数据结构—包(Bag)
数据结构中的包,其实是对现实中的包的一种抽象。 想像一下现实中的包,比如书包,它能做什么?有哪些功能?首先它用来装东西,里面的东西可以随便放,没有规律,没有顺序,当然,可以放多个相同的东西。其次,东西可以拿出来,拿出来也有几种情况,随便拿出一个,拿出特定的一个,比如书本,把所有的东西都拿出来。附带的功能就是,包有没有满,包是不是空的,里面有多少东西,都是什么,里面是不是有书,放了几本书之类的。想好之后,就可以定义数据结构中的包的方法了。
装东西,定义add()方法,要接受一个参数,要装的东西,没有返回值。
随便拿出一个东西,定义remove()方法, 没有参数,返回拿出的东西。
拿出一个特定的东西,定义remove(anEntry), 接收一个参数,要拿出的东西,返回值是布尔值,表示有没有成功,因为要拿出的东西,包里可能没有
拿出所有东西,定义clear()方法,没有参数,也没有返回值。
包里有多少东西,定义getCurrentSize()方法,返回包中元素的个数,没有参数。
包是不是空的,定义isEmpty()方法,没有参数,返回布尔值。
包里有没有书,定义contains()方法,它接受一个参数,要找的东西,返回布尔值。
包里有几本书,定义getFrequencyOf()方法,接受一个参数,要找的东西,返回整数。
包里都是什么,可以定义toArray()方法,返回一个数组,包含包里所有的东西,也是定义迭代方法。
/**
* 一个用来描述包的操作的接口
*/
public interface BagInterface<T> {
/**
* 获取包中元素的数量
*
* @return 元素数量
*/
int getCurrentSize(); /**
* 包是否为空
*
* @return 包为空,返回true, 否则返回false
*/
boolean isEmpty(); /**
* 向包里添加一个元素
*
* @param newEntry 要添加到包里的元素
*/
void add(T newEntry); /**
* 从包里删除任意一个元素
* @return 删除的元素
*/
T remove(); /**
* 从包里删除一个给定的元素
* @param anEntry 要删除的元素
* @return 是否删除成功
*/
boolean remove(T anEntry); /**
* 删除包中所有元素
*/
public void clear(); /**
* 计算一个给定元素的数量
* @param anEntry 给定的元素
* @return 给定元素的数量
*/
public int getFrequencyOf(T anEntry); /**
* 是否包含给定的元素
* @param anEntry 要查找的元素
* @return 如查包含返回true, 否则返回false
*/
public boolean contains(T anEntry); /**
* 获取包中所有的元素,
* @return 包含包中所有元素新数组。
* 注意,如果包为空,返回空数组
*/ T[] toArray();
}
使用数组实现bag --- 创建ArrayBag<T>类来实现BagInterface<T>
首先考虑类的属性。既然决定用数组实现的,属性中肯定有一个数组的引用。除此之外,还要有个属性记录包中元素的个数,因为要判断包是否为空等。
private T[] bag;
private int numberOfEntries;
private static final int DEFAULT_CAPACITY = 25;
构造函数,初始化包。首先要创建数组对象,赋值给bag属性,因为属性中的bag只是一个数组的引用,并没有真正地创建数组。在Java中,创建数组需要指定长度。数组的长度。既也可以让使用者来决定,也可以提供一个默认容量,因此提供无参和有参两个构造函数。其次,初始化时,包中并没有元素,numberOfEntries初始化为0. 但怎么创建数组呢?假设构造函数接收一个参数capacity, bag = new T[capacity]; 不行。bag = new Object[capacity]; 还是不行。bag = (T[])new Object[capacity]; 倒是没有报错,但有warning(unchecked cast). 编译器想让你确保数组中的每一个元素从Object类强制转化成泛型T是安全的,由于数组刚刚创建,每一个元素都是null,因此转化是安全的,我们可以使用@SuppressWarnings("unchecked")告诉编译器忽略这个warning。@SuppressWarnings("unchecked")只能出现在方法定义或变量声明之前,由于bag = (T[])new Object[capacity]; 是赋值操作,不是变量声明,因为bag已经声明了,最终创建数组如下
// 强制类型转化是安全的,因为新数组中所有元素都是null
@SuppressWarnings("unchecked")
T[] tempBag = (T[])new Object[capacity]; // Unchecked cast
bag = tempBag;
整个构造函数如下
/**
* 创建一个空bag,初始空量为用户指定容量
* @param capacity 指定容量
*/
public ArrayBag(int capacity) {
// 强制类型转化是安全的,因为新数组中所有元素都是null
@SuppressWarnings("unchecked")
T[] tempBag = (T[]) new Object[capacity]; // Unchecked cast
bag = tempBag;
numberOfEntries = 0;
} /**
* 创建一个空bag,初始空量为默认容量25
*/
public ArrayBag() {
this(DEFAULT_CAPACITY);
}
先实现add()方法,只有添加了元素,其它方法才好实现或测试。添加元素时,如果数组满了,肯定不能添加了,需要扩容(增加容量),再添加。如果数组没有满,就可以继续添加。扩容后面再说,先看数组没有满的情况。添加元素,就是把要添加的元素直接放到数组中最后一个元素的后面,元素个数加1。刚开始时,数组为空,numberOfEntries为0,数组中没有元素,直接在0位置放置新元素,然后numberOfEntries + 1。再添加一个元素,那就要放到1的位置,numberOfEntries+1。再添加一个元素,那就要放到2的位置,numberOfEntries+1。

你会发现,新元素的放置位置就是bag[numberOfEntries]的位置,add()方法就是
public void add(T newEntry) {
if(isArrayFull()){
} else {
bag[numberOfEntries] = newEntry;
numberOfEntries++;
}
}
isArrayFull()就是判断数组是不是满了,只要元素的个数等于数组的长度就是满了
private boolean isArrayFull() {
return numberOfEntries == bag.length;
}
添加方法实现完了,就要看看实现的对不对,添加的元素有没有添加成功。这就是ToArray() 方法了,创建一个新数组,把bag中的元素复制过去,然后把新数组返回
public T[] toArray() {
@SuppressWarnings("unchecked")
T[] result = (T[])new Object[numberOfEntries]; // Unchecked cast
for (int index = 0; index < numberOfEntries; index++)
{
result[index] = bag[index];
}
return result;
}
添加和查看成功后,就要实现其它方法了。先从简单的开始,isEmpty(),包是否为空,直接判断numberOfEntries是否等于0就可以了。 getCurrentSize(), 包中元素的个数,直接返回numberofEntries。
public boolean isEmpty() {
return numberOfEntries == 0;
}
public int getCurrentSize() {
return numberOfEntries;
}
getFrequencyOf(T anEntry),一个元素在包中出现的次数。循环遍历数组就可以了,在遍历过程中,只要有元素和要查找的元素相等,计数器加1。遍历完成后,返回计数器。
public int getFrequencyOf(T anEntry) {
int count = 0;
for (int i = 0; i < numberOfEntries; i++) {
if(anEntry.equals(bag[i])){
count++;
}
}
return count;
}
contains()方法,包中是否包含某个元素,还是循环遍历数组,只不过是返回true或false。可以先设一个表示找到找不到的变量found,默认是false,只有当fasle的时候,才遍历数组,在遍历过程中,如果找到了,设为true。如果遍历完,还没有找到,那还是false,直接返回found就可以了。
public boolean contains(T anEntry) {
boolean found = false;
int index = 0;
while (!found && index < numberOfEntries){
if (anEntry.equals(bag[index])){
found = true;
}
index++;
}
return found;
}
clear()方法,清空bag,简单一点的实现,就是numberOfEntries = 0;,复杂一点就是包不为空的时候,循环调用remove()方法
public void clear() {
// numberOfEntries = 0;
while (!isEmpty()){
remove();
}
}
remove() 方法,删除任意一个元素,由于包中的元素没有顺序要求,可以随便删除,简单起见,就删除最后一个元素,当然,如果包为空的话,是不允许删除的,可以抛出错误。
public T remove() {
if (isEmpty()) {
throw new RuntimeException("空");
}
T result = bag[numberOfEntries - 1];
bag[numberOfEntries - 1] = null;
numberOfEntries--;
return result;
}
remove(anEntry),删除一个给定的元素,首先要先查找这个元素,如果包中没有这个元素,也就没有办法删除,直接return false就好了。如果找到了,再想办法删除。查找,用的是循环遍历,找到了,也就是找到了这个元素所在的位置。
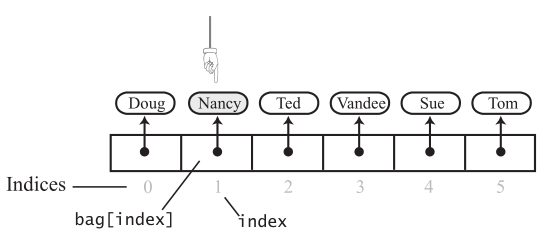
怎么删除呢?最先想到的是把后面的元素向前移,因为数组是连续的。
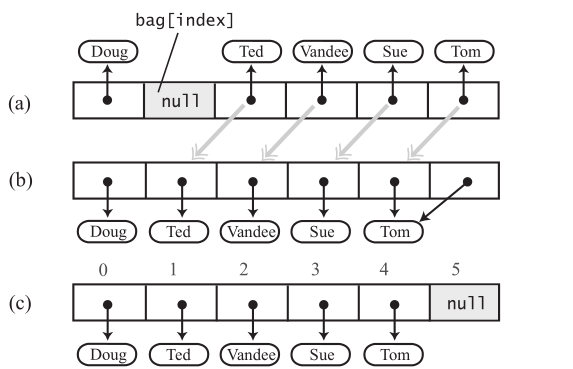
有点复杂。因为bag中的元素,并没有规定顺序,也就没有必要前移。可以让要删除的元素和最后一个元素,进行交换,直接删除最后一个元素就好了。
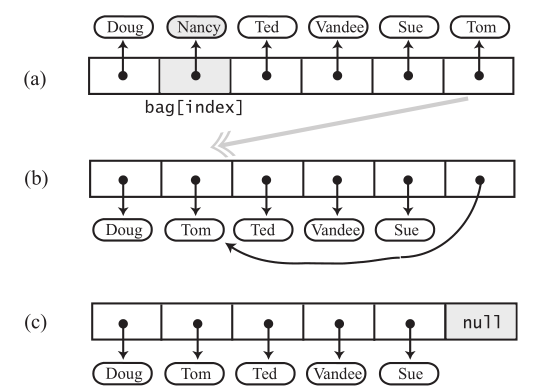
public boolean remove(T anEntry) {
if(isEmpty()){
throw new RuntimeException("空");
}
boolean found = false;
int index = 0;
while (!found && index < numberOfEntries){
if (anEntry.equals(bag[index])){
found = true;
} else {
index++;
}
}
if(found){
bag[index] = bag[numberOfEntries - 1];
bag[numberOfEntries - 1] = null;
numberOfEntries--;
return true;
} else {
return false;
}
}
remove()和remove(T anEntry)代码有了重复,实现上remove() 就是remove(numberOfEntry-1), 这时可以写一个私有方法,删除给定index处的元素,它接受一个index参数,返回要删除的元素
private T removeEntry(int givenIndex){
if(isEmpty()){
throw new RuntimeException("空");
}
T result = bag[givenIndex];
bag[givenIndex] = bag[numberOfEntries - 1];
bag[numberOfEntries - 1] = null;
numberOfEntries--;
return result;
}
remove()方法简化成
public T remove() {
return removeEntry(numberOfEntries - 1);
}
再看remove(T anEntry), 里面查找定位元素的代码和contains()方法,也是重复的,也可以写一个私有方法getIndexOf来返回index。
private int getIndexOf(T anEntry)
{
int where = -1;
boolean found = false;
int index = 0;
while (!found && (index < numberOfEntries))
{
if (anEntry.equals(bag[index]))
{
found = true;
where = index;
}
index++;
}
return where;
}
contains()方法就变成了
public boolean contains(T anEntry) {
return getIndexOf(anEntry) > -1;
}
remove(T anEntry)变成了
public boolean remove(T anEntry) {
int index = getIndexOf(anEntry);
if(index > -1){
removeEntry(index);
return true;
} else {
return false;
}
}
数组扩容的基本原理:假设有一个数组myArray,先让它赋值一个临时变量oldArray, 再创建一个新数组赋值给myArray, 最后把oldArray中的每一个元素都复制到myArray中。
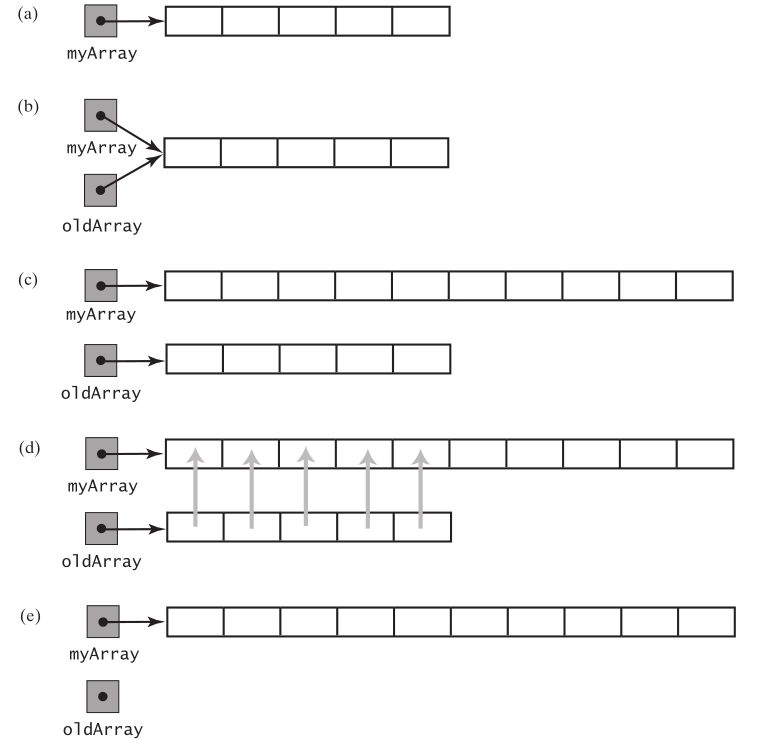
扩容要注意是新生成的数组的大小。如果太小,就要经常扩容,也就是经常把元素从一个数组复制到另一个数组,浪费性能。通常来说,新的数组长度是旧的数组的2倍。比如有50个元素,添加51个元素的时候,扩容到100,剩下的49个元素添加,就不用扩容,抵消掉这个扩容的成本。expanding the array by m elements spreads the copying cost over m additions instead of just one. Doubling the size of an array each time it becomes full is a typical approach. When increasing the size of an array, you copy its entries to a larger array. You should expand the array sufficiently to reduce the impact of the cost of copying. A common practice is to double the size of the array.
private void resize(int newLength) {
@SuppressWarnings("unchecked")
T[] newArray = (T[]) new Object[newLength]; // Unchecked cast
for (int index = 0; index < numberOfEntries; index++) {
newArray[index] = bag[index];
}
bag = newArray;
}
add()方法变成了
public void add(T newEntry) {
if (isArrayFull()) {
resize(2 * bag.length);
}
bag[numberOfEntries] = newEntry;
numberOfEntries++;
}
remove方法需要缩容(减少容量),如果把所有元素都删除了,剩下那么大空间也不合适。缩容和扩容的原理相似,只不过是创建的新数组比原数组要小。缩容的时机是,当删除的元素时,数组元素的个数是数组长度的1/4时,缩小一半的容量。removeEntry() 方法改成
private T removeEntry(int givenIndex){
if(isEmpty()){
throw new RuntimeException("空");
}
T result = bag[givenIndex];
bag[givenIndex] = bag[numberOfEntries - 1];
bag[numberOfEntries - 1] = null;
numberOfEntries--;
if(numberOfEntries > 0 && numberOfEntries == bag.length / 4){
resize(bag.length / 2);
}
return result;
}
使用链表实现bag --- 创建LinkedListBag<T>类来实现BagInterface<T>
还是先考虑类的属性。链表是由节点组成,节点中的数据域可以存放包中的元素
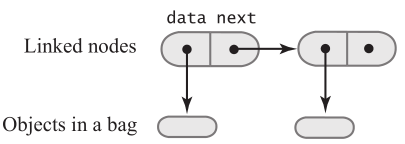
需要创建一个私有内部类Node
private class Node {
T data;
Node next;
Node(T dataPortion) {
data = dataPortion;
next = null;
}
}
操作链表需要头指针,它指向链表中的第一个节点,还需要一个变量来记录包中元素的个数。
private Node firstNode;
private int numberOfEntries;
add(T newEntry) 方法,既然包中的元素没有顺序,而在链表的头部插入节点,又比较简单,那add(T newEntry) 就定义为从头部插入节点。刚开始,链表为空,插入节点,就是创建新节点,并赋值给头指针

Node newNode = new Node(newEntry);
firstNode = newNode;
当链表不为空时,头部插入节点,就是,创建新节点,新节点的next指向链表中的第一个节点(firstNode),再让新节点成为链表中的第一个节点(新节点赋值给firstNode)
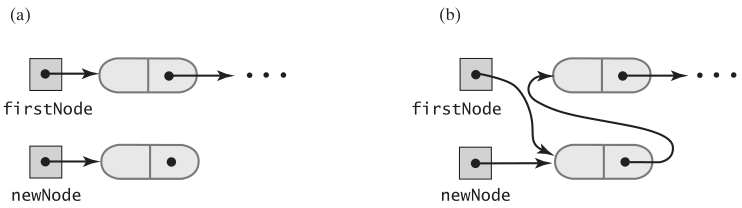
Node newNode = new Node(newEntry);
newNode.next = firstNode;
firstNode = newNode; // New node is at beginning of chain
实际上,向一个空链表中插入节点,和向一个非空链表头部插入节点是一样的。向空链表中插入节点时,如果加入newNode.next = firstNode,也没有问题,因为此时firstNode为null,而newNode的next本来也是null。所以add()方法的完整实现
public void add(T newEntry) {
Node newNode = new Node(newEntry);
newNode.next = firstNode;
firstNode = newNode;
numberOfEntries++;
}
toArray()方法,需要遍历链表,把链表中的每一个节点中的数据放到数组中。怎么遍历呢?firstNode指向链表中的第一个节点,第一个节点又包含第二个节点的引用,第二个节点又包含第三个节点的引用,因此需要一个变量来顺序地引用每一节点,到达每一个节点时, .data就可以获取节点中的数据。刚开始的时候,变量引用第一个节点,把firstNode赋值给这个变量,假设变量是currrentNode, 那么currentNode = firstNode. currentNode.data就可以获取到数据。currentNode= currentNode.next, currentNode指向第二个节点,currentNode.data获取数据。currentNode = currentNode.next,第三个节点,一直到最后一个节点currentNode为null。
public T[] toArray() {
@SuppressWarnings("unchecked")
T[] array = (T[]) new Object[numberOfEntries];
Node current = firstNode;
int index = 0;
while (current != null){
array[index] = current.data;
index++;
current = current.next;
}
return array;
}
getFrequencyOf(), 像toArray()一样,遍历链表,只不过获取到数据后,要做的是判断是否相等。
public int getFrequencyOf(T anEntry)
{
int frequency = 0;
Node currentNode = firstNode;
while (currentNode != null)
{
if (anEntry.equals(currentNode.data))
frequency++;
currentNode = currentNode.next;
}
return frequency;
}
contains() 还是遍历链表
public boolean contains(T anEntry){
boolean found = false;
Node currentNode = firstNode;
while (!found && (currentNode != null))
{
if (anEntry.equals(currentNode.data))
found = true;
else
currentNode = currentNode.next;
}
return found;
}
remove(), 因为包中的元素顺序没有要求,所以删除第一个元素就好了,简单
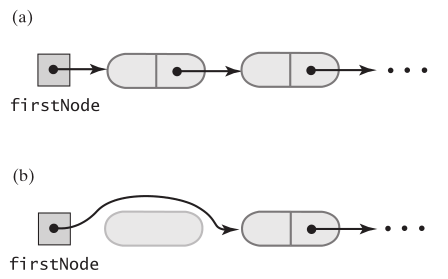
public T remove()
{
T result = null;
if (firstNode != null)
{
result = firstNode.data;
firstNode = firstNode.next;
numberOfEntries--;
}
return result;
}
remove(T anEntry), 遍历链表,找到元素,然后和第一个节点进行交换,删除第一个节点
private Node getReferenceTo(T anEntry)
{
boolean found = false;
Node currentNode = firstNode;
while (!found && (currentNode != null))
{
if (anEntry.equals(currentNode.data))
found = true;
else
currentNode = currentNode.next;
}
return currentNode;
} public boolean remove(T anEntry)
{
boolean result = false;
Node nodeN = getReferenceTo(anEntry);
if (nodeN != null)
{
nodeN.data = firstNode.data;
firstNode = firstNode.next;
numberOfEntries--;
result = true;
}
return result;
}
clear()方法,直接让firstNode = null就好了
public void clear()
{
firstNode = null;
}
迭代方法,就要实现Iterable<T>接口,实现Iterable<T>接口,就要提供一个iterator方法,这个方法要返回Iterator<T>接口类型的对象,有对象就要创建一个类来这个Iterator<T>接口,它有两个方法,一个是hasNext(),表示,还有迭代对象中还没有元素,next()方法,返回每一次迭代的元素。
import java.util.Iterator;
public class LinkedListBag<T> implements BagInterface<T>, Iterable<T> {
public Iterator<T> iterator() {
return new ListIterator();
}
private class ListIterator implements Iterator<T> {
private Node current = firstNode;
public boolean hasNext() {
return current != null;
}
public T next() {
T item = current.data;
current = current.next;
return item;
}
}
}
数据结构—包(Bag)的更多相关文章
- Lua数据结构
lua中的table不是一种简单的数据结构,它可以作为其他数据结构的基础,如:数组,记录,链表,队列等都可以用它来表示. 1.数组 在lua中,table的索引可以有很多种表示方式.如果用整数来表示t ...
- Lua中使用table实现的其它5种数据结构
Lua中使用table实现的其它5种数据结构 lua中的table不是一种简单的数据结构,它可以作为其他数据结构的基础,如:数组,记录,链表,队列等都可以用它来表示. 1.数组 在lua中,table ...
- Step By Step(Lua数据结构)
Step By Step(Lua数据结构) Lua中的table不是一种简单的数据结构,它可以作为其它数据结构的基础.如数组.记录.线性表.队列和集合等,在Lua中都可以通过table来表示. ...
- 通过Bag一对多映射示例(使用xml文件)
如果持久化类具有包含实体引用的列表对象,则需要使用一对多关联来映射列表元素. 我们可以通过列表(list)或包(bag)来映射这个列表对象. 请注意,bag不是基于索引的,而list是基于索引的. 在 ...
- 集合映射中的映射包(使用xml文件)
如果持久类有List对象,我们可以通过列表或者bag元素在映射文件中映射. 这个包(bag)就像List一样,但它不需要索引元素. 在这里,我们使用论坛的场景: 论坛中一个问题有多个答案. 我们来看看 ...
- Pig Latin程序设计1
Pig是一个大规模数据分析平台.Pig的基础结构层包括一个产生MapReduce程序的编译器.在编译器中,大规模并行执行依据存在.Pig的语言包括一个叫Pig Latin的文本语言,此语言有如下特性: ...
- Python 3标准库课件第二章
整理第一章我又觉得烦,我就看第二章了,灰头土脸的,第二章一.如列表(list).元组(tuple).字典(dict).集合(set)二.2.1 enum:枚举类型 enum模块定义了一个提供迭代和比较 ...
- Commons-Collections 集合工具类的使用
package com.bjsxt.others.commons; import java.util.ArrayList; import java.util.List; import org.apac ...
- Commons-Collections
package com.bjsxt.others.commons; import java.util.ArrayList; import java.util.List; import org.apac ...
- java11 Guava:谷歌开发的集合库
Guava:谷歌开发的集合库,通过build path->Add External JARs 把guava.jar包加进去. 版本控制工具:.CVS .SVN .git 所以需要下载git客户端 ...
随机推荐
- ETSI GS MEC 013,UE 位置 API
目录 文章目录 目录 版本 功能理解 Relation with OMA APIs Relation with OMA API for Zonal Presence Relation with OMA ...
- Pytorch:以单通道(灰度图)加载图片
以单通道(灰度图)加载图片 如果我们想以单通道加载图片,设置加载数据集时的transform参数如下即可: from torchvision import datasets, transforms t ...
- Android 12(S) MultiMedia Learning(一)开篇
这个系列将会作为自己学习android多媒体的笔记,如果有错误请帮忙指正. 本系列的学习均基于Android 12(S),代码来源:http://aospxref.com/
- Flutter(九)Json序列化与反序列化(转Model)
在日常开发中JSON的序列化与反序列化是一个常见的操作:而Dart语言不支持反射,运行时反射会影响Dart的tree shaking(摇树优化),tree shaking可以"抖掉" ...
- Rainbond 5.5 发布,支持Istio和扩展第三方Service Mesh框架
Rainbond 5.5 版本主要优化扩展性.服务治理模式可以扩展第三方 ServiceMesh 架构,兼容kubernetes 管理命令和第三方管理平台. 主要功能点解读: 1. 支持 Istio, ...
- C#中接口的显式实现与隐式实现及其相关应用案例
C#中接口的显式实现与隐式实现 最近在学习演化一款游戏项目框架时候,框架作者巧妙使用接口中方法的显式实现来变相对接口中方法进行"密封",增加实现接口的类访问方法的"成本& ...
- [brief]虚拟机安装UbuntuServer
1.下载Ubuntu--Server镜像官网点击 2.Vmware15.x配置 2G /boot 4G swap(一倍或两倍于分配内存量) rest / or /+/home 3.terminal下安 ...
- NOIP模拟62
T1 Set 解题思路 抽屉原理 发现对于前缀和向 \(n\) 取模之后一定是右两个值相等的(包括什么都不选的 0 ). 假设 \(pre_j=pre_i\) 那么 \([j+1,i]\) 之间这一段 ...
- 8.24考试总结(NOIP模拟47)[Prime·Sequence·Omeed]
时间带着明显的恶意,缓缓在我的头顶流逝. T1 Prime 解题思路 成功没有签上到... 一看数据范围 \(R-L+1\le 10^7,R\le 10^{14}\) ,这肯定是判断范围内的数字是否可 ...
- k8s——deployment
创建deployment [root@master deploy]# kubectl create deploy nginx-deploy --image=nginx:1.7.9 deployment ...