【python爬虫案例】用python爬豆瓣读书TOP250排行榜!
一、爬虫对象-豆瓣读书TOP250
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣读书TOP250排行榜数据:
https://book.douban.com/top250
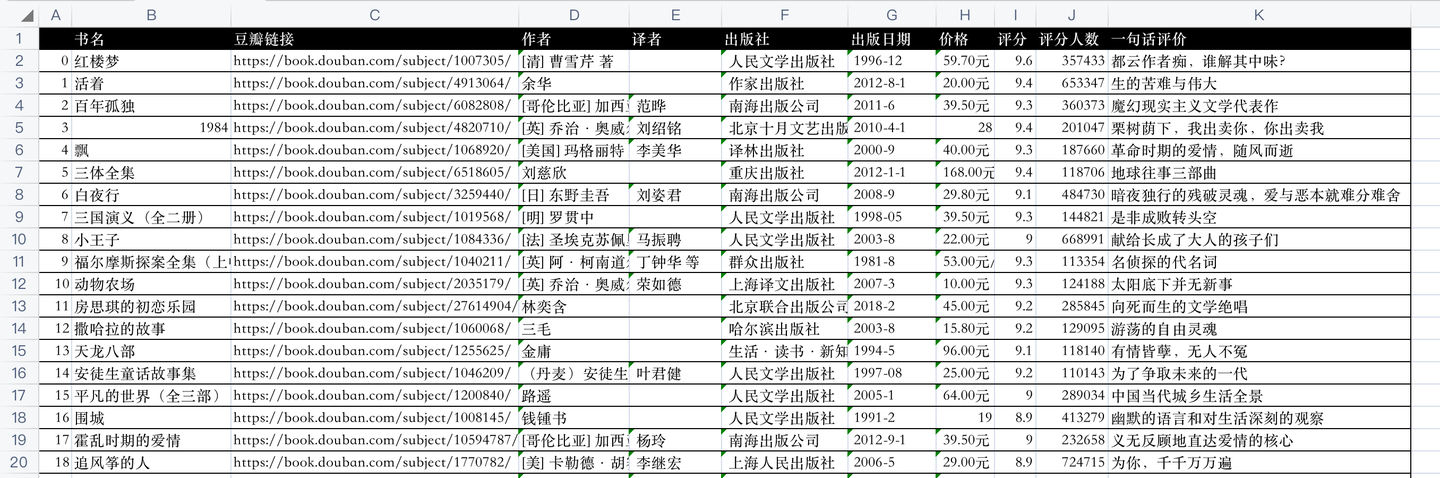
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣读书网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = book.select('.pl2 a')[0]['title'] # 书名
book_name.append(name)
bkurl = book.select('.pl2 a')[0]['href'] # 书籍链接
book_url.append(bkurl)
star = book.select('.rating_nums')[0].text # 书籍评分
book_star.append(star)
star_people = book.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
book_star_people.append(star_people)
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['书名'] = book_name
df['豆瓣链接'] = book_url
df['作者'] = book_author
df['译者'] = book_translater
df['出版社'] = book_publisher
df['出版日期'] = book_pub_year
df['价格'] = book_price
df['评分'] = book_star
df['评分人数'] = book_star_people
df['一句话评价'] = book_comment
df.to_csv(csv_name, encoding='utf8') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
三、讲解视频
同步讲解视频:https://www.zhihu.com/zvideo/1464515550177546240
四、完整源码
附完整源代码:【python爬虫案例】利用python爬虫爬取豆瓣读书TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣读书TOP250排行榜!的更多相关文章
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- 豆瓣读书top250数据爬取与可视化
爬虫–scrapy 题目:根据豆瓣读书top250,根据出版社对书籍数量分类,绘制饼图 搭建环境 import scrapy import numpy as np import pandas as p ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
随机推荐
- verilog基本语法之always和assign
always和assign的作用 一.语法定义 assign,连续赋值.always,敏感赋值.连续赋值,就是无条件全等.敏感赋值,就是有条件相等.assign的对象是wire,always的对象是r ...
- apue 文章集锦
与 apue 相关的一系列文章比较庞杂,按原书目录整理了一下,形成目录,方便系统性阅读. 另外这些文章是在我快读完的时候开始写的,之前的一些章节还多有遗漏,后面慢慢补上. chapter 1: UNI ...
- html中怎样获取子元素的索引位置
jQuery 的 index() 方法返回指定元素相对于其他指定元素的索引值, 注意:索引值是从0开始计数的. 获得当前元素的索引值可用click事件触发 1 $(selector).click(fu ...
- 机器语言编写helloworld
kvmtool下载编译 git clone https://github.com/kvmtool/kvmtool.git 下载后进入到目录执行make即可. 补码 计算机怎么表示负数?以四位有符号数为 ...
- Linux是什么与如何学习
重点回顾 操作系统(Operation System) 主要在管理与驱动硬件,因此必须要能够管理内存.管理装置. 负责行程管理以及系统呼叫等等.因此,只要能够让硬件准备妥当(Ready)的情况, 就是 ...
- 提高生产力!这10个Lambda表达式必须掌握,开发效率嘎嘎上升!
在Java8及更高版本中,Lambda表达式的引入极大地提升了编程的简洁性和效率.本文将围绕十个关键场景,展示Lambda如何助力提升开发效率,让代码更加精炼且易于理解. 集合遍历 传统的for-ea ...
- 8 JavaScript函数
8 JavaScript函数 在JS中声明函数和python差不多. 也要有一个关键字顶在前面. python是def, 到了JS里换成了function, 只不过在JS中没有像python那么死板, ...
- 看你能解锁哪些新身份?OpenHarmony大使、MVP、金码达人在线申报
- OpenHarmony页面级UI状态存储:LocalStorage
LocalStorage是页面级的UI状态存储,通过@Entry装饰器接收的参数可以在页面内共享同一个LocalStorage实例.LocalStorage也可以在UIAbility内,页面间共享 ...
- 直播回顾 | 点击率提升400%,Ta是怎么做到的?
Discovery第18期直播已于3月30日圆满结束,本期直播邀请天眼查做客直播间,从天眼查与华为Push用户增长服务合作历程切入,聚焦用户增长,分享提升应用活跃度和渠道ROI的经验与见解.一起来回顾 ...