浅析Jvm
浅析Jvm
基本概念
引言
Java 虚拟机(JVM,Java Virtual Machine)是 Java 生态系统的核心组成部分,它为 Java 应用程序提供了一个运行环境。JVM 的主要职责是将 Java 字节码(Bytecode)转换为机器码,并执行这些机器码,从而实现 Java 的“写一次,运行到处”的跨平台特性。
JVM 的基本架构
JVM 的架构可以分为五个主要部分:类加载子系统(Class Loader Subsystem)、运行时数据区(Runtime Data Area)、执行引擎(Execution Engine)、本地接口(Native Interface)和垃圾回收(Garbage Collection)。
1. 类加载子系统(Class Loader Subsystem)
类加载子系统负责将 Java 类从文件系统或网络中加载到 JVM 中。类加载过程包括以下三个步骤:
- 加载:找到并加载类的二进制数据。
- 链接:验证、准备和解析类。
- 验证:确保类文件的字节码符合 JVM 规范。
- 准备:为类的静态变量分配内存,并将其初始化为默认值。
- 解析:将类的符号引用转换为直接引用。
- 初始化:执行类的静态初始化块和静态变量的赋值操作。
2. 运行时数据区(Runtime Data Area)
运行时数据区是 JVM 在执行 Java 程序时使用的内存区域,它可以进一步细分为以下几个区域:
- 方法区(Method Area):存储已加载类的元数据、常量池、静态变量和JIT编译后的代码。从 Java 8 开始,方法区被移到本地内存中的元空间(Metaspace)中。
- 堆(Heap):所有对象实例和数组在这里分配内存。堆是垃圾回收(GC)的主要区域。
- 栈(Stack):每个线程都有自己的栈,存储局部变量、操作数栈和帧数据。栈中的数据是线程私有的。
- 程序计数器(Program Counter Register):一个小的内存区域,保存当前线程所执行的字节码指令的地址。
- 本地方法栈(Native Method Stack):为本地方法(由Native关键字修饰的方法)执行提供栈空间。
3. 执行引擎(Execution Engine)
执行引擎负责执行字节码。它包括以下几个部分:
- 解释器(Interpreter):将字节码逐条解释执行。解释执行速度较慢,但启动快。
- 即时编译器(Just-In-Time Compiler, JIT):将热点代码编译为机器码,以提高执行速度。编译后的代码直接在CPU上运行。
- 垃圾回收器(Garbage Collector):自动管理内存,通过标记和清除、复制和压缩等算法回收不再使用的对象。
4. 本地接口(Native Interface)
本地接口允许 JVM 调用本地库(如 C 或 C++ 编写的库)。通过 JNI(Java Native Interface),Java 程序可以与本地代码进行交互。
垃圾回收(Garbage Collection)
垃圾回收是 JVM 的一个重要特性,用于自动管理内存。JVM 的垃圾回收器会定期扫描堆中的对象,回收不再使用的对象内存。
所谓垃圾回收机制(Garbage Collection, 简称GC),指自动管理动态分配的内存空间的机制,自动回收不再使用的内存,不定时去堆内存中清理不可达对象,以避免内存泄漏和内存溢出的问题。最早是在1960年代提出的。
垃圾回收是 java相较于c、c++语言的优势之一。其他编程语言,如C#、Python和Ruby等,也都提供了垃圾回收机制。不可达的对象并不会马上就会直接回收, 垃圾收集器在一个Java程序中的执行是自动的,不能强制执行,程序员唯一能做的就是通过调用System.gc 方法来建议执行垃圾收集器,但其是否可以执行,什么时候执行却都是不可知的。
这也是垃圾收集器的最主要的缺点。
常见的垃圾回收算法有:
- 标记-清除算法(Mark-Sweep):标记活动对象,然后清除未标记对象。
- 标记-复制算法(Mark-Compact):标记活动对象,然后将其复制到新空间,压缩内存。
- 分代收集算法(Generational GC):将堆分为年轻代(Young Generation)和老年代(Old Generation),分别使用不同的回收算法优化性能。
一次完整的垃圾回收过程是什么样的?
Jvm 垃圾回收的基本过程可以分为以下三个步骤:
- 垃圾分类:首先我们的 jvm 在进行垃圾回收的过程,需要确定哪些对象是垃圾对象,哪些对象是存活对象。这个类似于我们在做一件事之前的规划。具体的分类方法一般情况下,垃圾回收器会从堆的根节点(如程序计数器、虚拟机栈、本地方法栈和方法区中的类静态属性等),也就是 gc root。开始遍历对象图,标记所有可以到达的对象为存活对象,未被标记的对象则被认为是垃圾对象。进过标记后,分类成功。
- 垃圾查找:分类后,已经知道了对象所处的一个状态,jvm 会根据分类后对象,先找出所有垃圾对象,以便进行清理。不同的垃圾收集,其中的查找方式会产生相应的差异,随着现在 jdk 的 升级与发展,还会产生更加高效的算法,后面会有垃圾收集的算法详细介绍。
- 垃圾清除:标记完成后,进行最后的清理与删除。这里涉及不同的垃圾收集器,清理的方式也不同,常见的有:标记清除法、复制算法等;需要注意的是,垃圾清理可能会引起应用程序的暂停,不同的垃圾回收器通过不同的方式来减少这种暂停时间,从而提高应用程序的性能和可靠性。这也是垃圾收集器不断发展的一个重要命题。
如何判断对象是否可以被回收?
引用计数法
引用计数法(Reference Counting)是一种内存管理技术,用于跟踪对象的引用数量。每个对象都有一个引用计数器,记录着指向该对象的引用数量。
当一个对象被引用时,引用计数器加一;当一个引用被释放时,引用计数器减一。当引用计数器为零时,表示没有任何引用指向该对象,该对象可以被释放,回收其占用的内存。
可达性分析算法
可达性分析算法是JVM垃圾回收中的一种算法,它通过分析对象的引用关系,判断对象是否可达,从而决定对象是否可以被回收。
工作原理
- GC Roots:在Java中,GC Roots通常包括虚拟机栈(栈帧中的本地变量表)中引用的对象、方法区(静态变量)中引用的对象、本地方法栈中JNI(Native方法)引用的对象等。
- 搜索过程:可达性分析算法从GC Roots开始,递归地访问所有可达的对象,并给它们打上标记。这个过程可以使用深度优先搜索(DFS)或广度优先搜索(BFS)等图遍历算法来实现。
- 回收判定:如果一个对象到GC Roots没有任何引用链相连(即该对象从GC Roots不可达),则证明该对象是不可用的,可以判定为可回收对象。
大概流程
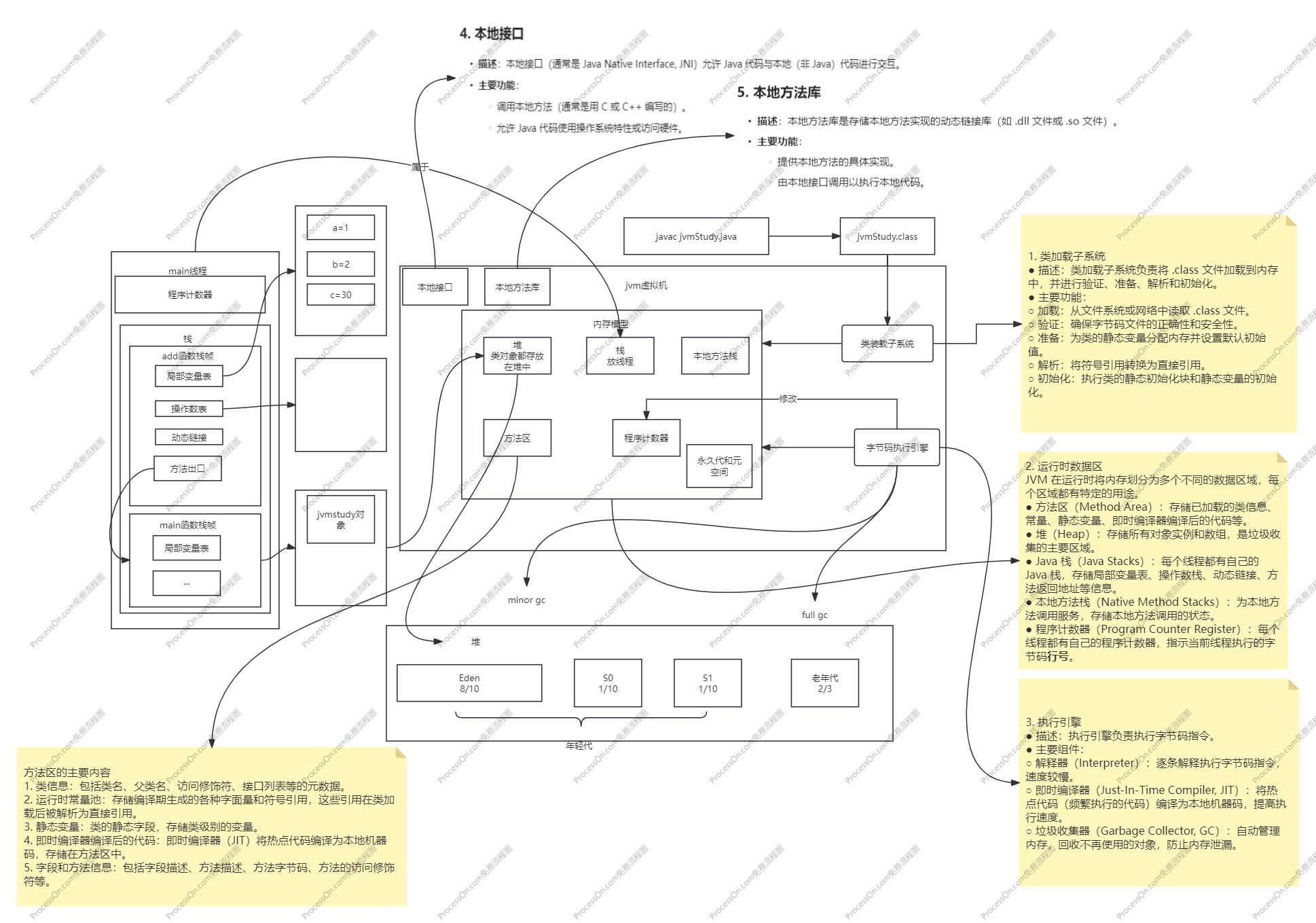
我用下面的代码作为学习的例子
package cmk.study.jvm;
public class jvmStudy {
static int add(){
int a = 1;
int b = 2;
int c = (a + b)*10;
return c;
}
public static void main(String[] args) throws InterruptedException {
jvmStudy jvmStudy = new jvmStudy();
int add1 = jvmStudy.add();
System.out.println(add1);
}
}
我们反编译这个class类 javap -c jvmStudy.class > jvmStudy.txt
// 编译自 "jvmStudy.java"
public class cmk.study.jvm.jvmStudy {
// 默认构造方法
public cmk.study.jvm.jvmStudy();
Code:
0: aload_0 // 将this引用推送到操作数栈顶
1: invokespecial #1 // 调用父类java/lang/Object的构造方法
4: return // 从构造方法返回
// 静态方法 add,返回一个 int
static int add();
Code:
0: iconst_1 // 将常量1推送到操作数栈顶
1: istore_0 // 将栈顶的1存储到局部变量0
2: iconst_2 // 将常量2推送到操作数栈顶
3: istore_1 // 将栈顶的2存储到局部变量1
4: iload_0 // 将局部变量0的值(即1)加载到操作数栈顶
5: iload_1 // 将局部变量1的值(即2)加载到操作数栈顶
6: iadd // 将栈顶两值相加(1 + 2),结果3推送到操作数栈顶
7: bipush 10 // 将常量10推送到操作数栈顶
9: imul // 将栈顶两值相乘(3 * 10),结果30推送到操作数栈顶
10: istore_2 // 将栈顶的30存储到局部变量2
11: iload_2 // 将局部变量2的值(即30)加载到操作数栈顶
12: ireturn // 返回栈顶的int值,即30
// 主方法
public static void main(java.lang.String[]);
Code:
0: new #7 // class cmk/study/jvm/jvmStudy
// 创建一个新的jvmStudy对象
3: dup // 复制栈顶的对象引用
4: invokespecial #9 // Method "<init>":()V
// 调用构造方法初始化新创建的jvmStudy对象
7: astore_1 // 将对象引用存储到局部变量1
8: aload_1 // 加载局部变量1的对象引用到栈顶
9: pop // 弹出栈顶的对象引用,实际上这里是无用操作
10: invokestatic #10 // Method add:()I
// 调用静态方法add并将返回值推送到操作数栈顶
13: istore_2 // 将add方法的返回值(即30)存储到局部变量2
14: getstatic #14 // Field java/lang/System.out:Ljava/io/PrintStream;
// 获取System.out静态字段(标准输出流)
17: iload_2 // 将局部变量2的值(即30)加载到操作数栈顶
18: invokevirtual #20 // Method java/io/PrintStream.println:(I)V
// 调用PrintStream的println方法,打印int值
21: return // 从main方法返回
}
反编译结果可以清楚的看到程序的执行逻辑,可以与上图做对应。
浅析Jvm的更多相关文章
- 浅析JVM内存区域及垃圾回收
一.JVM简介 JVM,全称Java Virtual Machine,即Java虚拟机.以Java作为编程语言所编写的应用程序都是运行在JVM上的.JVM是一种用于计算设备的规范,它是一个虚构出来的计 ...
- 浅析JVM内存结构和6大区域(转)举例非常好
内存作为系统中重要的资源,对于系统稳定运行和高效运行起到了关键的作用,Java和C之类的语言不同,不需要开发人员来分配内存和回收内存,而是由JVM来管理对象内存的分配以及对象内存的回收(又称为垃圾回收 ...
- 浅析JVM中的GC日志
目录 一.GC日志的格式分析 二.运行时开启GC日志 一.GC日志的格式分析 在讲述GC日志之前,我们先来运行下面这段代码 package com.example; public class Test ...
- 浅析JVM内存结构和6大区域(转)
其实对于我们一般理解的计算机内存,它算是CPU与计算机打交道最频繁的区域,所有数据都是先经过硬盘至内存,然后由CPU再从内存中获取数据进行处理,又将数据保存到内存,通过分页或分片技术将内存中的数据再f ...
- 程序员从宏观、微观角度浅析JVM虚拟机!
1.问题 1.JAVA文本文件如何被翻译成CLASS二进制文件? 2.如何理解CLASS文件的组成结构? 3.虚拟机如何加载使用类文件的生命周期? 4.虚拟机系列诊断工具如何使用? 5.虚拟机内存淘汰 ...
- Java编程技术之浅析JVM内存
JVM JVM->Java Virtual Machine:Java虚拟机,是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的. 基本认知: ...
- JVM虚拟机—JVM内存
JVM在运行时将数据划分为了5个区域来存储,这5个区域图示如下: 其中方法区和堆对是所有线程共享的内存区域:而java栈.本地方法栈和程序员计数器是运行时线程私有的内存区域. 首先我们熟悉一下一个 J ...
- Android性能调优篇之探索JVM内存分配
开篇废话 今天我们一起来学习JVM的内存分配,主要目的是为我们Android内存优化打下基础. 一直在想以什么样的方式来呈现这个知识点才能让我们易于理解,最终决定使用方法为:图解+源代码分析. 欢迎访 ...
- Java 10大精华文章收集001
Java语言与JVM中的Lambda表达式全解 Lambda表达式是自Java SE 5引入泛型以来最重大的Java语言新特性,本文是2012年度最后一期Java Magazine中的一篇文章,它介绍 ...
- Android内存优化1 了解java内存分配 1
开篇废话 今天我们一起来学习JVM的内存分配,主要目的是为我们Android内存优化打下基础. 一直在想以什么样的方式来呈现这个知识点才能让我们易于理解,最终决定使用方法为:图解+源代码分析. 欢迎访 ...
随机推荐
- Jax框架的jit编译是否可以使用循环结构,如果使用循环结构需要注意什么(续)
前文: Jax框架的jit编译是否可以使用循环结构,如果使用循环结构需要注意什么 从前文我们知道,jax的jit中尽可能的不要放入循环结构,因为在jit编译时会将循环结构暂开,因而会消耗掉大量的时间进 ...
- 《Bitcoin: A Peer-to-Peer Electronic Cash System》 中本聪写的比特币白皮书
网址: https://bitcoin.org/bitcoin.pdf =============================================================
- aarch64/arm_v8 环境下编译Arcade-Learning-Environment —— ale-py —— gym[atari]的安装
aarch64架构下不支持gym[atari]安装,因此我们只能在该环境下安装gym,对于atari环境的支持则需要源码上重新编译,也就是本文给出的下面的方法: 源码下载: https://githu ...
- 关于没使用Mybatis 分页,分页sql默认执行count(0) 的问题
之前的Impl 的方法 :selectFromList(String uid, Integer pageNum, Integer pageSize) 之后的Impl 的方法 :selectFromLi ...
- 9组-Beta冲刺-总结
一.基本情况 组长博客链接:9组-Beta冲刺-总结 现场答辩总结:本次答辩,我们演示了我们到Beta冲刺周结束时的成果展示,离目标还有一些距离,不过本次答辩完成了任务,总体来说还不错,希望下次最终答 ...
- games101 作业6 详解SAH
games101 作业6 详解SAH 可参考资料:https://www.pbr-book.org/3ed-2018/Primitives_and_Intersection_Acceleration/ ...
- 2023 CCPC 桂林题解
gym H. Sweet Sugar 一个经典贪心是从下到上,如果子树 \(u\) 剩下的部分(一定包含 \(u\))包含合法连通块,那么这个连通块给答案贡献 \(1\),切断 \(u\) 与 \(f ...
- C++ 项目目录结构
目录结构 project_root/ ├── bin/ # 可执行文件目录 │ ├── my_app # 可执行文件 │ └── ... # 其他可执行文件或脚本 │ ├── build/ # 编译产 ...
- 使用 crontab 设置 Homebrew 自动更新
本人有强迫症,希望自己电脑上安装的软件永远是最新的.App Store 有自动更新功能,然而 Homebrew 则没有自动更新的选项.每次手动更新的话时间长了又感觉麻烦.后来发现可以使用 cronta ...
- 编译器实现之旅——第十三章 if语句和while语句的代码生成器分派函数的实现
在上一章的旅程中,我们已经实现了表达式类代码生成器分派函数,而在这一章的旅程中,我们将要实现if语句和while语句的代码生成器分派函数.if语句和while语句是两种典型的带有跳转指令的语句.观察C ...