图像识别等领域取得的效果显著,但是目前为止人们对于CNN为什么能取得如此好的效果却无法解释,也无法提出有效的网络提升策略.利用本文的反卷积可视化方法,作者发现了AlexN ...
- 【深度学习系列】用PaddlePaddle和Tensorflow实现经典CNN网络AlexNet
上周我们用PaddlePaddle和Tensorflow实现了图像分类,分别用自己手写的一个简单的CNN网络simple_cnn和LeNet-5的CNN网络识别cifar-10数据集.在上周的实验表现 ...
- CNN眼中的世界:利用Keras解释CNN的滤波器
转载自:https://keras-cn.readthedocs.io/en/latest/legacy/blog/cnn_see_world/ 文章信息 本文地址:http://blog.keras ...
随机推荐
- 雪球 app 实战(1)
开头 因为理论篇结束之后,需要一个实战,估选用了雪球app作为一个作业 业务场景: 雪球 app 自选设置(入口位于 行情 模块) 作业内容 使用 百度脑图 编写 思维导图 [自选设置]模块的测试用例 ...
- 2022-04-09:给你两个长度分别 n 和 m 的整数数组 nums 和 multipliers ,其中 n >= m , 数组下标 从 1 开始 计数。 初始时,你的分数为 0 。 你需要执行恰
2022-04-09:给你两个长度分别 n 和 m 的整数数组 nums 和 multipliers ,其中 n >= m , 数组下标 从 1 开始 计数. 初始时,你的分数为 0 . 你需要 ...
- 让ChatGPT帮我写SQL
推荐一个Github上Start超过3.4K,可将自然语言转化为SQL语句的开源项目. 项目简介 这是一个利用ChatGPT,SQL与自然语言的翻译器.可以将自然语言转换为SQL语句,同样也可以把SQ ...
- 用BP软件 批量注册用户
第五步:查看管理员后台----用户界面, 有没有批量添加进用户
- ubuntu18 安装单机k8s v1.18.2
背景 当我们需要对k8s进行二次开发时,k8s环境是必须的,那么在ubuntu上部署单机k8s是最方便的,便于开发调试 系统准备 本人用的是Ubuntu18,以下以此为例 部署之前,最好切换至root ...
- 一文教会你用Apache SeaTunnel Zeta离线把数据从MySQL同步到StarRocks
在上一篇文章中,我们介绍了如何下载安装部署SeaTunnel Zeta服务(3分钟部署SeaTunnel Zeta单节点Standalone模式环境),接下来我们介绍一下SeaTunnel支持的第一个 ...
- 神经网络初步(Neural Network)——思想 具体实例以及代码实现
在前面我们详细的讨论过softmax损失函数以及SVM损失函数,以及应用了支持向量机进行图片分类的任务,不妨先复习一下支持向量机相关的思想内核:支持向量机想要寻求一组映射关系f(x)=wx+b,先将每 ...
- django:有关移除数据库出错问题
执行: 最终,通过执行迁移文件,我们将Django项目中创建的模型转化为MySql中的数据表. 执行迁移文件的两条命令: python manage.py makemigrations python ...
- Java中的三元运算,以后用得到!
前言 Java 中的三元运算,平时也叫做三目运算,大家了解吗?下面就详细介绍一下,以后在项目编程中用得到. 一.Java运算符 在最底层,Java 中的数据是通过使用运算符来操作的.运算符是一种特殊的 ...
- 01-C语言基础语法
目录 一. C语言发展史 二. 数据类型 三. 常量和变量 四. 字符串和转义字符 五. 选择语句 六. 循环语句 七. 函数 一. C语言发展史 1963 年ALGOL 60 作为C语言最早的模型, ...