Python基础——字符编码、文件处理
文章目录
字符编码
一 引入
字符串类型、文本文件的内容都是由字符组成的,但凡涉及到字符的存取,都需要考虑字符编码的问题。
字符编码这个知识点的典型特征就是理论多、结论少,但对于开发而言只需要记住结论即可,下面让我们来一点点介绍它
二 知识储备
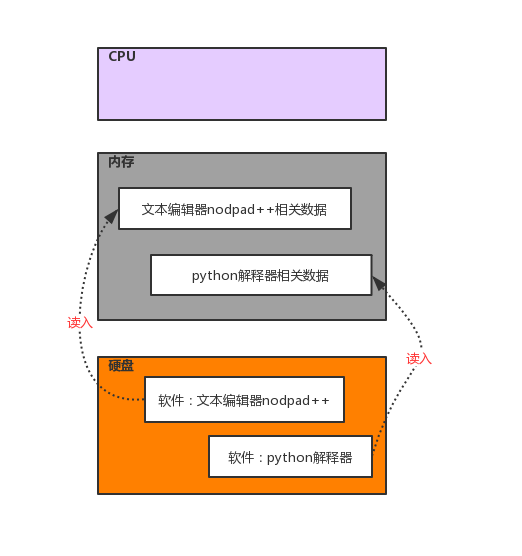
2.1 三大核心硬件
所有软件都是运行硬件之上的,与运行软件相关的三大核心硬件为cpu、内存、硬盘,我们需要明确三点
#1、软件运行前,软件的代码及其相关数据都是存放于硬盘中的
#2、任何软件的启动都是将数据从硬盘中读入内存,然后cpu从内存中取出指令并执行
#3、软件运行过程中产生的数据最先都是存放于内存中的,若想永久保存软件产生的数据,则需要将数据由内存写入硬盘
2.2 文本编辑器读取文件内容的流程
#阶段1、启动一个文件编辑器(文本编辑器如nodepad++,pycharm,word)
#阶段2、文件编辑器会将文件内容从硬盘读入内存
#阶段3、文本编辑器会将刚刚读入内存中的内容显示到屏幕上
2.3 python解释器执行文件的流程
以python test.py为例,执行流程如下
- 阶段1、启动python解释器,此时就相当于启动了一个文本编辑器
- 阶段2、python解释器相当于文本编辑器,从硬盘上将test.py的内容读入到内存中
- 阶段3、python解释器解释执行刚刚读入的内存的内容,开始识别python语法
2.4 总结
python解释器与文件本编辑的异同如下
1、相同点:前两个阶段二者完全一致,都是将硬盘中文件的内容读入内存,详解如下
python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
2、不同点:在阶段3时,针对内存中读入的内容处理方式不同,详解如下
文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法)
三、字符编码介绍
3.1 什么是字符编码?
人类在与计算机交互时,用的都是人类能读懂的字符,如中文字符、英文字符、日文字符等
而计算机只能识别二进制数,详解如下
二进制数即由0和1组成的数字,例如010010101010。计算机是基于电工作的,电的特性即高低电平,人类从逻辑层面将高电平对应为数字1,低电平对应为数字0,这直接决定了计算机可以识别的是由0和1组成的数字
毫无疑问,由人类的字符到计算机中的数字,必须经历一个过程,如下
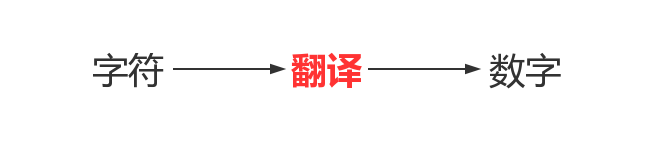
翻译的过程必须参照一个特定的标准,该标准称之为字符编码表,该表上存放的就是字符与数字一一对应的关系。
字符编码中的编码指的是翻译或者转换的意思,即将人能理解的字符翻译成计算机能识别的数字
3.2 字符编码表的发展史 (了解)
字符编码的发展经历了三个重要的阶段,如下
3.2.1 阶段一:一家独大
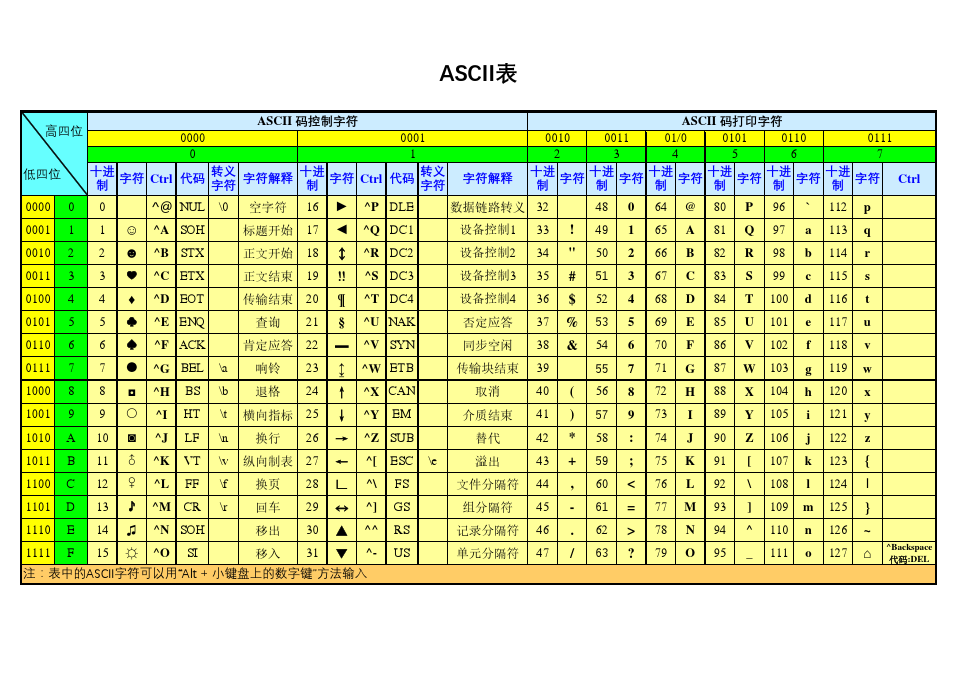
现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表
# ASCII表的特点:
1、只有英文字符与数字的一一对应关系
2、一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
3.2.2 阶段二:诸侯割据、天下大乱
为了让计算机能够识别中文和英文,中国人定制了GBK
# GBK表的特点:
1、只有中文字符、英文字符与数字的一一对应关系
2、一个英文字符对应1Bytes
一个中文字符对应2Bytes
补充说明:
1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
每个国家都各自的字符,为让计算机能够识别自己国家的字符外加英文字符,各个国家都制定了自己的字符编码表
# Shift_JIS表的特点:
1、只有日文字符、英文字符与数字的一一对应关系
# Euc-kr表的特点:
1、只有韩文字符、英文字符与数字的一一对应关系
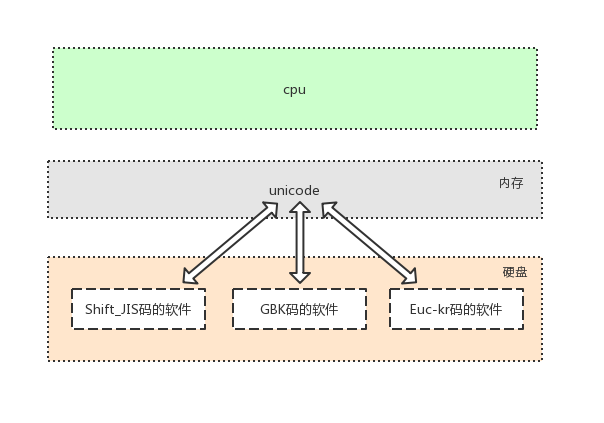
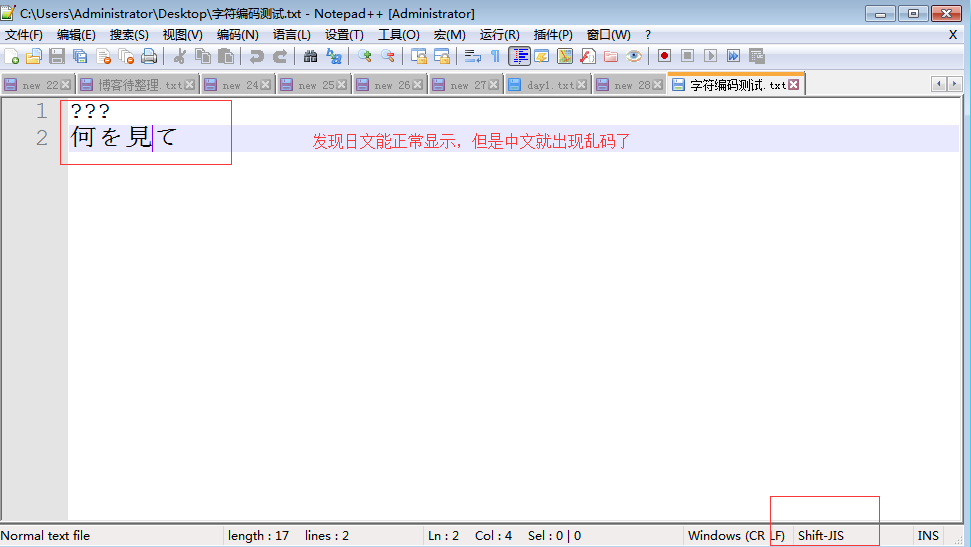
此时,美国人用的计算机里使用字符编码标准是ASCII、中国人用的计算机里使用字符编码标准是GBK、日本人用的计算机里使用字符编码标准是Shift_JIS,如下图所示,
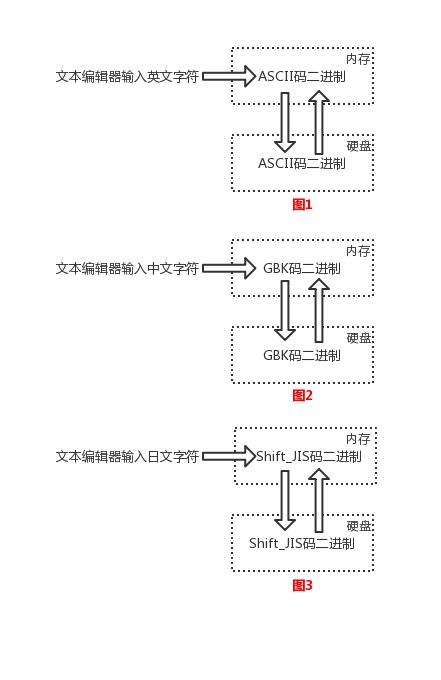
字符编码发展到了这个阶段,可以用一句话概括:诸侯割据、天下大乱,详解如下
图1中,文本编辑存取文件的原理如下
文本文件内容全都为字符,无论存取都是涉及到字符编码问题
#1、存文本文件
人类通过文本编辑器输入的字符会被转化成ASCII格式的二进制存放于内存中,如果需要永久保存,则直接将内存中的ASCII格式的二进制写入硬盘
#2、读文本文件
直接将硬盘中的ASCII格式的二进制读入内存,然后通过ASCII表反解成英文字符
图2图3都是相同的过程,此时无论是存还是取由于采用的字符编码表一样,所以肯定不会出现乱码问题,但问题是在美国人用的计算机里只能输入英文字符,而在中国人用的计算机里只能输入中文字符和英文字符…,毫无疑问我们希望计算机允许我们输入万国字符均可识别、不乱码,而现阶段计算机采用的字符编码ASCII、GBK、Shift_JIS都无法识别万国字符,所以我们必须定制一个兼容万国字符的编码表,请看阶段三
3.2.3 阶段三:分久必合
unicode于1990年开始研发,1994年正式公布,具备两大特点:
#1. 存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符
#2. 与传统的字符编码的二进制数都有对应关系,详解如下
很多地方或老的系统、应用软件仍会采用各种各样传统的编码,这是历史遗留问题。此处需要强调:软件是存放于硬盘的,而运行软件是要将软件加载到内存的,面对硬盘中存放的各种传统编码的软件,想让我们的计算机能够将它们全都正常运行而不出现乱码,内存中必须有一种兼容万国的编码,并且该编码需要与其他编码有相对应的映射/转换关系,这就是unicode的第二大特点产生的缘由
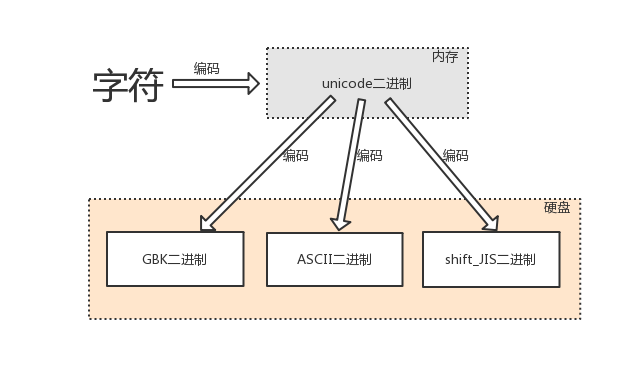
文本编辑器输入任何字符都是最新存在于内存中,是unicode编码的,存放于硬盘中,则可以转换成任意其他编码,只要该编码可以支持相应的字符
# 英文字符可以被ASCII识别
英文字符--->unciode格式的数字--->ASCII格式的数字
# 中文字符、英文字符可以被GBK识别
中文字符、英文字符--->unicode格式的数字--->gbk格式的数字
# 日文字符、英文字符可以被shift-JIS识别
日文字符、英文字符--->unicode格式的数字--->shift-JIS格式的数字
3.3 编码与解码
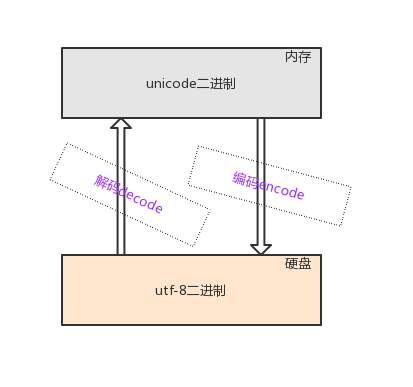
由字符转换成内存中的unicode,以及由unicode转换成其他编码的过程,都称为编码encode
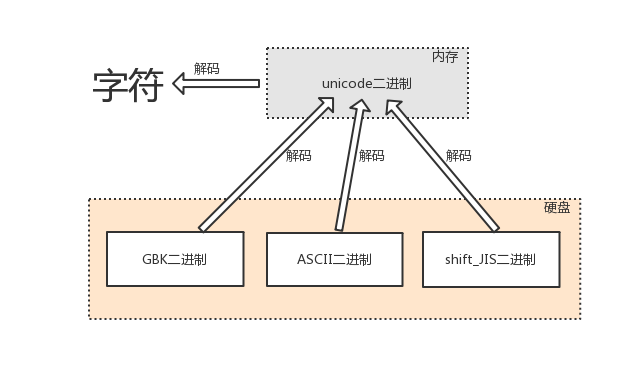
由内存中的unicode转换成字符,以及由其他编码转换成unicode的过程,都称为解码decode
在诸多文件类型中,只有文本文件的内存是由字符组成的,因而文本文件的存取也涉及到字符编码的问题
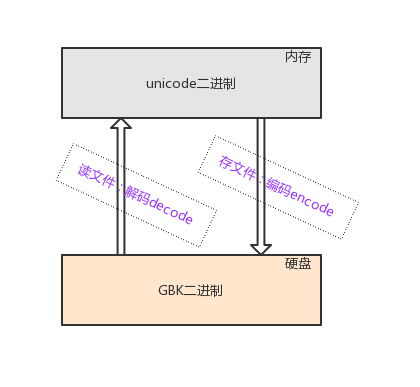
3.4 utf-8的由来
注意:如果保存到硬盘的是GBK格式二进制,当初用户输入的字符只能是中文或英文,同理如果保存到硬盘的是Shift_JIS格式二进制,当初用户输入的字符只能是日文或英文……如果我们输入的字符中包含多国字符,那么该如何处理?
多国字符—√—》内存(unicode格式的二进制)——X—》硬盘(GBK格式的二进制)
多国字符—√—》内存(unicode格式的二进制)——X—》硬盘(Shift_JIS格式的二进制)
多国字符—√—》内存(unicode格式的二进制)——√—》硬盘(???格式的二进制)
理论上是可以将内存中unicode格式的二进制直接存放于硬盘中的,但由于unicode固定使用两个字节来存储一个字符,如果多国字符中包含大量的英文字符时,使用unicode格式存放会额外占用一倍空间(英文字符其实只需要用一个字节存放即可),然而空间占用并不是最致命的问题,最致命地是当我们由内存写入硬盘时会额外耗费一倍的时间,所以将内存中的unicode二进制写入硬盘或者基于网络传输时必须将其转换成一种精简的格式,这种格式即utf-8(全称Unicode Transformation Format,即unicode的转换格式)
多国字符—√—》内存(unicode格式的二进制)——√—》硬盘(utf-8格式的二进制)
那为何在内存中不直接使用utf-8呢?
utf-8是不定长的:一个英文字符占1Bytes,一个中文字符占3Bytes,生僻字用更多的Bytes存储。
也就意味着如果用户输入的字符是:你y好,在内存中需要先经历计算的过程:“你”应该用3Bytes,“y”应该用1Bytes,“好”应该用3Bytes,然后才能存储,所以内存中如果直接使用utf-8格式去存储字符,耗费的总时间=计算时间+存储时间,而内存中使用定长的unicode格式存储字符,就省去了计算时间,所以内存中使用unicode来存储字符会浪费空间,但是会提升速度,这是一种用空间换时间的方法
四 字符编码的应用
我们学习字符编码就是为了存取字符时不发生乱码问题:
1、内存中固定使用unicode无论输入任何字符都不会发生乱码
2、我们能够修改的是存/取硬盘的编码方式,如果编码设置不正确将会出现乱码问题。乱码问题分为两种:存乱了,读乱了
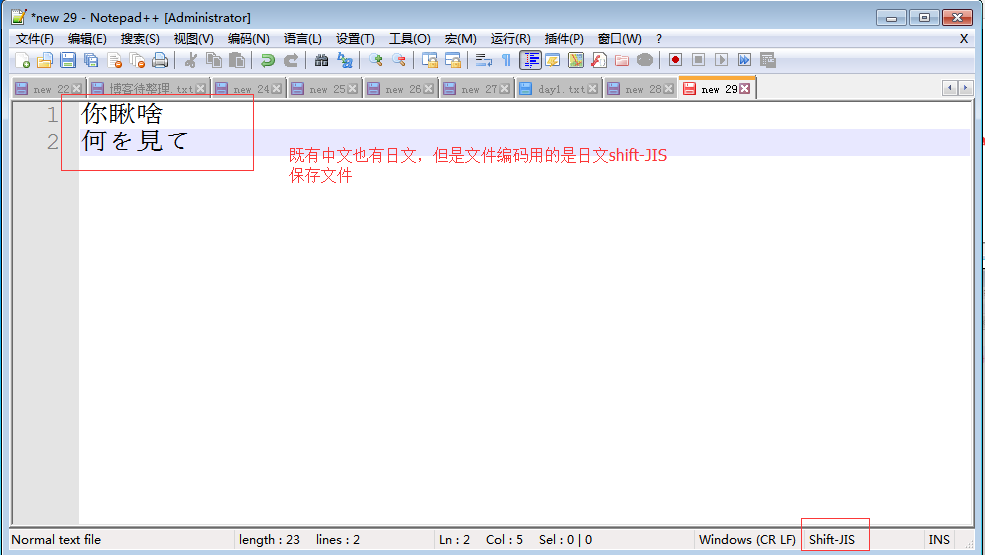
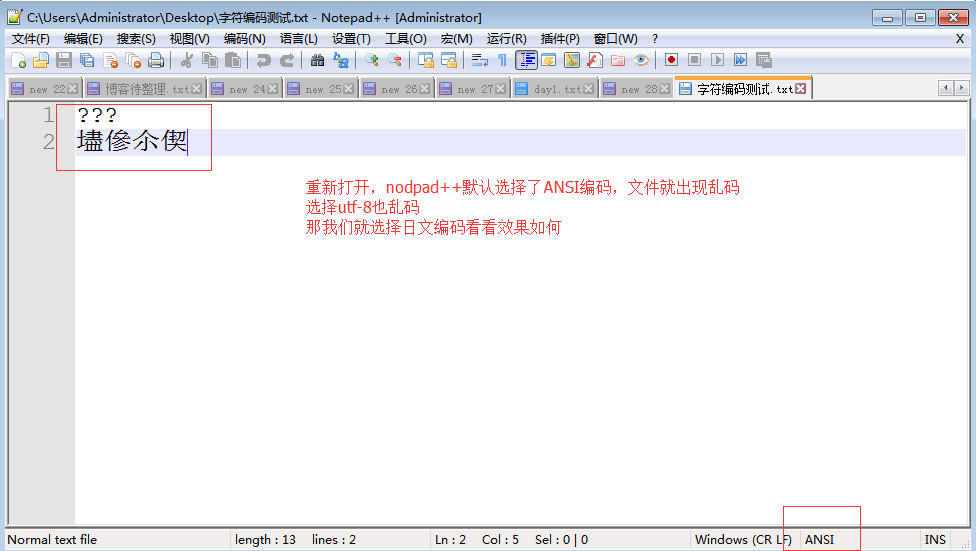
- 2.1 存乱了:如果用户输入的内容中包含中文和日文字符,如果单纯以shift_JIS存,日文可以正常写入硬盘,而由于中文字符在shift_jis中没有找到对应关系而导致存乱了
- 2.2 读乱了:如果硬盘中的数据是shift_JIS格式存储的,采GBK格式读入内存就读乱了
总结:
- 保证存的时候不乱:在由内存写入硬盘时,必须将编码格式设置为支持所输入字符的编码格式
- 保证存的时候不乱:在由硬盘读入内存时,必须采用与写入硬盘时相同的编码格式
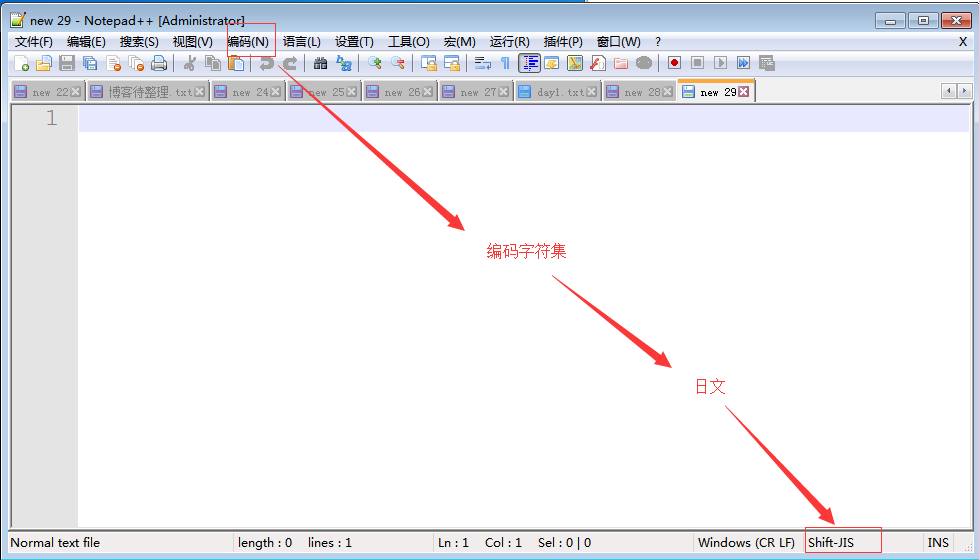
4.1 文本编辑器nodpad++存取文本文件
文本编辑器存取的都是文本文件,而文本文件中包含的内容全为字符,所以存取文本文件都涉及到字符编码的问题。
4.2 python解释器执行文件的前两个阶段
执行py文件的前两个阶段就是python解释器读文本文件的过程,与文本编辑读文本文件的前两个阶段没人任何区别,要保证读不乱码,则必须将python解释器读文件时采用的编码方式设置为文件当初写入硬盘时的编码格式,如果没有设置,python解释器则才用默认的编码方式,在python3中默认为utf-8,在python2中默认为ASCII,我们可以通过指定文件头来修改默认的编码
- 在文件首行写入包含#号在内的以下内容
# coding: 当初文件写入硬盘时采用的编码格式
解释器会先用默认的编码方式读取文件的首行内容,由于首行是纯英文组成,而任何编码方式都可以识别英文字符。
4.3 python解释器执行文件的第三个阶段
设置文件头的作用是保证运行python程序的前两个阶段不乱码,经过前两个阶段后py文件的内容都会以unicode格式存放于内存中。
在经历第三个阶段时开始识别python语法,当遇到特定的语法name = ‘上’(代码本身也都全都是unicode格式存的)时,需要申请内存空间来存储字符串’上’,这就又涉及到应该以什么编码存储‘上’的问题了。
在Python3中,字符串类的值都是使用unicode格式来存储
由于Python2的盛行是早于unicode的,因此在Python2中是按照文件头指定的编码来存储字符串类型的值的(如果文件头中没有指定编码,那么解释器会按照它自己默认的编码方式来存储‘上’),所以,这就有可能导致乱码问题
# coding:utf-8
x = '上' # x的值为untf-8格式的二进制
print(x) # 打印操作是将x的值,即utf-8格式的二进制交给终端,当终端收到后发现并不是unicode(只有unicode才与字符有对应关系),所以终端会执行操作:utf-8二进制—解码–>unicode格式的二进制,解码的过程终端会采用自己默认的编码,而在pycharm的终端默认编码为utf-8、windows下的cmd终端的默认编码为gbk,所以该打印操作在pycharm中显示正常,而在windows下的cmd中则乱码。
python2后推出了一种补救措施,就是在字符串类型前加u,则会将字符串类型强制存储unicode,这就与python3保持一致了,对于unicode格式无论丢给任何终端进行打印,都可以直接对应字符不会出现乱码问题
# coding:utf-8
x = u'上' # 即便文件头为utf-8,x的值依然存成unicode
4.4 字符串encode编码与decode解码的使用
# 1、unicode格式------编码encode-------->其它编码格式
>>> x='上' # 在python3在'上'被存成unicode
>>> res=x.encode('utf-8')
>>> res,type(res) # unicode编码成了utf-8格式,而编码的结果为bytes类型,可以当作直接当作二进制去使用
(b'\xe4\xb8\x8a', <class 'bytes'>)
# 2、其它编码格式------解码decode-------->unicode格式
>>> res.decode('utf-8')
'上'
文件处理
一 引入
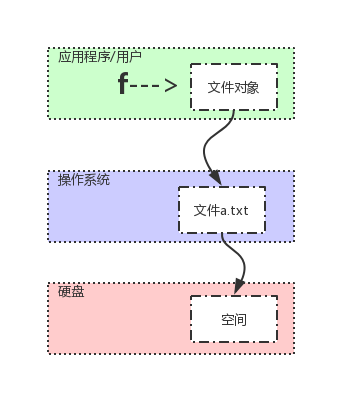
应用程序运行过程中产生的数据最先都是存放于内存中的,若想永久保存下来,必须要保存于硬盘中。应用程序若想操作硬件必须通过操作系统,而文件就是操作系统提供给应用程序来操作硬盘的虚拟概念,用户或应用程序对文件的操作,就是向操作系统发起调用,然后由操作系统完成对硬盘的具体操作。
二 文件操作的基本流程
2.1 基本流程
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
# 1. 打开文件,由应用程序向操作系统发起系统调用open(...),操作系统打开该文件,对应一块硬盘空间,并返回一个文件对象赋值给一个变量f
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r
# 2. 调用文件对象下的读/写方法,会被操作系统转换为读/写硬盘的操作
data=f.read()
# 3. 向操作系统发起关闭文件的请求,回收系统资源
f.close()
2.2 资源回收与with上下文管理
打开一个文件包含两部分资源:应用程序的变量f和操作系统打开的文件。在操作完毕一个文件时,必须把与该文件的这两部分资源全部回收,回收方法为:
1、f.close() #回收操作系统打开的文件资源
2、del f #回收应用程序级的变量
其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件无法关闭,白白占用资源,
而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close(),虽然我们如此强调,但是大多数读者还是会不由自主地忘记f.close(),考虑到这一点,python提供了with关键字来帮我们管理上下文
# 1、在执行完子代码块后,with 会自动执行f.close()
with open('a.txt','w') as f:
pass
# 2、可用用with同时打开多个文件,用逗号分隔开即可
with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data = read_f.read()
write_f.write(data)
2.3 指定操作文本文件的字符编码
f = open(...)是由操作系统打开文件,如果打开的是文本文件,会涉及到字符编码问题,如果没有为open指定编码,那么打开文本文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
这就用到了上节课讲的字符编码的知识:若要保证不乱码,文件以什么方式存的,就要以什么方式打开。
f = open('a.txt','r',encoding='utf-8')
三 文件的操作模式
3.1 控制文件读写操作的模式
r(默认的):只读
w:只写
a:只追加写
3.1.1 案例一:r 模式的使用
# r只读模式: 在文件不存在时则报错,文件存在文件内指针直接跳到文件开头
with open('a.txt',mode='r',encoding='utf-8') as f:
res=f.read() # 会将文件的内容由硬盘全部读入内存,赋值给res
# 小练习:实现用户认证功能
inp_name=input('请输入你的名字: ').strip()
inp_pwd=input('请输入你的密码: ').strip()
with open(r'db.txt',mode='r',encoding='utf-8') as f:
for line in f:
# 把用户输入的名字与密码与读出内容做比对
u,p=line.strip('\n').split(':')
if inp_name == u and inp_pwd == p:
print('登录成功')
break
else:
print('账号名或者密码错误')
3.1.2 案例二:w 模式的使用
# w只写模式: 在文件不存在时会创建空文档,文件存在会清空文件,文件指针跑到文件开头
with open('b.txt',mode='w',encoding='utf-8') as f:
f.write('你好\n')
f.write('我好\n')
f.write('大家好\n')
f.write('111\n222\n333\n')
#强调:
# 1 在文件不关闭的情况下,连续的写入,后写的内容一定跟在前写内容的后面
# 2 如果重新以w模式打开文件,则会清空文件内容
3.1.3 案例三:a 模式的使用
# a只追加写模式: 在文件不存在时会创建空文档,文件存在会将文件指针直接移动到文件末尾
with open('c.txt',mode='a',encoding='utf-8') as f:
f.write('44444\n')
f.write('55555\n')
#强调 w 模式与 a 模式的异同:
# 1 相同点:在打开的文件不关闭的情况下,连续的写入,新写的内容总会跟在前写的内容之后
# 2 不同点:以 a 模式重新打开文件,不会清空原文件内容,会将文件指针直接移动到文件末尾,新写的内容永远写在最后
# 小练习:实现注册功能:
name=input('username>>>: ').strip()
pwd=input('password>>>: ').strip()
with open('db1.txt',mode='a',encoding='utf-8') as f:
info='%s:%s\n' %(name,pwd)
f.write(info)
3.1.4 案例四:+ 模式的使用(了解)
# r+ w+ a+ :可读可写
#在平时工作中,我们只单纯使用r/w/a,要么只读,要么只写,一般不用可读可写的模式
3.2 控制文件读写内容的模式
大前提: tb模式均不能单独使用,必须与r/w/a之一结合使用
t(默认的):文本模式
1. 读写文件都是以字符串为单位的
2. 只能针对文本文件
3. 必须指定encoding参数
b:二进制模式:
1.读写文件都是以bytes/二进制为单位的
2. 可以针对所有文件
3. 一定不能指定encoding参数
3.2.1 案例一:t 模式的使用
# t 模式:如果我们指定的文件打开模式为r/w/a,其实默认就是rt/wt/at
with open('a.txt',mode='rt',encoding='utf-8') as f:
res=f.read()
print(type(res)) # 输出结果为:<class 'str'>
with open('a.txt',mode='wt',encoding='utf-8') as f:
s='abc'
f.write(s) # 写入的也必须是字符串类型
#强调:t 模式只能用于操作文本文件,无论读写,都应该以字符串为单位,而存取硬盘本质都是二进制的形式,当指定 t 模式时,内部帮我们做了编码与解码
3.2.2 案例二: b 模式的使用
# b: 读写都是以二进制位单位
with open('1.mp4',mode='rb') as f:
data=f.read()
print(type(data)) # 输出结果为:<class 'bytes'>
with open('a.txt',mode='wb') as f:
msg="你好"
res=msg.encode('utf-8') # res为bytes类型
f.write(res) # 在b模式下写入文件的只能是bytes类型
#强调:b模式对比t模式
1、在操作纯文本文件方面t模式帮我们省去了编码与解码的环节,b模式则需要手动编码与解码,所以此时t模式更为方便
2、针对非文本文件(如图片、视频、音频等)只能使用b模式
# 小练习: 编写拷贝工具
src_file=input('源文件路径: ').strip()
dst_file=input('目标文件路径: ').strip()
with open(r'%s' %src_file,mode='rb') as read_f,open(r'%s' %dst_file,mode='wb') as write_f:
for line in read_f:
# print(line)
write_f.write(line)
四 操作文件的方法
4.1 重点
# 读操作
f.read() # 读取所有内容,执行完该操作后,文件指针会移动到文件末尾
f.readline() # 读取一行内容,光标移动到第二行首部
f.readlines() # 读取每一行内容,存放于列表中
# 强调:
# f.read()与f.readlines()都是将内容一次性读入内容,如果内容过大会导致内存溢出,若还想将内容全读入内存,则必须分多次读入,有两种实现方式:
# 方式一
with open('a.txt',mode='rt',encoding='utf-8') as f:
for line in f:
print(line) # 同一时刻只读入一行内容到内存中
# 方式二
with open('1.mp4',mode='rb') as f:
while True:
data=f.read(1024) # 同一时刻只读入1024个Bytes到内存中
if len(data) == 0:
break
print(data)
# 写操作
f.write('1111\n222\n') # 针对文本模式的写,需要自己写换行符
f.write('1111\n222\n'.encode('utf-8')) # 针对b模式的写,需要自己写换行符
f.writelines(['333\n','444\n']) # 文件模式
f.writelines([bytes('333\n',encoding='utf-8'),'444\n'.encode('utf-8')]) #b模式
4.2 了解
f.readable() # 文件是否可读
f.writable() # 文件是否可读
f.closed # 文件是否关闭
f.encoding # 如果文件打开模式为b,则没有该属性
f.flush() # 立刻将文件内容从内存刷到硬盘
f.name
五 主动控制文件内指针移动
#大前提:文件内指针的移动都是Bytes为单位的,唯一例外的是t模式下的read(n),n以字符为单位
with open('a.txt',mode='rt',encoding='utf-8') as f:
data=f.read(3) # 读取3个字符
with open('a.txt',mode='rb') as f:
data=f.read(3) # 读取3个Bytes
# 之前文件内指针的移动都是由读/写操作而被动触发的,若想读取文件某一特定位置的数据,则则需要用f.seek方法主动控制文件内指针的移动,详细用法如下:
# f.seek(指针移动的字节数,模式控制):
# 模式控制:
# 0: 默认的模式,该模式代表指针移动的字节数是以文件开头为参照的
# 1: 该模式代表指针移动的字节数是以当前所在的位置为参照的
# 2: 该模式代表指针移动的字节数是以文件末尾的位置为参照的
# 强调:其中0模式可以在t或者b模式使用,而1跟2模式只能在b模式下用
5.1 案例一: 0模式详解
# a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节)
abc你好
# 0模式的使用
with open('a.txt',mode='rt',encoding='utf-8') as f:
f.seek(3,0) # 参照文件开头移动了3个字节
print(f.tell()) # 查看当前文件指针距离文件开头的位置,输出结果为3
print(f.read()) # 从第3个字节的位置读到文件末尾,输出结果为:你好
# 注意:由于在t模式下,会将读取的内容自动解码,所以必须保证读取的内容是一个完整中文数据,否则解码失败
with open('a.txt',mode='rb') as f:
f.seek(6,0)
print(f.read().decode('utf-8')) #输出结果为: 好
5.2 案例二: 1模式详解
# 1模式的使用
with open('a.txt',mode='rb') as f:
f.seek(3,1) # 从当前位置往后移动3个字节,而此时的当前位置就是文件开头
print(f.tell()) # 输出结果为:3
f.seek(4,1) # 从当前位置往后移动4个字节,而此时的当前位置为3
print(f.tell()) # 输出结果为:7
5.3 案例三: 2模式详解
# a.txt用utf-8编码,内容如下(abc各占1个字节,中文“你好”各占3个字节)
abc你好
# 2模式的使用
with open('a.txt',mode='rb') as f:
f.seek(0,2) # 参照文件末尾移动0个字节, 即直接跳到文件末尾
print(f.tell()) # 输出结果为:9
f.seek(-3,2) # 参照文件末尾往前移动了3个字节
print(f.read().decode('utf-8')) # 输出结果为:好
# 小练习:实现动态查看最新一条日志的效果
import time
with open('access.log',mode='rb') as f:
f.seek(0,2)
while True:
line=f.readline()
if len(line) == 0:
# 没有内容
time.sleep(0.5)
else:
print(line.decode('utf-8'),end='')
六 文件的修改
# 文件a.txt内容如下
张一蛋 山东 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422
# 执行操作
with open('a.txt',mode='r+t',encoding='utf-8') as f:
f.seek(9)
f.write('<妇女主任>')
# 文件修改后的内容如下
张一蛋<妇女主任> 179 49 12344234523
李二蛋 河北 163 57 13913453521
王全蛋 山西 153 62 18651433422
# 强调:
# 1、硬盘空间是无法修改的,硬盘中数据的更新都是用新内容覆盖旧内容
# 2、内存中的数据是可以修改的
文件对应的是硬盘空间,硬盘不能修改对应着文件本质也不能修改,
那我们看到文件的内容可以修改,是如何实现的呢?
大致的思路是将硬盘中文件内容读入内存,然后在内存中修改完毕后再覆盖回硬盘
具体的实现方式分为两种:
6.1 文件修改方式一
# 实现思路:将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件
# 优点: 在文件修改过程中同一份数据只有一份
# 缺点: 会过多地占用内存
with open('db.txt',mode='rt',encoding='utf-8') as f:
data=f.read()
with open('db.txt',mode='wt',encoding='utf-8') as f:
f.write(data.replace('kevin','SB'))
6.1 文件修改方式二
# 实现思路:以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容,修改完后写入临时文件...,删掉原文件,将临时文件重命名原文件名
# 优点: 不会占用过多的内存
# 缺点: 在文件修改过程中同一份数据存了两份
import os
with open('db.txt',mode='rt',encoding='utf-8') as read_f,\
open('.db.txt.swap',mode='wt',encoding='utf-8') as wrife_f:
for line in read_f:
wrife_f.write(line.replace('SB','kevin'))
os.remove('db.txt')
os.rename('.db.txt.swap','db.txt')
Python基础——字符编码、文件处理的更多相关文章
- Python基础-字符编码与转码
***了解计算机的底层原理*** Python全栈开发之Python基础-字符编码与转码 需知: 1.在python2默认编码是ASCII, python3里默认是utf-8 2.unicode 分为 ...
- Python基础(字符编码与文件处理)
一.了解字符编码的知识储备 1.计算机基础知识(三副图) 2.文本编辑器存取文件的原理(notepad++,Pycharm,word) 打开编辑器就启动了一个进程,是在内存中运行的,所以在编辑器写的内 ...
- python基础--字符编码以及文件操作
字符编码: 1.运行程序的三个核心硬件:cpu.内存.硬盘 任何一个程序要是想要运算,肯定是先从硬盘加载到当前的内存中,然后cpu根据指定的指令去执行操作 2.python解释器运行一个py文件的步骤 ...
- python基础-----字符编码
1.ASCII ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现 ...
- 第2章 Python基础-字符编码&数据类型 字符编码&字符串 练习题
1.简述位.字节的关系 位(bit)是计算机中最小的表示单元,数据传输是以“位”为单位的,1bit缩写为1b 字节(Byte)是计算机中最小的存储单位,1Byte缩写为1B 8bit = 1Byte ...
- 第2章 Python基础-字符编码&数据类型 购物车&多级菜单 作业
作业 一.三级菜单 数据结构: menu = { '北京':{ '海淀':{ '五道口':{ 'soho':{}, '网易':{}, 'google':{} }, '中关村':{ '爱奇艺':{}, ...
- 第2章 Python基础-字符编码&数据类型 列表&元祖 练习题
1.创建一个空列表,命名为names,往里面添加old_driver,rain,jack,shanshan,peiqi,black_girl元素 names = ["old_driver&q ...
- 第2章 Python基础-字符编码&数据类型 综合 练习题
1.转换 将字符串s = "alex"转换成列表 s = "alex" s_list = list(s) print(s_list) 将字符串s = " ...
- 第2章 Python基础-字符编码&数据类型 字典 练习题
1.写代码,有如下字典,按照要求实现每一个功能,dic = {'k1':'v1','k2':'v2','k3':[11,22,33]} 请循环输出所有的 key dic = {'k1':'v1','k ...
- python基础之编码问题
python基础之编码问题 本节内容 字符串编码问题由来 字符串编码解决方案 1.字符串编码问题由来 由于字符串编码是从ascii--->unicode--->utf-8(utf-16和u ...
随机推荐
- RabbitMQ快速使用代码手册
本篇博客的内容为RabbitMQ在开发过程中的快速上手使用,侧重于代码部分,几乎没有相关概念的介绍,相关概念请参考以下csdn博客,两篇都是我找的精华帖,供大家学习.本篇博客也持续更新~~~ 内容代码 ...
- R数据分析:解决科研中的“可重复危机”,理解Rmarkdown
不知道刚接触科研的大伙儿有没有这么一个感觉,别人的研究很大可能你重复不出来,尤其是社科实证研究,到现在我都还觉得所谓的实证是个很玄乎的东西: 如果是刚开始做数据分析,很多时候你会发现自己的分析结果过几 ...
- mysql 查询时间段的数据怎么写?
测试让我查询2个时间段的数据,这里不怎么会,所以记录一下: 一般可以使用如下语法: select * from xxx表 where xx='xx' and time between '时间戳' ...
- Mininet教程
mininet的安装 1.前言 1.本次安装环境为ubuntu20.04. 2.mininet 为 github上的最新版,我已经修改镜像地址并克隆到了gitee,只需要从我的gitee仓库克隆即可. ...
- PB从入坑到放弃(一)第一个HelloWorld程序
前言 网上关于PowerBuilder的资料确实是少之又少. 为了方便,后面我们都用pb 来代替PowerBuilder 说到这不得不来说说自己的pb入坑经历, 自己也不是计算机科班出生. 刚到公司面 ...
- 基于GPT搭建私有知识库聊天机器人(五)函数调用
文章链接: 基于GPT搭建私有知识库聊天机器人(一)实现原理 基于GPT搭建私有知识库聊天机器人(二)环境安装 基于GPT搭建私有知识库聊天机器人(三)向量数据训练 基于GPT搭建私有知识库聊天机器人 ...
- 2023-07-13:如果你熟悉 Shell 编程,那么一定了解过花括号展开,它可以用来生成任意字符串。 花括号展开的表达式可以看作一个由 花括号、逗号 和 小写英文字母 组成的字符串 定义下面几条语
2023-07-13:如果你熟悉 Shell 编程,那么一定了解过花括号展开,它可以用来生成任意字符串. 花括号展开的表达式可以看作一个由 花括号.逗号 和 小写英文字母 组成的字符串 定义下面几条语 ...
- Redis和Mysql保持数据一致性
1.简述 在高并发的场景下,大量的请求直接访问Mysql很容易造成性能问题.所以,我们都会用Redis来做数据的缓存,削减对数据库的请求.但是,Mysql和Redis是两种不同的数据库,如何保证不 ...
- Blazor前后端框架Known-V1.2.7
V1.2.7 Known是基于C#和Blazor开发的前后端分离快速开发框架,开箱即用,跨平台,一处代码,多处运行. Gitee: https://gitee.com/known/Known Gith ...
- CF1601 题解
偶然看这一场的题目,忽然很有感觉,于是写了一下 A 题面 考虑每一位可以单独分开考虑 考虑单独的一位,每次要选 \(m\) 个位置,可能产生贡献的位置就是这位为 1 的数,设数量为 \(x\),则 \ ...