fepk文件格式说明
1 卫星影像金字塔分块原理说明

通常我们在工作中使用的卫星影像数据,轻则几百M,重则几百个G甚至上TB级。影像数据太大,是大家经常会遇到的一个问题,尤其是想下载一个省以上数据的时候该问题尤为突出。那么该问题是否有一个比较好的解决方案呢?
以全球为例,我们以19级为例,共有2^18 * 2^17 张瓦片,如此多的瓦片会让磁盘愈来愈慢,同时也无法维护。
当影像范围比较大时,我们可以采用金字塔分块的方式进行管理,系统会自动将大范围分成若干个块,且块与块之间是可以无缝拼接的。
一般情况我们选择全球前10级别作为基础级别,因数据量不大(1G)左右,后续以10级作为基础级别,全球19级别数据被划分为 2^8 * 2^7(512 * 256)个块。每个块中包含了256 * 256 张小瓦片。
1.1 Fepk文件命名规则
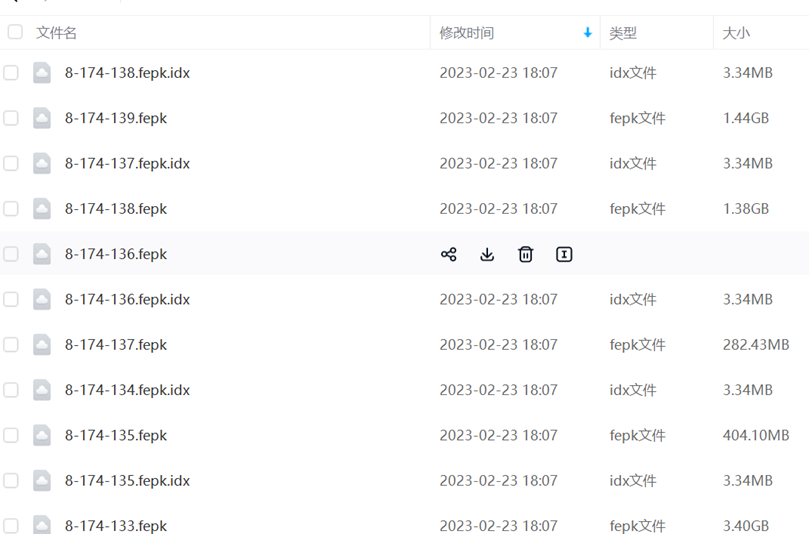
文件说明(包含索引与数据两个文件,文件必须都配套才可以正常使用):
*.fepk :文件中存储具体的瓦片数据。
*.fepk.idx :文件中存储的瓦片的索引信息,当给定一个瓦片编号后,可以根据编号计算出来瓦片存在索引中的信息(大小,以及数据在8-174-138.fepk中的位置)。
名称命名规
以8-174-138.fepk为例:其中8是级别,174是列号,138是行号,文件中存储了8-174-138瓦片裂分出来的所有瓦片数据。
2 .fepk文件格式说明
我们一般不会直接采用瓦片作为管理单元,会把一个块作为管理单元,把数据划分为索引文件与数据文件,如下所示:
数据文件:world.fepk
索引文件:world.fepk.idx
2.1 索引文件
表 1文件说明
|
文件头 |
字段 |
值 |
|
文件头 |
char szMagic[20] |
fe.tile.store.data20字节 |
|
uint version |
版本号4字节 |
|
|
uint typeId |
数据类型 enum PKType { PK_IMAGE , PK_DEM, PK_VEC, PK_QXSY, PK_USER, };4字节 |
|
|
uint wgs84 |
是否是wgs84经纬投影4字节 |
|
|
uint flag |
4字节 |
|
|
uint64 timestamp |
时间戳8字节 |
|
|
real2 vStart |
经纬度最小范围8*2字节 |
|
|
real2 vEnd |
经纬度最大范围 8*2字节 |
|
|
LevSnap levOff[24] |
级别索引,8 * 24 字节 |
|
|
char _reserve[240] |
保留 |
|
|
级别1 |
int2 _start |
2 * 4字节,瓦片最小行列号 |
|
int2 _end |
2 * 4字节,瓦片最大行列号 |
|
|
uint64 _offset |
8字节 |
|
|
uint64 _dataSize |
8字节 |
|
|
uint _lev |
4字节 |
|
|
char _reserve[216] |
216字节 |
|
|
瓦片数据索引矩阵数据PKTLHeader |
N * PKTLHeader N = (_end.x |
|
|
PKTLHeader |
|
|
|
级别2 |
|
|
|
级别3 |
||
|
级别… |
PKTLHeader定义:
PKTLHeader定义:
struct PKTLHeader
{
/// 有无数据标记,即服务器上是否有该数据 0,无,1,有
uint64 _data:2;
/// 在本文件中是否已经存储 0,无,1,有
uint64 _stored:2;
/// 状态,
uint64 _state :6;
/// 数据地址,使用50个bit最大 2^54
/// 单个文件最大16 K T
uint64 _offset : 54;
/// 如果该值!= 0xFFFF,则有效,否则无效,
/// 使用该字段的意义在于解决网络读取问题,比如在云盘上
/// 先读取索引,如果没有数据大小,或者数据大小存储在数据文件中,则需要
/// 再次访问数据文件,才可以得大小,增加额外的IO,同时兼顾大小,该变量最大可以存储64K
/// 如果超过了64K,那么一样的需要访问数据文件获取大小
ushort _dataSize;
};
共计10自字节
LevSnap定义:
struct LevSnap
{
uint64 _lev:8;
uint64 _offset:56;
};
共计8字节
2.2 数据文件文件
|
文件头 |
字段 |
值 |
|
文件头 |
char szMagic[20] |
fe.tile.store.data20字节 |
|
uint version |
版本号4字节 |
|
|
uint typeId |
数据类型 enum PKType { PK_IMAGE , PK_DEM, PK_VEC, PK_QXSY, PK_USER, };4字节 |
|
|
uint wgs84 |
是否是wgs84经纬投影4字节 |
|
|
uint flag |
4字节 |
|
|
uint64 timestamp |
时间戳8字节 |
|
|
real2 vStart |
经纬度最小范围8*2字节 |
|
|
real2 vEnd |
经纬度最大范围 8*2字节 |
|
|
LevSnap levOff[24] |
级别索引,8 * 24 字节 |
|
|
char _reserve[240] |
保留 |
|
|
数据0 |
Int4 |
4*4字节,行号,列号,级别,大小 |
|
数据 |
||
|
数据1 |
Int4 |
4*4字节,行号,列号,级别,大小 |
|
数据 |
||
|
数据… |
Int4 |
4*4字节,行号,列号,级别,大小 |
|
数据 |
3 如何使用数据
3.1 解压成标注金字塔瓦片
用户可以通过FEPKUNPack.exe
解压程序,将数据加压标准的金字塔瓦片,然后即可使用,导出后如下所示。
导出后可以方便的被osgEarth,cesium,argis,fastearth等软件直接加载。
缺点: 导出后,占用磁盘大小比未解压前大50%。
导出后,维护困难,因为文件很多,拷贝能都受到影响。
数据截图

3.2 API读取瓦片
使用SDK/API访问数据,为了方便大家使用,避免数据解压,可以使用FEPKReadApi
SDK读取数据,SDK使用C语言编写,接口如下所示
extern "C"
{
/// <summary>
/// 打开文件函数,可以打开索引也可以打开数据文件
/// </summary>
/// <param name = "fileName">文件名称</param>
/// <return>0:失败,否则成功</return>
FEPKFile fepkOpenFile(const char* fileName);
/// <summary>
/// 读取索引数据函数
/// </summary>
/// <param name = "file">索引文件指针</param>
/// <param name = "x">列号</param>
/// <param name = "y">行号</param>
/// <param name = "z">级别</param>
/// <param name = "header">返回文件头信息</param>
/// <return>true:false</return>
bool fepkReadHeader(FEPKFile file,int x,int y,int z,FEPHHeader* header);
/// <summary>
/// 根据文件头信息读取文件大小(瓦片数据大小)
/// </summary>
/// <param name = "file">索引文件指针</param>
/// <param name = "header">文件头信息</param>
/// <param name = "pSize">输出文件大小</param>
/// <return>true:false</return>
bool fepkReadDataSize(FEPKFile file,const FEPHHeader* header,uint* pSize);
/// <summary>
/// 读取瓦片数据函数
/// </summary>
/// <param name = "file">索引文件指针</param>
/// <param name = "header">文件头信息</param>
/// <param name = "pBuf">输入缓冲区大小</param>
/// <param name = "nBufLen">缓冲区长度</param>
/// <return> -1:失败,0:无数据,>0 数据的真实大小</return>
int fepkReadData(FEPKFile file,const FEPHHeader* header,void* pBuf,uint nBufLen);
/// <summary>
/// 关闭文件
/// </summary>
void fepkCloseFile(FEPKFile file);
/// <summary>
/// 从一个文件夹中读取瓦片的数据头,以及瓦片的大小
/// </summary>
/// <param name = "path">目录组,以null结束</param>
/// <param name = "x">瓦片的编号</param>
/// <param name = "y">瓦片的编号</param>
/// <param name = "z">瓦片的编号</param>
/// <param name = "header">文件头信息</param>
/// <param name = "pSize">瓦片大小</param>
/// <return>返回打开的文件</return>
FEPKFile fepkReadTileHeader(const char** path,int x,int y,int z,FEPHHeader* header,uint* pSize);
/// <summary>
/// 从一个文件夹中读取
/// </summary>
/// <param name = "file">文件句柄</param>
/// <param name = "header">文件头信息</param>
/// <param name = "pBuf">输入/输出,从fepkReadTileHeader读取</param>
/// <param name = "nBufLen">输入,从fepkReadTileHeader读取</param>
/// <return>返回读取的长度-1,失败,0,文件内部错误,其他读取的长度</return>
int fepkReadTileData(FEPKFile file,const FEPHHeader* header,void* pBuf,uint nBufLen); }
使用说明:
#include "FEPKReaderApi.h" #include <stdio.h>
/// 如果是SDK,非源码方式,则需要因入库
/// #pragma comment(lib,"FEPKReader.lib")
int main(int, char**)
{
/// 1. 开发文件
FEPKFile file = fepkOpenFile("D:\\FE\\data\\fepk\\world.fepk");
if (file == nullptr)
{
return 0;
}
FEPHHeader header;
uint nSize = 0;
/// 2. 读取给定瓦片编号的文件头信息
/// 如果返回false,说明当前文件中没有给定的瓦片数据
if (!fepkReadHeader(file, 0, 0, 0, &header))
{
return 0;
}
/// 3. 读取数据大小
if (!fepkReadDataSize(file, &header, &nSize))
{
return 0;
}
/// 申请空间
char* pBuf = new char[nSize];
/// 4. 读取数据
if (!fepkReadData(file, &header, pBuf, nSize))
{
printf("read ok!\n");
}
/// 5. 释放内存
delete[]pBuf;
/// 6. 关闭文件
fepkCloseFile(file);
return 0;
}
fepk文件格式说明的更多相关文章
- RIFF和WAVE音频文件格式
RIFF file format RIFF全称为资源互换文件格式(Resources Interchange File Format),是Windows下大部分多媒体文件遵循的一种文件结构.RIFF文 ...
- JavaSe:Properties文件格式
Properties文件格式说明 Properties继承自Hashtable,是由一组key-value的集合. 在Java中,常用properties文件作为配置文件.它的格式是什么样的呢? 下图 ...
- Dotnet文件格式解析
0x0.序 解析过程并没有介绍对pe结构的相关解析过程,网上此类相关资料很多可自行查阅,本文只介绍了网上资料较少的从pe结构的可选头中的数据目录表中获取dotnet目录的rva和size,到完全解析d ...
- Reverse Core 第二部分 - 13章 - PE文件格式
@date: 2016/11/24 @author: dlive PE (portable executable) ,它是微软在Unix平台的COFF(Common Object File For ...
- iOS 图片文件格式判断、圆角图片
1.圆角图片 // 设置圆形图片(放到分类中使用) - (UIImage *)cutCircleImage { UIGraphicsBeginImageContextWithOptions(self. ...
- 基于 Hive 的文件格式:RCFile 简介及其应用
转载自:https://my.oschina.net/leejun2005/blog/280896 Hadoop 作为MR 的开源实现,一直以动态运行解析文件格式并获得比MPP数据库快上几倍的装载速度 ...
- 图解JVM的Class文件格式(详细版)
了解JAVA的Class文件结构有助于掌握JAVA语言的底层运行机制,我在学习的过程中会不断的与ELF文件格式作对比(当然他们的复杂程度.格式相去甚远,比如可执行ELF的符号表解析在静态链 ...
- dex文件格式一
一.生成dex文件 我们可以通过java文件来生成一个简单的dex文件 编译过程: 首先编写java代码如下: (1) 编译成 java class 文件 执行命令 : javac Hello.jav ...
- dex文件格式二
一. dex文件头 (1) magic value 在DexFile.c dexFileParse函数中 会先检查magic opt 啥是magic opt呢? 我们刚刚从cache目录拷贝出来的 ...
- stl文件格式
http://wenku.baidu.com/view/a3ab7a26ee06eff9aef8077b.html [每个三角形面片的定义包括三角形各个定点的三维坐标及三角形面片的法矢量[三角形的法线 ...
随机推荐
- WPF 入门笔记 - 03 - 样式基础及模板
程序的本质 - 数据结构 + 算法 本篇为学习李应保老师所著的<WPF专业编程指南>并搭配WPF开发圣经<WPF编程宝典第4版>以及痕迹大佬<WPF入门基础教程系列> ...
- C++内敛函数,构造函数,析构函数,浅拷贝
inline //inline函数可以有声明和实现,但是必须在同一文件//inline函数不能分成头文件和实现文件 inline int add(int x, int y){ //一般不要放循环语句 ...
- 十分钟了解MES系统的发展历程和标准体系
大家好,我是Edison. 上一篇,我们通过一个点菜的故事快速地了解了MES系统都能做哪些事儿<三分钟快速了解什么是MES系统>,相信大家都有了一个基本的感性认知.本篇,我们将时间拨回几十 ...
- docker构建FreeSWITCH编译环境及打包
操作系统 :CentOS 7.6_x64 FreeSWITCH版本 :1.10.9 Docker版本:23.0.6 FreeSWITCH这种比较复杂的系统,使用容器部署是比较方便的,今天 ...
- Python运维开发之路《函数》
函数 函数是组织好的,可重复使用的,用来实现单一,或相关联功能的代码段. 函数能提高应用的模块性,和代码的重复利用率.你已经知道Python提供了许多内建函数,比如print().但你也可以自己创建函 ...
- 解决Springboot项目打成jar包后获取resources目录下的文件失败的问题
前几天在项目读取resources目录下的文件时碰到一个小坑,明明在本地是可以正常运行的,但是一发到测试环境就报错了,说找不到文件,报错信息是:class path resource [xxxx] c ...
- go select 使用总结
转载请注明出处: 在Go语言中,select语句用于处理多个通道的并发操作.它类似于switch语句,但是select语句用于通信操作,而不是条件判断.select语句会同时监听多个通道的操作,并选择 ...
- Java作业_Day21_
多线程 一.判断题(T为正确,F为错误),每题1分 1.如果线程死亡,它便不能运行.(T) 2.在Java中,高优先级的可运行线程会抢占低优先级线程.( T) 3.线程可以用yield方法使低优先级的 ...
- Llama2开源大模型的新篇章以及在阿里云的实践
Llama一直被誉为AI社区中最强大的开源大模型.然而,由于开源协议的限制,它一直不能被免费用于商业用途.然而,这一切在7月19日发生了改变,当Meta终于发布了大家期待已久的免费商用版本Llama2 ...
- Unity UGUI的RectMask2D(2D遮罩)组件的介绍及使用
Unity UGUI的RectMask2D(2D遮罩)组件的介绍及使用 1. 什么是RectMask2D组件? RectMask2D是Unity UGUI中的一个组件,用于实现2D遮罩效果.它可以限制 ...