折腾 Quickwit,Rust 编写的分布式搜索引擎 - 可观测性之分布式追踪
概述
分布式追踪是一种跟踪应用程序请求流经不同服务(如前端、后端、数据库等)的过程。它是一个强大的工具,可以帮助您了解应用程序的工作原理并调试性能问题。
Quickwit 是一个用于索引和搜索非结构化数据的云原生引擎,这使其非常适合用作追踪数据的后端。
此外,Quickwit 本地支持 OpenTelemetry gRPC 和 HTTP(仅 protobuf)协议 以及 Jaeger gRPC API(仅 SpanReader)。这意味着您可以使用 Quickwit 存储追踪数据,并通过 Jaeger UI 查询这些数据。
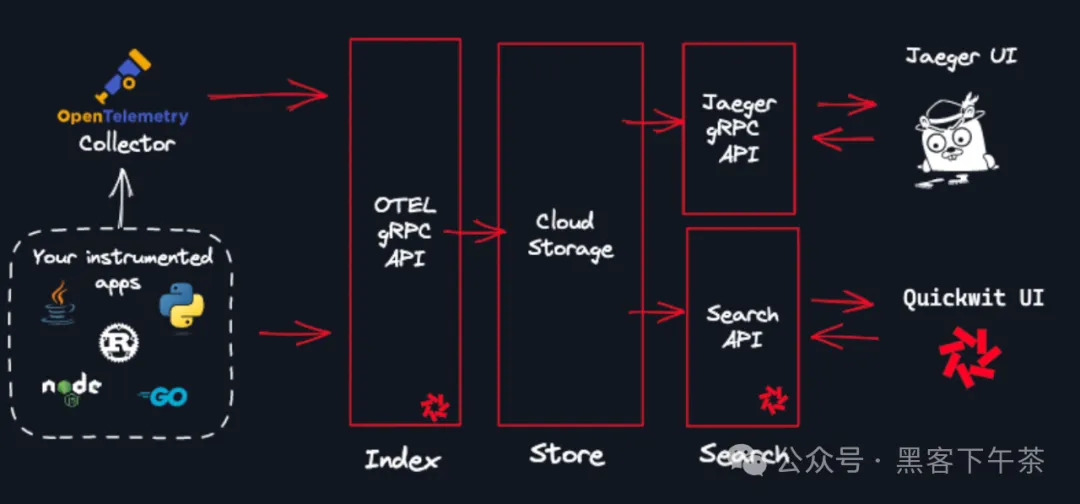
将 Quickwit 连接到 Jaeger
Quickwit 实现了一个与 Jaeger UI 兼容的 gRPC 服务。您只需要将 Jaeger 配置为使用 grpc-plugin 类型的(跨度)存储,就能够查看存储在任何匹配模式 otel-traces-v0_* 的 Quickwit 索引中的追踪数据。
官方制作了一个关于 如何将 Quickwit 连接到 Jaeger UI 的教程,将引导您完成整个过程。
向 Quickwit 发送追踪数据
将 Quickwit 连接至 Jaeger
我们将 Quickwit 的追踪数据发送到 Jaeger 并进行分析,这将生成新的追踪数据以供分析
启动 Quickwit
首先,启动一个启用了 OTLP 服务的 Quickwit 实例:
QW_ENABLE_OPENTELEMETRY_OTLP_EXPORTER=true \
OTEL_EXPORTER_OTLP_ENDPOINT=http://127.0.0.1:7281 \
./quickwit run
我们还设置了 QW_ENABLE_OPENTELEMETRY_OTLP_EXPORTER 和 OTEL_EXPORTER_OTLP_ENDPOINT 环境变量,以便 Quickwit 将其自身的追踪数据发送给自己。
启动 Jaeger UI
让我们使用 Docker 启动一个 Jaeger UI 实例。在这里我们需要告知 Jaeger 使用 Quickwit 作为其后端。
由于一些与容器网络相关的特殊性,我们需要在 MacOS 和 Windows 上采用一种方法,在 Linux 上采用另一种方法。
MacOS 与 Windows
我们可以依赖 host.docker.internal 来获取指向我们 Quickwit 服务器的 Docker 桥接 IP 地址。
docker run --rm --name jaeger-qw \
-e SPAN_STORAGE_TYPE=grpc-plugin \
-e GRPC_STORAGE_SERVER=host.docker.internal:7281 \
-p 16686:16686 \
jaegertracing/jaeger-query:latest
Linux
默认情况下,Quickwit 监听 127.0.0.1,并且不会响应指向 Docker 桥接 (172.17.0.1) 的请求。解决此问题有多种方法。最简单的方法可能是使用主机网络模式。
docker run --rm --name jaeger-qw --network=host \
-e SPAN_STORAGE_TYPE=grpc-plugin \
-e GRPC_STORAGE_SERVER=127.0.0.1:7281 \
-p 16686:16686 \
jaegertracing/jaeger-query:latest
在 Jaeger UI 中搜索追踪数据
由于 Quickwit 会索引其自身的追踪数据,因此在大约 5 秒后(这是 Quickwit 完成首次提交所需的时间),您应该能够在 Jaeger UI 中看到这些数据。
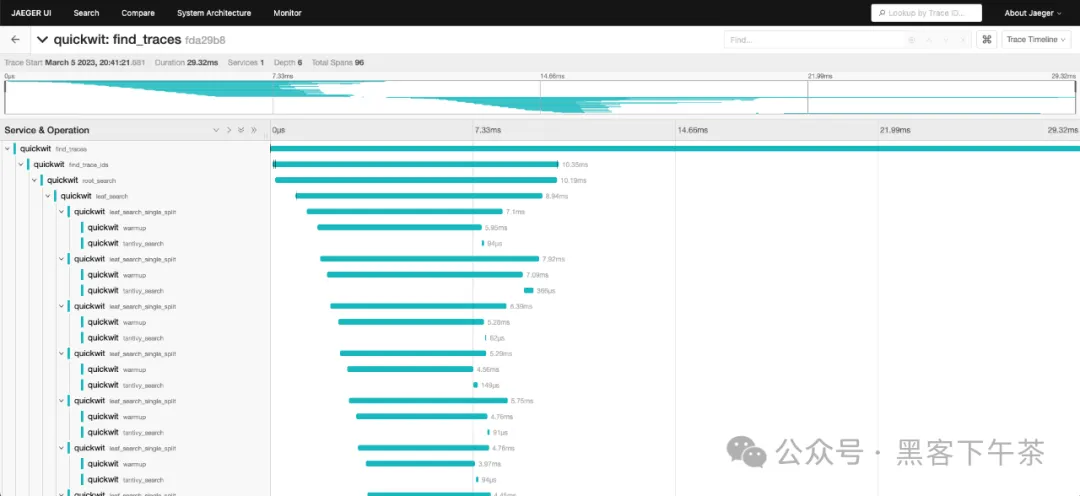
打开位于 http://localhost:16686 的 Jaeger UI 并搜索追踪数据!通过执行搜索查询,您将看到 Quickwit 自身的追踪数据:
find_traces是在 Jaeger UI 中搜索追踪数据时调用的端点,随后它会调用find_trace_ids。find_traces_ids对跨度执行聚合查询以获取唯一的追踪 ID。root_search是 Quickwit 的搜索入口点。它会在每个分片(索引的一部分)上并行地或分布式地调用搜索,如果只有一个节点,则仅在本地调用。leaf_search是每个节点上的搜索入口点。它会在每个分片上调用leaf_search_single_split。leaf_search_single_split是分片上的搜索入口点。它会依次调用warmup和tantivy_search。warmup是搜索的预热阶段。它预取执行搜索查询所需的数据。tantivy_search是搜索的执行阶段。它使用 Tantivy 高速执行搜索查询。
使用 OTEL Collector
如果您已经有自己的 OpenTelemetry Collector 并希望将跟踪数据导出到 Quickwit,您需要在 config.yaml 中添加一个新的 OTLP gRPC 导出器:
macOS/Windows
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
exporters:
otlp/quickwit:
endpoint: host.docker.internal:7281
tls:
insecure: true
# By default, traces are sent to the otel-traces-v0_7.
# You can customize the index ID By setting this header.
# headers:
# qw-otel-traces-index: otel-traces-v0_7
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/quickwit]
Linux
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
exporters:
otlp/quickwit:
endpoint: 127.0.0.1:7281
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
processors: [batch]
exporters: [otlp/quickwit]
测试您的 OTEL 配置
- 安装 并启动一个 Quickwit 服务器:
./quickwit run
- 使用之前的配置启动一个收集器:
macOS/Windows
docker run -v ${PWD}/otel-collector-config.yaml:/etc/otelcol/config.yaml -p 4317:4317 -p 4318:4318 -p 7281:7281 otel/opentelemetry-collector
Linux
docker run -v ${PWD}/otel-collector-config.yaml:/etc/otelcol/config.yaml --network=host -p 4317:4317 -p 4318:4318 -p 7281:7281 otel/opentelemetry-collector
- 使用 cURL 向收集器发送一个跟踪:
curl -XPOST "http://localhost:4318/v1/traces" -H "Content-Type: application/json" \
--data-binary @- << EOF
{
"resource_spans": [
{
"resource": {
"attributes": [
{
"key": "service.name",
"value": {
"string_value": "test-with-curl"
}
}
]
},
"scope_spans": [
{
"scope": {
"name": "manual-test"
},
"spans": [
{
"time_unix_nano": "1678974011000000000",
"observed_time_unix_nano": "1678974011000000000",
"start_time_unix_nano": "1678974011000000000",
"end_time_unix_nano": "1678974021000000000",
"trace_id": "3c191d03fa8be0653c191d03fa8be065",
"span_id": "3c191d03fa8be065",
"kind": 2,
"events": [],
"status": {
"code": 1
}
}
]
}
]
}
]
}
EOF
您应该会在 Quickwit 服务器上看到类似于以下的日志:
2023-03-16T13:44:09.369Z INFO quickwit_indexing::actors::indexer: new-split split_id="01GVNAKT5TQW0T2QGA245XCMTJ" partition_id=6444214793425557444
这意味着 Quickwit 已经接收到跟踪并创建了一个新的分片。在搜索跟踪之前,请等待分片发布。
使用 OTEL SDK - Python
在本教程中,我们将向您展示如何使用 OpenTelemetry 为 Python Flask 应用程序进行仪器化,并将跟踪数据发送到 Quickwit。本教程受到 Python OpenTelemetry 文档的启发,感谢 OpenTelemetry 团队!
- https://flask.palletsprojects.com/en/2.2.x/
- https://opentelemetry.io/docs/instrumentation/python/getting-started/
前提条件
- 已安装 Python3
- 已安装 Docker
启动一个 Quickwit 实例
安装 Quickwit 并启动一个 Quickwit 实例:
./quickwit run
启动 Jaeger UI
让我们使用 Docker 启动一个 Jaeger UI 实例。在这里我们需要告知 Jaeger 使用 Quickwit 作为其后端。
由于容器网络的一些特殊性,我们将在 MacOS 和 Windows 以及 Linux 上采用不同的方法。
MacOS 和 Windows
我们可以依赖 host.docker.internal 获取指向我们 Quickwit 服务器的 Docker 桥接 IP 地址。
docker run --rm --name jaeger-qw \
-e SPAN_STORAGE_TYPE=grpc-plugin \
-e GRPC_STORAGE_SERVER=host.docker.internal:7281 \
-p 16686:16686 \
jaegertracing/jaeger-query:latest
Linux
默认情况下,Quickwit 监听的是 127.0.0.1,并且不会响应指向 Docker 桥接 (172.17.0.1) 的请求。有多种方法可以解决这个问题。
最简单的方法可能是使用主机网络模式。
docker run --rm --name jaeger-qw --network=host \
-e SPAN_STORAGE_TYPE=grpc-plugin \
-e GRPC_STORAGE_SERVER=127.0.0.1:7281 \
-p 16686:16686 \
jaegertracing/jaeger-query:latest
运行一个简单的 Flask 应用
我们将启动一个 Flask 应用程序,该程序在每个 HTTP 调用 http://localhost:5000/process-ip 上执行三件事:
- 从 https://httpbin.org/ip 获取 IP 地址。
- 解析它,并使用随机休眠进行伪造处理。
- 以随机休眠时间显示它。
我们首先安装依赖项:
pip install flask
pip install opentelemetry-distro
pip install opentelemetry-exporter-otlp
opentelemetry-distro 包会安装 API、SDK 以及您将使用的 opentelemetry-bootstrap 和 opentelemetry-instrument 工具。
以下是我们的应用代码:
import random
import time
import requests
from flask import Flask
app = Flask(__name__)
@app.route("/process-ip")
def process_ip():
body = fetch()
ip = parse(body)
display(ip)
return ip
def fetch():
resp = requests.get('https://httpbin.org/ip')
body = resp.json()
return body
def parse(body):
# Sleep for a random amount of time to make the span more visible.
secs = random.randint(1, 100) / 1000
time.sleep(secs)
return body["origin"]
def display(ip):
# Sleep for a random amount of time to make the span more visible.
secs = random.randint(1, 100) / 1000
time.sleep(secs)
message = f"Your IP address is `{ip}`."
print(message)
if __name__ == "__main__":
app.run(port=5000)
自动 Instrumentation
OpenTelemetry 提供了一个名为 opentelemetry-bootstrap 的工具,它可以自动为您仪器化 Python 应用程序。
opentelemetry-bootstrap -a install
现在一切就绪,我们可以运行应用了:
# We don't need metrics.
OTEL_METRICS_EXPORTER=none \
OTEL_TRACES_EXPORTER=console \
OTEL_SERVICE_NAME=my_app \
python my_app.py
通过访问 http://localhost:5000/process-ip,您应该能在控制台看到相应的跟踪记录。
这已经很好了,但如果我们可以记录每个步骤所花费的时间、获取 HTTP 请求的状态码以及响应的内容类型,那就更好了。让我们通过手动仪器化我们的应用来实现这一点!
手动 Instrumentation
import random
import time
import requests
from flask import Flask
from opentelemetry import trace
# Creates a tracer from the global tracer provider
tracer = trace.get_tracer(__name__)
app = Flask(__name__)
@app.route("/process-ip")
@tracer.start_as_current_span("process_ip")
def process_ip():
body = fetch()
ip = parse(body)
display(ip)
return ip
@tracer.start_as_current_span("fetch")
def fetch():
resp = requests.get('https://httpbin.org/ip')
body = resp.json()
headers = resp.headers
current_span = trace.get_current_span()
current_span.set_attribute("status_code", resp.status_code)
current_span.set_attribute("content_type", headers["Content-Type"])
current_span.set_attribute("content_length", headers["Content-Length"])
return body
@tracer.start_as_current_span("parse")
def parse(body):
# Sleep for a random amount of time to make the span more visible.
secs = random.randint(1, 100) / 1000
time.sleep(secs)
return body["origin"]
@tracer.start_as_current_span("display")
def display(ip):
# Sleep for a random amount of time to make the span more visible.
secs = random.randint(1, 100) / 1000
time.sleep(secs)
message = f"Your IP address is `{ip}`."
print(message)
current_span = trace.get_current_span()
current_span.add_event(message)
if __name__ == "__main__":
app.run(port=5000)
我们现在可以启动新的仪器化应用:
OTEL_METRICS_EXPORTER=none \
OTEL_TRACES_EXPORTER=console \
OTEL_SERVICE_NAME=my_app \
opentelemetry-instrument python my_instrumented_app.py
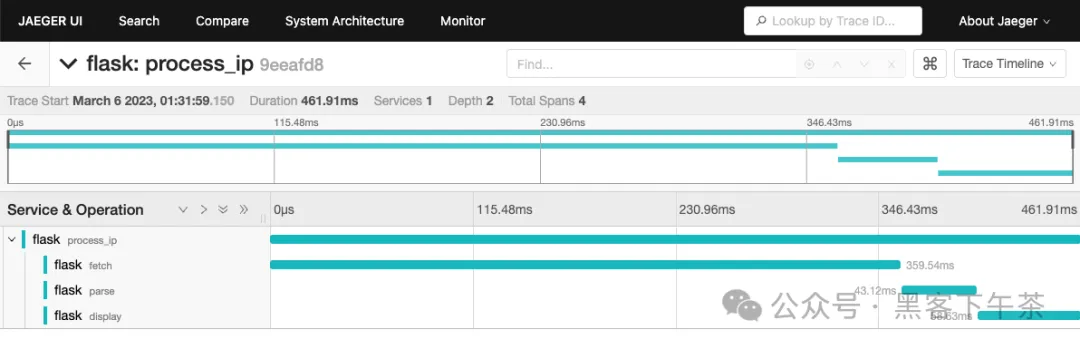
如果您再次访问 http://localhost:5000/process-ip,您应该能看到带有名称 fetch、parse 和 display 的新跨度以及相应的自定义属性!
将跟踪数据发送到 Quickwit
要将跟踪数据发送到 Quickwit,我们需要使用 OTLP 导出器。这非常简单:
OTEL_METRICS_EXPORTER=none \ # We don't need metrics
OTEL_SERVICE_NAME=my_app \
OTEL_EXPORTER_OTLP_TRACES_ENDPOINT=http://localhost:7281 \
opentelemetry-instrument python my_instrumented_app.py
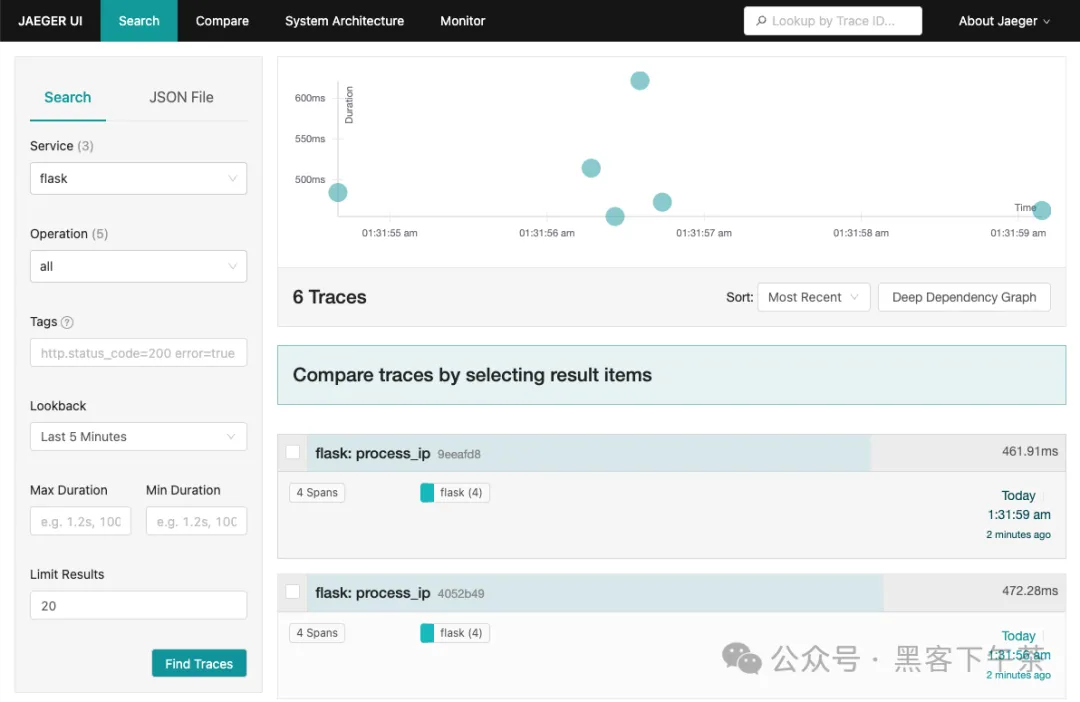
现在,如果您访问 http://localhost:5000/process-ip,跟踪数据将被发送到 Quickwit,只需等待大约 30 秒即可完成索引。是时候休息一下喝杯咖啡了!
30 秒过去了,让我们查询服务的跟踪数据:
curl -XPOST http://localhost:7280/api/v1/otel-trace-v0/search -H 'Content-Type: application/json' -d '{
"query": "resource_attributes.service.name:my_app"
}'
然后打开 Jaeger UI localhost:16686 并进行操作,现在您有了一个由 Quickwit 存储后端支持的 Jaeger UI!
将跟踪数据发送到您的 OpenTelemetry 收集器
按照 OpenTelemetry 收集器教程 中的说明启动一个收集器,并执行以下命令:
OTEL_METRICS_EXPORTER=none \ # We don't need metrics
OTEL_SERVICE_NAME=my_app \
opentelemetry-instrument python instrumented_app.py
跟踪数据将被发送到您的收集器,然后再发送到 Quickwit。
总结
在本教程中,我们学习了如何使用 OpenTelemetry 为 Python 应用程序进行仪器化,并将跟踪数据发送到 Quickwit。同时,我们也了解了如何使用 Jaeger UI 分析这些跟踪数据。
所有的代码片段都可在我们的 教程仓库 中找到。
请告诉我们您对本教程的看法,如有任何疑问,欢迎通过 Discord 或 Twitter 与我们联系。
OTEL service
Quickwit 本地支持 OpenTelemetry 协议 (OTLP),并提供了一个 gRPC 端点来接收来自 OpenTelemetry collector 或直接从应用程序通过 exporter 发送的跨度数据。此端点默认是启用的。
当启用时,Quickwit 将启动 gRPC 服务,准备接收来自 OpenTelemetry collector 的跨度数据。这些跨度数据默认会被索引到 otel-trace-v0_7 索引中,并且如果该索引不存在,它将自动创建。索引文档映射在下一个section中描述。
如果由于任何原因,您想要禁用这个端点,您可以:
- 在启动 Quickwit 时将环境变量
QW_ENABLE_OTLP_ENDPOINT设置为false。 - 或者配置节点配置,将索引器设置
enable_otlp_endpoint设置为false。
# ... Indexer configuration ...
indexer:
enable_otlp_endpoint: false
在您选择的索引中发送跨度
您可以通过将 gRPC 请求的头部 qw-otel-traces-index 设置为目标索引 ID 来在您选择的索引中发送跨度。
跟踪和跨度数据模型
一个跟踪是一组跨度,表示一个单独的请求。一个跨度表示跟踪内的单个操作。OpenTelemetry 收集器发送跨度,Quickwit 默认将它们索引到 otel-trace-v0_7 索引中,该索引将 OpenTelemetry 的跨度模型映射到 Quickwit 中的索引文档。
跨度模型源自 OpenTelemetry 规范。
下面是 otel-trace-v0_7 索引的文档映射:
version: 0.7
index_id: otel-trace-v0_7
doc_mapping:
mode: strict
field_mappings:
- name: trace_id
type: bytes
input_format: hex
output_format: hex
fast: true
- name: trace_state
type: text
indexed: false
- name: service_name
type: text
tokenizer: raw
fast: true
- name: resource_attributes
type: json
tokenizer: raw
- name: resource_dropped_attributes_count
type: u64
indexed: false
- name: scope_name
type: text
indexed: false
- name: scope_version
type: text
indexed: false
- name: scope_attributes
type: json
indexed: false
- name: scope_dropped_attributes_count
type: u64
indexed: false
- name: span_id
type: bytes
input_format: hex
output_format: hex
- name: span_kind
type: u64
- name: span_name
type: text
tokenizer: raw
fast: true
- name: span_fingerprint
type: text
tokenizer: raw
- name: span_start_timestamp_nanos
type: datetime
input_formats: [unix_timestamp]
output_format: unix_timestamp_nanos
indexed: false
fast: true
fast_precision: milliseconds
- name: span_end_timestamp_nanos
type: datetime
input_formats: [unix_timestamp]
output_format: unix_timestamp_nanos
indexed: false
fast: false
- name: span_duration_millis
type: u64
indexed: false
fast: true
- name: span_attributes
type: json
tokenizer: raw
fast: true
- name: span_dropped_attributes_count
type: u64
indexed: false
- name: span_dropped_events_count
type: u64
indexed: false
- name: span_dropped_links_count
type: u64
indexed: false
- name: span_status
type: json
indexed: true
- name: parent_span_id
type: bytes
input_format: hex
output_format: hex
indexed: false
- name: events
type: array<json>
tokenizer: raw
fast: true
- name: event_names
type: array<text>
tokenizer: default
record: position
stored: false
- name: links
type: array<json>
tokenizer: raw
timestamp_field: span_start_timestamp_nanos
indexing_settings:
commit_timeout_secs: 10
search_settings:
default_search_fields: []
更多
1. Binance 如何使用 Quickwit 构建 100PB 日志服务(Quickwit 博客)
折腾 Quickwit,Rust 编写的分布式搜索引擎 - 可观测性之分布式追踪的更多相关文章
- 【分布式搜索引擎】Elasticsearch分布式架构原理
一.相关概念介绍 1)集群(cluster) 一个集群(cluster)由一个或多个节点组成. 这些节点具有相同的cluster.name,它们协同工作,分享数据和负载.当加入新的节点或者删除一个节点 ...
- ElasticSearch分布式搜索引擎——从入门到精通
ES分布式搜索引擎 注意: 在没有创建库的时候搜索,ES会创建一个库并自动创建该字段并且设置为String类型也就是text 什么是elasticsearch? 一个开源的分布式搜索引擎,可以用来实现 ...
- 最强分布式搜索引擎——ElasticSearch
最强分布式搜索引擎--ElasticSearch 本篇我们将会介绍到一种特殊的类似数据库存储机制的搜索引擎工具--ES elasticsearch是一款非常强大的开源搜索引擎,具备非常多强大功能,可以 ...
- 转载自lanceyan: 一致性hash和solr千万级数据分布式搜索引擎中的应用
一致性hash和solr千万级数据分布式搜索引擎中的应用 互联网创业中大部分人都是草根创业,这个时候没有强劲的服务器,也没有钱去买很昂贵的海量数据库.在这样严峻的条件下,一批又一批的创业者从创业中获得 ...
- bloom-server 基于 rust 编写的 rest api cache 中间件
bloom-server 基于 rust 编写的 rest api cache 中间件,他位于lb 与api worker 之间,使用redis 作为缓存内容存储, 我们需要做的就是配置proxy,同 ...
- 分布式搜索引擎Elasticsearch在CentOS7中的安装
1. 概述 随着企业业务量的不断增大,业务数据随之增加,传统的基于关系型数据库的搜索已经不能满足需要. 在关系型数据库中搜索,只能支持简单的关键字搜索,做不到分词和统计的功能,而且当单表数据量到达上百 ...
- 分布式进阶(十八) 分布式缓存之Memcached
分布式缓存 分布式缓存出于如下考虑:首先是缓存本身的水平线性扩展问题,其次是缓存大并发下本身的性能问题,再次避免缓存的单点故障问题(多副本和副本一致性). 分布式缓存的核心技术包括首先是内存本身的管理 ...
- 分布式全局ID与分布式事务
1. 概述 老话说的好:人不可貌相,海水不可斗量.以貌取人是非常不好的,我们要平等的对待每一个人. 言归正传,今天我们来聊一下分布式全局 ID 与分布式事务. 2. 分布式全局ID 2.1 分布式数据 ...
- 分布式接口幂等性、分布式限流:Guava 、nginx和lua限流
接口幂等性就是用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用. 举个最简单的例子,那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常,此 ...
- 云时代的分布式数据库:阿里分布式数据库服务DRDS
发表于2015-07-15 21:47| 10943次阅读| 来源<程序员>杂志| 27 条评论| 作者王晶昱 <程序员>杂志数据库DRDS分布式沈询 摘要:伴随着系统性能.成 ...
随机推荐
- T3/A40i支持Linux-5.10新内核啦,Docker、Qt、Python统统升级!
自2021年创龙科技推出全志国产化率100%的T3/A40i工业核心板后,不到两年时间已超过800家工业客户选择创龙科技T3/A40i平台.随着客户产品的不断升级与迭代,部分"能源电力&qu ...
- IDEA 设置自动去掉不用的import
- Java Objects工具类重点方法使用
Objects工具类 jdk 1.7引进的工具类,都是静态调用的方法,jdk 1.8新增了部分方法 重点方法 equals 用于字符串和包装对象的比较,先比较内存地址,再比较值 deepEquals ...
- 使用了条件三元运算符来判断 this.temp.id 是否存在且 mt_qty 是否已被赋值
mt_qty: (this.temp.id && this.temp.mt_qty) ? this.temp.mt_qty : event.wo_wip,在这个修正后的代码中,使用了条 ...
- 蓝图中如何存储树结构: NPC对话的打开方式
BFS来扩展成数组, 然后每一个node节点的child存储为索引.
- openGL之多线程渲染
随着Vulkan的引入,我们的图形技术的发展到达了一个新的顶点,但是呢,我们的老干爹OpenGL作为落日余晖,他在一些Vulkan才有的新功能上,也提供了一些支持,现在我们来讨论一下OpenGL之多线 ...
- 入门Vue+.NET 8 Web Api记录(一)
做自己感觉有意思的或者能解决自己需求的项目作为入门,我觉得是有帮助的,不会觉得那么无聊. 一个最简单的前后端分离项目应该是怎么样的? 我觉得就是前端有个按钮,点击向后端发送一个get请求,获取到数据后 ...
- layui下拉框的数据如何直接从数据库提取(动态赋值)
代码说明部分 第一步:先把layui官方给的模板粘到自己的前端注:下面的代码是我直接从layui官网粘过来的 <div class="layui-form-item"> ...
- 对比python学julia(第四章:人工智能)--(第三节)目标检测
1.1. 项目简介 目标检测(Object Detection)的任务是在图像中找出检测对象的位置和犬小,是计算机视觉领域的核心问题之一,在自动驾驶.机器人和无人机等许多领域极具研究价值. 随着深度 ...
- 【DataBase】MySQL 06 条件查询 & 排序查询
视频参考自:P28 - P42 https://www.bilibili.com/video/BV1xW411u7ax 条件查询概述 # 进阶2 条件查询 -- 语法:SELECT 查询列表 FROM ...