[.NET项目实战] Elsa开源工作流组件应用(二):内核解读
@
本篇将带你深入分析Elsa工作流原理,排除干扰展示关键代码段,以加深理解
定义
变量
Elsa工作原理可以抽象理解为管道中间件 + 异步模型
Elsa中,活动的变量的获取和设置都是异步的。Elsa定义了Variable类型作为异步操作的结果或者说是异步操作的占位符,这个变量在运行的时候才会填充数值。这与我们熟悉C#中的Task,或者js里的promise对象作用相同。输入Input,OutPut都属于 Variable。
Elsa模拟了内存寄存器(MemoryRegister)以及Set和Get访问器实现异步模型。
内存寄存器类
public class MemoryRegister
{
...
public IDictionary<string, MemoryBlock> Blocks { get; }
}
寄存器中的存储区块类
public class MemoryBlock
{
...
/// <summary>
/// The value stored in this block.
/// </summary>
public object? Value { get; set; }
/// <summary>
/// Optional metadata about this block.
/// </summary>
public object? Metadata { get; set; }
}
变量到存储的映射类
Id可以代表变量在内存区块中的引用地址
public class MemoryBlockReference
{
/// <summary>
/// The ID of the memory block.
/// </summary>
public string Id { get; set; } = default!;
public object? Get(MemoryRegister memoryRegister) => GetBlock(memoryRegister).Value;
}
构建活动时将创建活动中变量到存储区块的映射,分配一个引用给变量
public void AssignInputOutputs(IActivity activity)
{
var activityDescriptor = _activityRegistry.Find(activity.Type, activity.Version) ?? throw new Exception("Activity descriptor not found");
var inputs = activityDescriptor.GetWrappedInputProperties(activity).Values.Cast<Input>().ToList();
var seed = 0;
foreach (var input in inputs)
{
var blockReference = input?.MemoryBlockReference();
if (blockReference != null!)
if (string.IsNullOrEmpty(blockReference.Id))
blockReference.Id = $"{activity.Id}:input-{seed}";
seed++;
}
...
}
异步变量获取和设置:
可以通过上下文对象的Set,和Get方法,异步获取和设置异步变量。
上下文对象
查看源码可以看到Elsa定义了如下Context
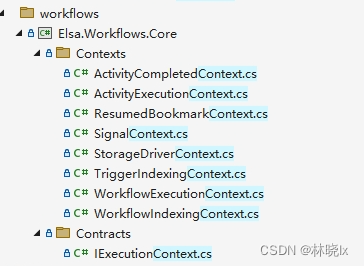
其中比较重要的上下文对象:
活动上下文(ActivityExecutionContext)
活动上下文对象由Elsa.Runtime提供,在工作流执行函数中可供访问。通过它可访问包含活动实例、当前输入和输出等。通过它可以访问当前活动所在的工作流执行上下文。
工作流执行上下文(WorkflowExecutionContext)
工作流上下文对象由Elsa.Runtime提供,可通过活动上下文(ActivityExecutionContext)访问其所属工作流执行上下文。通过它可访问包含工作流实例、当前活动、当前输入和输出等。
表达式执行上下文(ExpressionExecutionContext)
表达式执行上下文用于在构建活动时传递内存变量(输入,输出),其中包含MemoryRegister对象。
通过表达式执行上下文(ExpressionExecutionContext)获取到变量的值:

构建
构建活动
Elsa默认帮我们建立了这些活动:
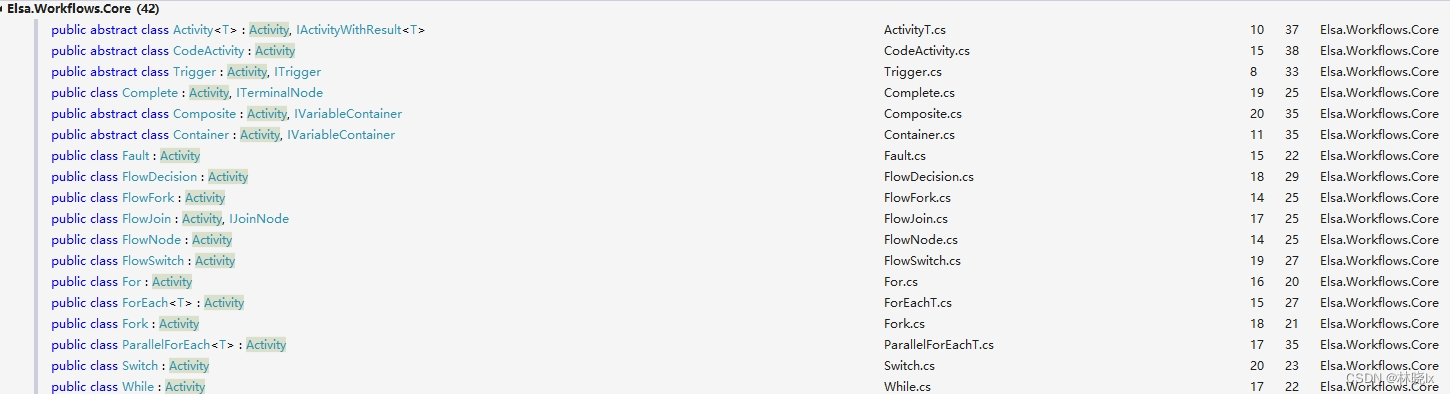

他们都实现了IActivity接口,Activity和CodeActivity是IActivity的实现类,对应的是一个空的活动,(CodeActivity是带有自动完成功能的空活动)
我们要做的是继承这个活动,重写Execute方法以实现我们自己的业务。比如:
public class HelloWorld : Activity
{
protected override async ValueTask ExecuteAsync(ActivityExecutionContext context)
{
Console.WriteLine("Hello World!");
await CompleteAsync();
}
}
以官方默认的WiteLine为例,这个类的Execute代码如下:
protected override void Execute(ActivityExecutionContext context)
{
var text = context.Get(Text);
var provider = context.GetService<IStandardOutStreamProvider>() ?? new StandardOutStreamProvider(System.Console.Out);
var textWriter = provider.GetTextWriter();
textWriter.WriteLine(text);
}
构建工作流
首要目标是拿到一个工作流对象(Workflow),Elsa启动时会从工作流提供者(IWorkflowProvider)获取所有能用的工作流。并注册到资源池中
public interface IWorkflowProvider
{
string Name { get; }
ValueTask<IEnumerable<MaterializedWorkflow>> GetWorkflowsAsync(CancellationToken cancellationToken = default);
}
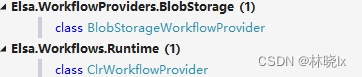
Elsa默认的实现类是如下两种,BlobStorageWorkflowProvider将从数据库(BlobStorage)中反序列化来注册。ClrWorkflowProvider使用工作流构建器注册。
我们先定义工作流描述类,它继承自IWorkflow, WorkflowBase是IWorkflow的抽象基类
class SequentialWorkflow : WorkflowBase
{
protected override void Build(IWorkflowBuilder workflow)
{
workflow.Root = new Sequence
{
Activities =
{
new WriteLine("Line 1"),
new WriteLine("Line 2"),
new WriteLine("Line 3")
}
};
}
}
Elsa初始化时,WorkflowBuilder会构建程序集中所有实现IWorkflow的类。
WorkflowBuilder中的BuildWorkflowAsync方法会将工作流描述类IWorkflow对象构建成Workflow对象。

这里思考一个问题:终执行的代码是在活动中定义的,但为什么返回的是Workflow对象?通过代码研读,实际上Workflow也是一个IActivity活动,只不过它具有一个Root根节点的复合活动。活动的定义请参考官方文档
BuildWorkflowAsync中的具体实现如下:

运行
注册
注册包括注册工作流和注册活动,配置Elsa时需要使用如下两个方法:
.AddActivitiesFrom<Program>()
.AddWorkflowsFrom<Program>()
注册工作流
工作流可以通过ClrWorkflowProvider,使用工作流构建器注册,也可以从本地存储(BlobStorage)中反序列化来注册。
代码构建的工作流是通过实现IWorkflow接口,在Elsa初始化时将工作流注册到工作流定义持久化到数据库的WorkflowDefinition表中
通过工作流构建器注册:

注册活动
Elsa使用描述器(IActivityDescriber)提供一个描述符(ActivityDescriptor),这里比较绕,阅读源码可以发现,其实是通过各种反射获取活动派生类的特征数据(有的系统喜欢将称之为元数据),封装这些数据的类型称之为描述符,特征数据可以作为在界面上显示,分组,排序的信息。
活动不同于工作流,它在运行中不持久化于数据库,而是以注册表的形式存储于内存中。
IDictionary<(string Type, int Version), ActivityDescriptor> _activityDescriptors
在构建工作流的时候自动注册活动,也可以通过实现IActivity接口,在Elsa初始化时将所有活动注册到注册表中

Elsa启动时将所有实现了IActivity接口的类型注册为活动:
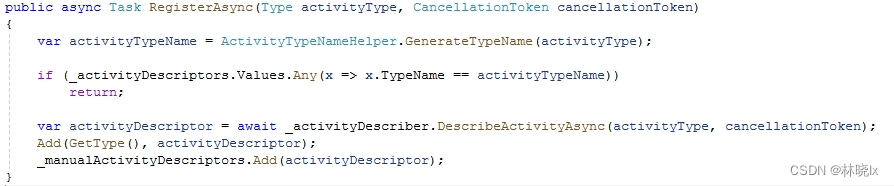
填充
启动时填充活动注册表和工作流定义表。
官方也给出了说明,各填充两次确保活动注册表和工作流定义表都是最新的:
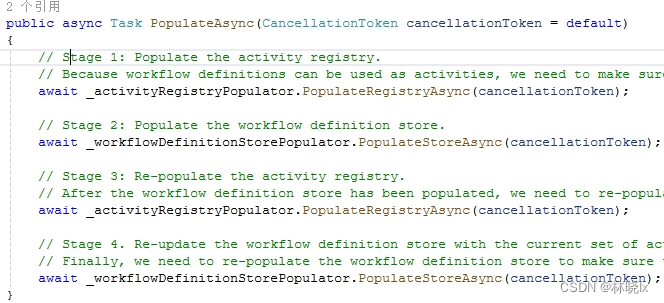
阶段一:填充活动注册表
因为工作流定义可以用作活动,需要确保在填充工作流定义表之前填充活动注册表。
阶段二:填充工作流定义表
阶段三:重新填充活动注册表
填充了工作流定义表之后,我们需要重新填充活动注册表,以确保活动描述符是最新的。
阶段四:用当前的活动集重新更新工作流定义表。
最后,需要重新填充工作流定义表,以确保工作流定义是最新的。
Invoke活动
Elsa默认的管道中间件:
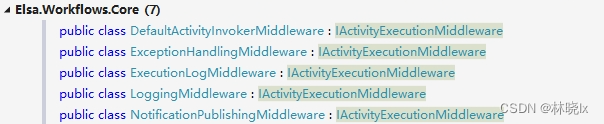
Elsa注册执行活动的中间件(DefaultActivityInvokerMiddleware):
public static class ActivityInvokerMiddlewareExtensions
{
/// <summary>
/// Adds the <see cref="DefaultActivityInvokerMiddleware"/> component to the pipeline.
/// </summary>
public static IActivityExecutionPipelineBuilder UseDefaultActivityInvoker(this IActivityExecutionPipelineBuilder pipelineBuilder) => pipelineBuilder.UseMiddleware<DefaultActivityInvokerMiddleware>();
}
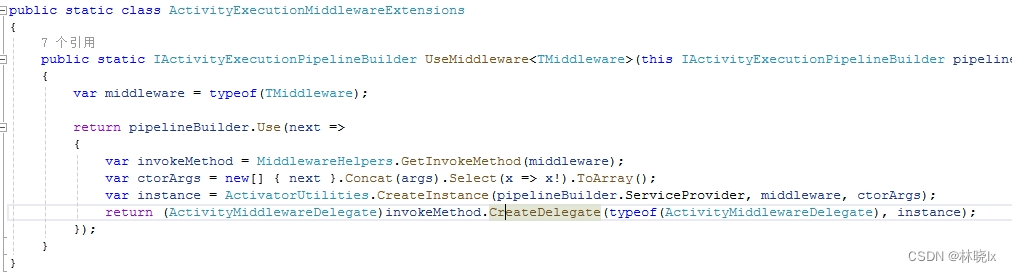
在执行活动的中间件(DefaultActivityInvokerMiddleware),最终活动被调用的代码如下:
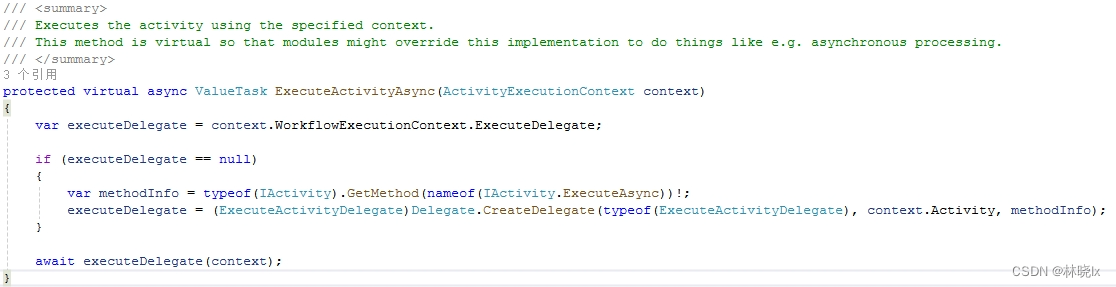
可以看见,Elsa最终以反射的方式创建一个Activity实例,然后调用它的ExecuteAsync方法。
可观测性
设计器与APIs
实际上,Elsa的运行时和设计器是完全分离的。Elsa提供了一个基于Blazor的设计工具,它作为独立的项目发布在Github上: Elsa-Studio
因为和接口交互是通过REST API实现的,所以你也可以使用任何你想要的客户端来实现。
接设计器默认的HTTP API实现在Elsa.Workflows.Api库中,用于支持设计器的增删改查业务。
如果仅要使用工作流引擎,可以使用Elsa.Workflows.Management库,它只包含对于工作流的管理而不涉及HTTP接口。
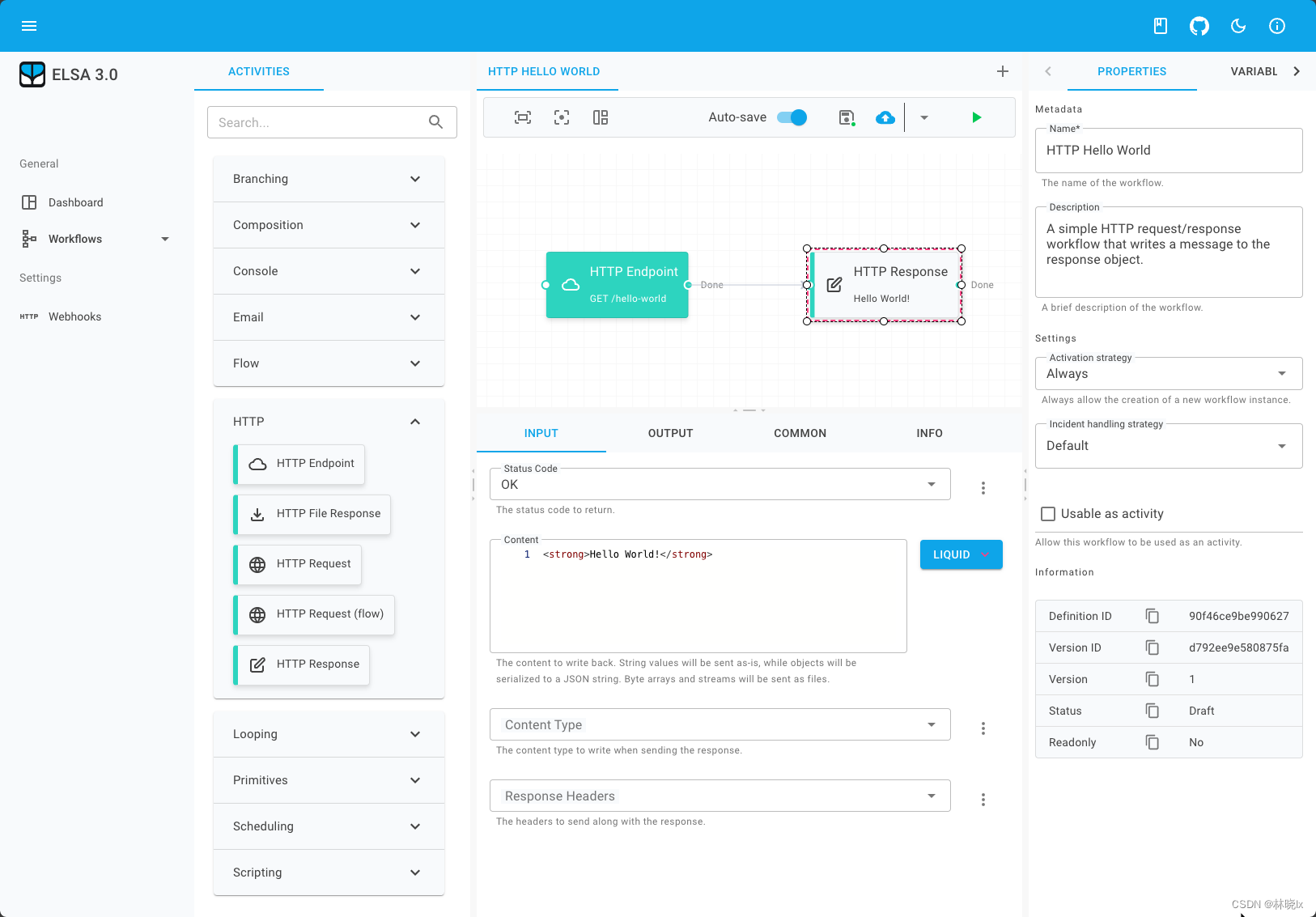
工作流配置
打开设计器,点击“工作流(Workflow)”菜单,然后单击“定义(Definition)”选项卡。可以看到一个工作流定义的列表。点击右上角新增按钮,
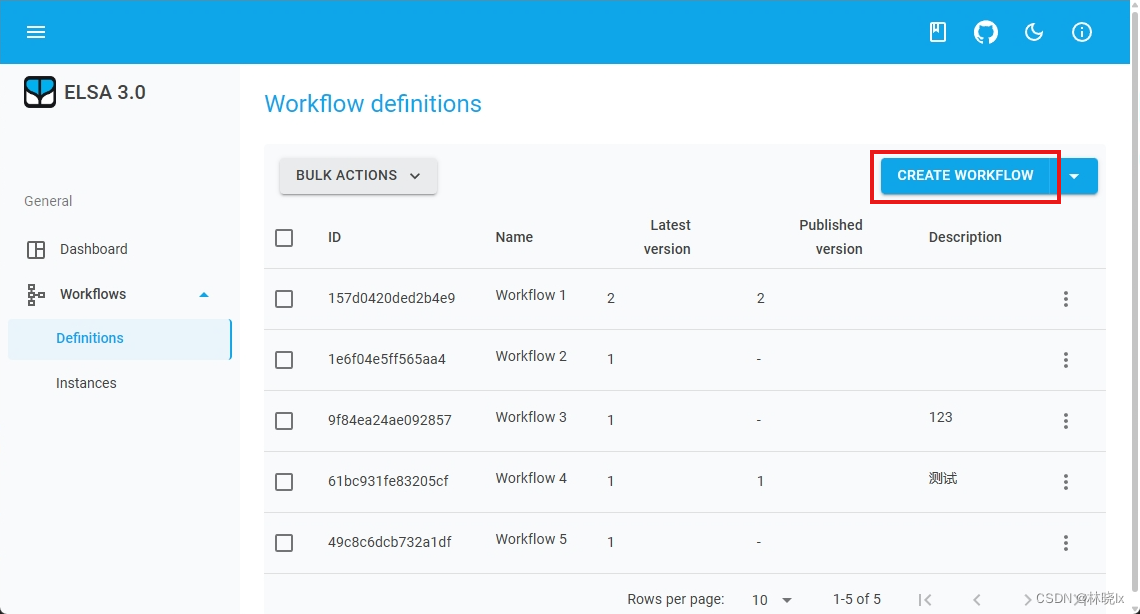
在打开的页面中,拖拽活动到工作流图上,然后单击“保存(Save)”按钮。
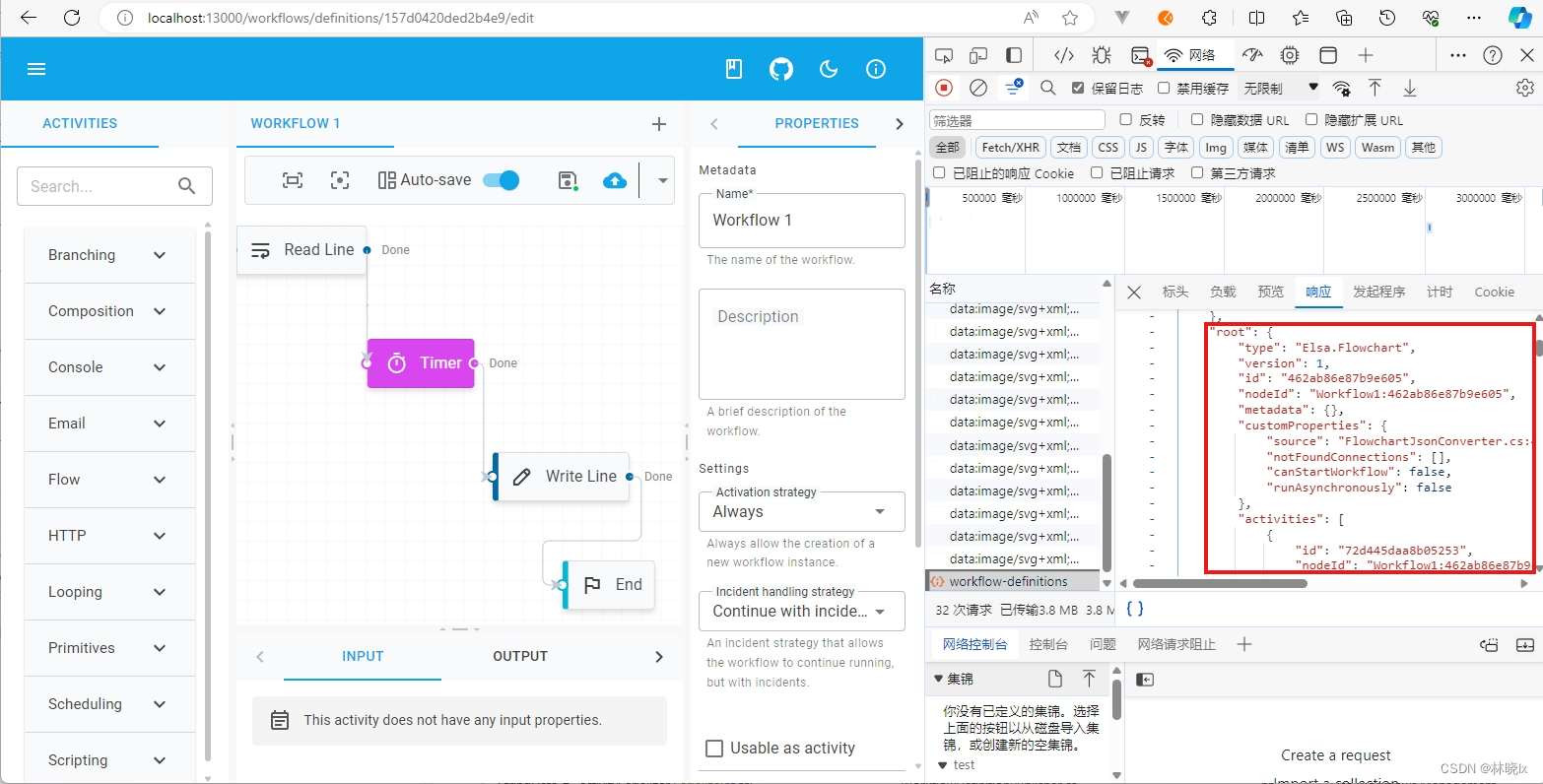
在浏览器的网络请求中可以看到一个POST请求,请求地址为/workflow/definitions,请求参数为JSON格式,后端服务中WorkflowDefinitions的Endpoint中将对编辑器的“保存”请求进行处理
在请求负载中,WorkflowDefinitionModel字段会包含工作流定义和Root活动。
默认实现会将工作流定义和根活动序列化为JSON,并将其保存到数据库中。其中根活动在数据库WorkflowDefinition表的StringData列中存储。
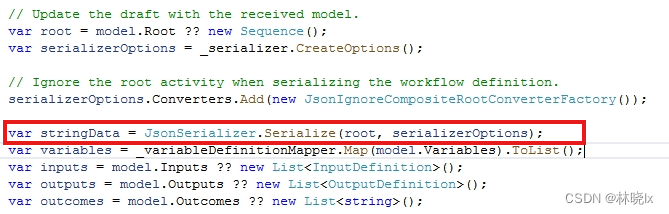
当工作流执行时,Elsa会实例化(Materialize)Workflow对象

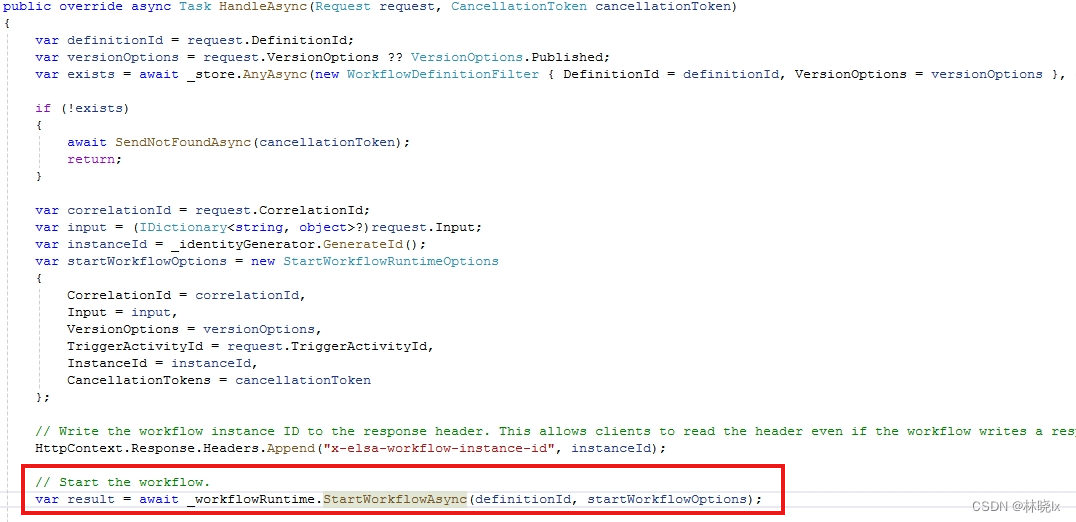

其中RootActivity会反序列化,可以看到StringData会被反序列化为IActivity对象


查看工作流状态
Elsa定义了不同的接口和数据库
主要的接口如下:
workflowDefinition:工作流定义接口,数据来自WorkflowDefinition表
workflowInstance:工作流实例接口,数据来自WorkflowInstance表
activity-execution:活动执行接口,查询活动的Id、状态以及结果,输入输出等上下文数据,数据主要通过查询ActivityExecutionRecords表来获取。
journal: 活动执行日志,数据来自WorkflowExecutionLogRecords表
打开设计器,点击“工作流(Workflow)”菜单,然后单击“实例(Instance)”选项卡。可以看到一个工作实例列表
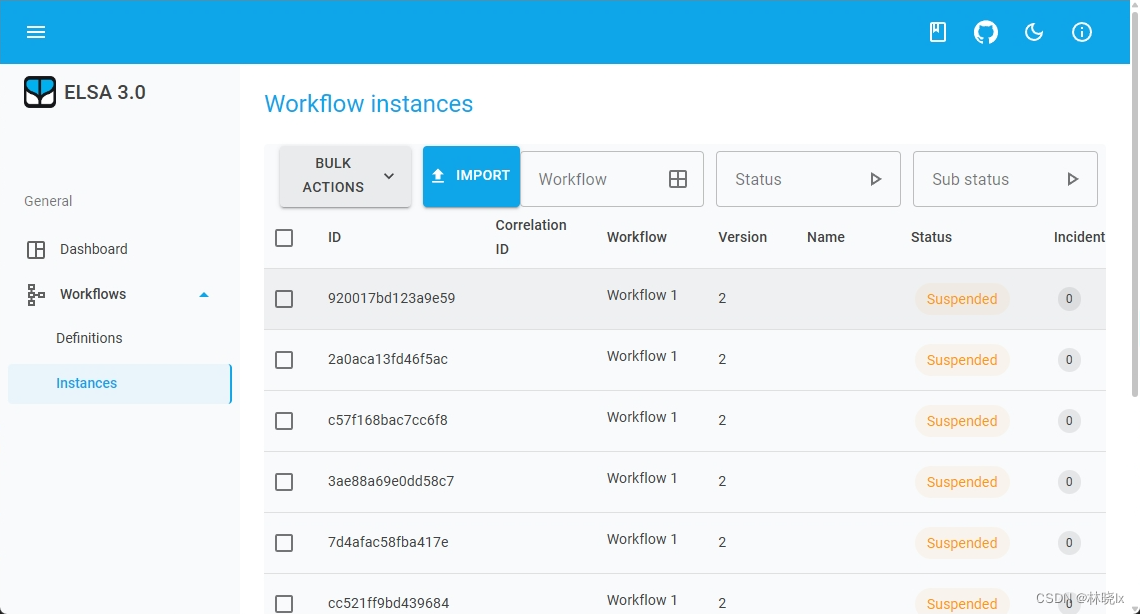
点击条目即可查看工作流的执行日志和各活动的执行信息。Web页面中各片区的数据来源分布大致如下:
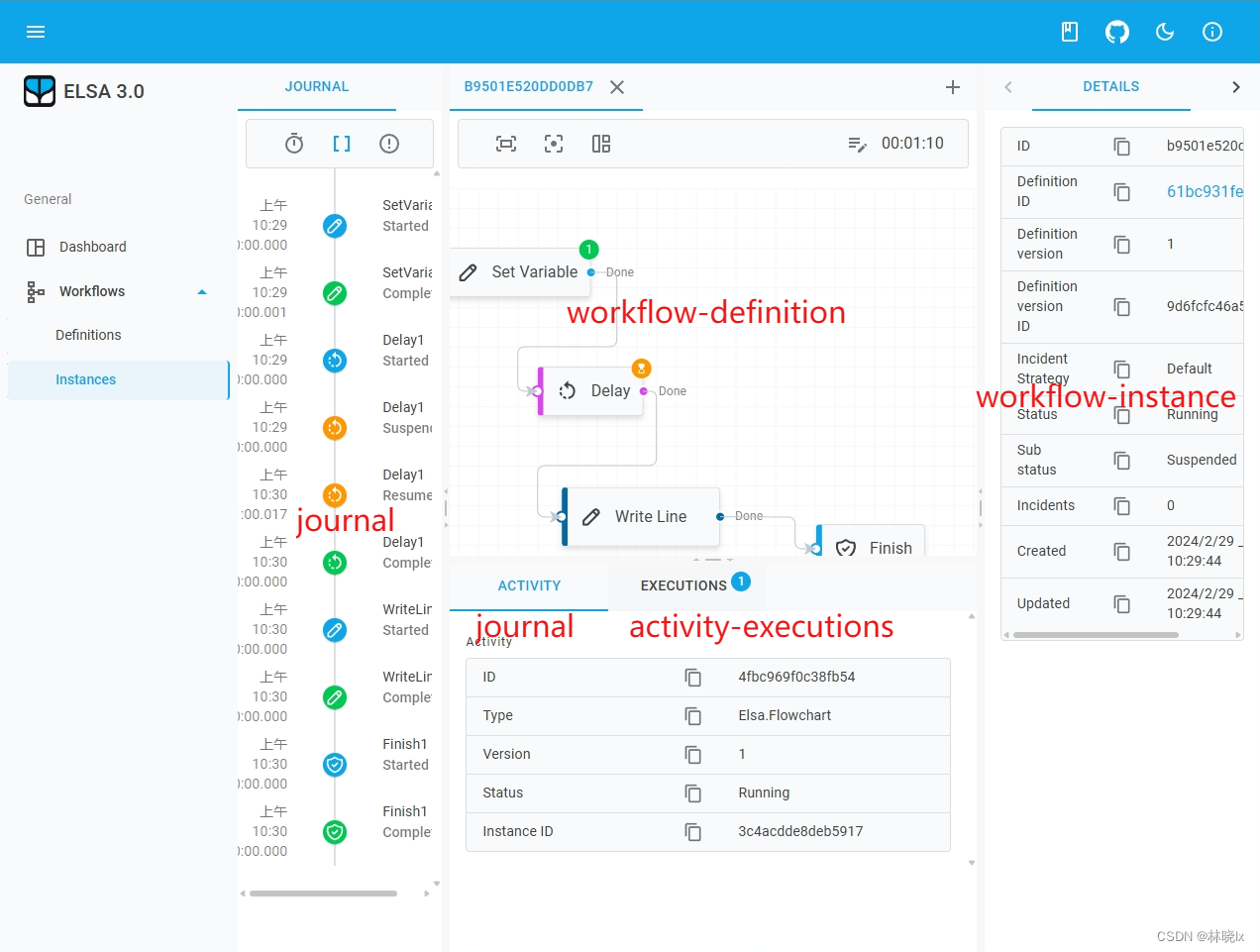
其中页面中央的工作流编辑器显示了工作流的结构,结合工作流的执行日志,可以直观的看到工作流的执行情况。可观测到执行的步骤,以及执行的耗时。
--完结--
[.NET项目实战] Elsa开源工作流组件应用(二):内核解读的更多相关文章
- .NET Core/.NET5/.NET6 开源项目汇总3:工作流组件
系列目录 [已更新最新开发文章,点击查看详细] 开源项目是众多组织与个人分享的组件或项目,作者付出的心血我们是无法体会的,所以首先大家要心存感激.尊重.请严格遵守每个项目的开源协议后再使用.尊 ...
- react 项目实战(四)组件化表单/表单控件 高阶组件
高阶组件:formProvider 高阶组件就是返回组件的组件(函数) 为什么要通过一个组件去返回另一个组件? 使用高阶组件可以在不修改原组件代码的情况下,修改原组件的行为或增强功能. 我们现在已经有 ...
- 小D课堂-SpringBoot 2.x微信支付在线教育网站项目实战_2-5.开源工具的优缺点选择和抽象方法的建议
笔记 5.开源工具的优缺点选择和抽象方法的建议 简介:讲解开源工具的好处和弊端,如pageHeper分页拦截器,tk自动生成工具,抽象方法的利弊等 1.开源工具 好处: ...
- mistral 工作流组件之二 思维导图
Mistral 思维导图
- 简单的物流项目实战,WPF的MVVM设计模式(二)
往Models文件添加一个类,ConnectObject /// <summary> /// 链接数据库字符串 /// </summary ...
- 【Slickflow学习】.NET开源工作流环境搭建(三)
第一次自己写博客文章,大家多多指教.写博客主要记录一下学习的过程,给初学者提供下参考,也留给自己做备忘. Slickflow .NET开源工作流-环境搭建 在VS2010中使用附加进程的方式调试IIS ...
- 16套java架构师,高并发,高可用,高性能,集群,大型分布式电商项目实战视频教程
16套Java架构师,集群,高可用,高可扩展,高性能,高并发,性能优化,设计模式,数据结构,虚拟机,微服务架构,日志分析,工作流,Jvm,Dubbo ,Spring boot,Spring cloud ...
- 小D课堂-SpringBoot 2.x微信支付在线教育网站项目实战_汇总
2018年Spring Boot 2.x整合微信支付在线教育网站高级项目实战视频课程 小D课堂-SpringBoot 2.x微信支付在线教育网站项目实战_1-1.SpringBoot整合微信支付开发在 ...
- 15套java架构师、集群、高可用、高可扩展、高性能、高并发、性能优化、Spring boot、Redis、ActiveMQ、Nginx、Mycat、Netty、Jvm大型分布式项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩展. ...
- 15套java互联网架构师、高并发、集群、负载均衡、高可用、数据库设计、缓存、性能优化、大型分布式 项目实战视频教程
* { font-family: "Microsoft YaHei" !important } h1 { color: #FF0 } 15套java架构师.集群.高可用.高可扩 展 ...
随机推荐
- 轻松玩转Makefile | 企业项目级Makefile实例
前言 本文展示了一个比较完整的企业项目级别的Makefile文件,包括了:文件调用,源文件.头文件.库文件指定,软件版本号.宏定义,编译时间,自动目录等内容. 1.目录架构 本文中所采用的目录架构,在 ...
- TCP与UDP异同
TCP与UDP异同 TCP/IP模型的运输层有两个不同的协议:UDP用户数据报协议与TCP传输控制协议. 相同点 TCP与UDP都是运行在运输层的协议. TCP与UDP的通信都需要开放端口. 不同点 ...
- 《深入理解Java虚拟机》(三)类加载机制
@ 目录 1.什么是类的加载 2.类加载的过程 加载 连接 验证 文件格式验证 元数据验证 字节码验证 符号引用验证 准备 解析: 类或接口的解析 字段解析 类方法解析 接口方法解析 初始化 结束生命 ...
- C++ 多线程的错误和如何避免(9)
有时候使用 std::atomic 比使用 mutexes 更高效 问题分析:使用多线程更新一些简单数据时,比如 int 型,bool 型等等,可以使用 std::atomic,这比 mutex 来得 ...
- 什么是数据同步利器DataX,如何使用?
转载至我的博客 https://www.infrastack.cn ,公众号:架构成长指南 今天给大家分享一个阿里开源的数据同步工具DataX,在Github拥有14.8k的star,非常受欢迎,官网 ...
- 【MongoDB】MongoDB原理分析、集群搭建(Docker)与简单使用
一.MongoDB 简介 MongoDB是一个基于分布式文件存储的数据库,介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的.其目的是为WEB应用提供可扩展的高性能数据存 ...
- 万字长文学会对接 AI 模型:Semantic Kernel 和 Kernel Memory,工良出品,超简单的教程
万字长文学会对接 AI 模型:Semantic Kernel 和 Kernel Memory,工良出品,超简单的教程 目录 万字长文学会对接 AI 模型:Semantic Kernel 和 Kerne ...
- 基于 Nebula Graph 构建百亿关系知识图谱实践
本文首发于 Nebula Graph Community 公众号 一.项目背景 微澜是一款用于查询技术.行业.企业.科研机构.学科及其关系的知识图谱应用,其中包含着百亿级的关系和数十亿级的实体,为了使 ...
- C++ STL 容器-Deque
C++ STL 容器-Deque std::deque(双端队列)是C++标准模板库(STL)中的一个容器,它支持在序列的两端快速插入和删除元素.与std::vector和std::list等其他序列 ...
- 关闭mysql上锁的表/数据
一.输入查询语句,查看是否有数据被上锁 select * from information_schema.innodb_trx; 取 trx_mysql_thread_id 字段值 kill < ...