典型性相关分析在SPSS中的实现
典型性相关分析是研究两组变量(每组变量中都可能有多个指标)之间相关关系的一种多元统计方法。它能够揭示出两组变量之间的内在联系。
本文着重模型在spss中的应用,通过一道例题解释各个指标的意义。详细推导过程请选修课程《多元统计分析》
一、问题提出
直接对这些变量的相关进行两两分析,很难得到关于这两组变量之间关系的一个清楚的印象。
因此我们需要把多个变量与多个变量之间的相关化为两个具有代表性的变量之间的相关。此时用到我们的典型性相关分析模型
二、利用SPSS进行典型相关分析
三、对软件导出的结果进行分析
1.文件导出
由于spss翻译的问题,软件上直接得到的结果并不能很好地让我们理解,因此我们可以选择将结果导出为word,修改一下翻译
具体修改的地方会在接下来的介绍中逐一揭示,标志为黄色强调
2.典型相关系数
在典型性相关分析中,每个一级指标下面有多个二级指标。我们只想对一级指标进行分析,但是一级指标是由二级指标进行决定的,那么要如何处理二级指标呢?
答案是用二级指标对一级指标进行线性组合,即X=ax1+bx2+cx3+.....;
这种线性组合有无数种,因此我们需要进行约束,约束条件即为其相关系数达到最大,最后得到了三组线性组合

在第一组线性组合中,在α=0.1下,其是显著的,并且相关系数为0.796;说明在第一组线性组合下,两个一级指标之间有相关性
而第二组和第三组线性组合没有统计学意义
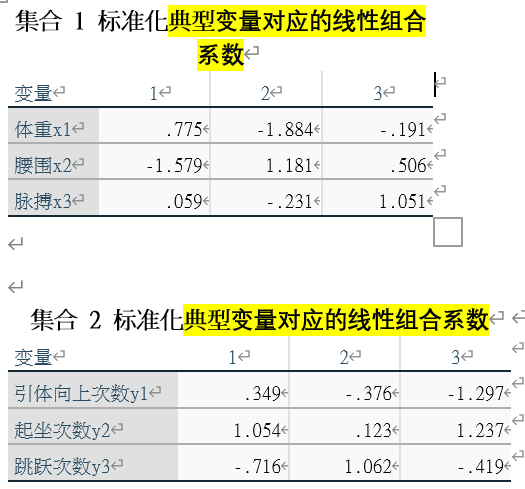
3.典型变量对应的线性组合系数
如图所示,我们可以得到三种线性组合的线性组合系数,即a1 a2 a3的值;但第二种和第三种没有通过假设检验,没有统计学意义
同时,我们倾向于关注标准化后的线性组合系数,因为其去除了量纲的影响
4.典型载荷分析
典型载荷分析可以得出二级指标对一级指标影响程度的大小。
影响程度的大小不是看线性组合系数,而是看典型载荷分析的值,因为线性组合系数是考虑了其他的二级指标而得到的
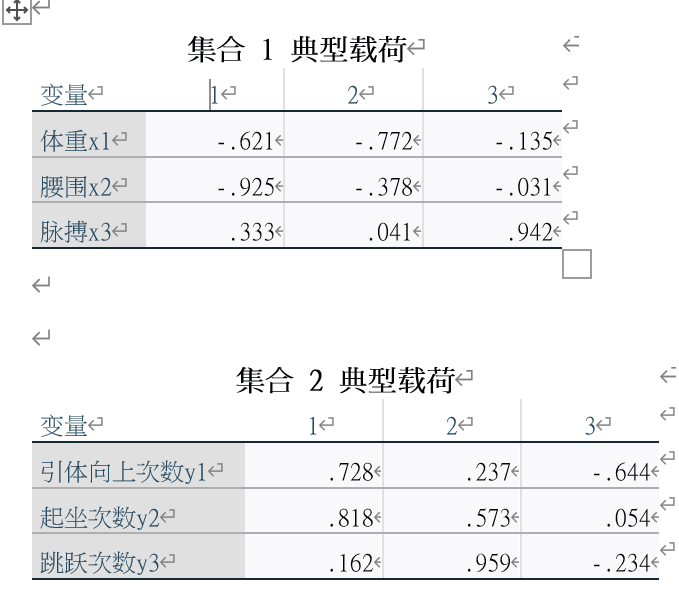
典型载荷的系数越大,二级指标对一级指标的影响就越大
5.典型冗余分析
典型冗余分析用来分析一组线性组合对数据的解释程度,用百分比来表示

因为只有第一组线性组合有统计学意义,因此我们只需要看第一组的解释比例即可
其中对变量一自身的为0.451;其中对变量二自身的为0.408;
如果两组都显著,那么可解释比例即为0.451+0.247
交叉的一般不看
典型性相关分析在SPSS中的实现的更多相关文章
- SPSS中两种重复测量资料分析过程的比较
在SPSS中,有两个过程可以对重复测量资料进行分析:一种是一般线性模型的重复度量:一种是混合线性模型,对于同样的数据资料,使用两种过程分析出的内容不大一样,注意是内容而不是结果,只要操作正确,结果应该 ...
- SPSS中变量的度量标准
在SPSS中,每一个变量都有一个度量标准,这些度量标准说明变量的含义和属性,会对后续的分析产生影响. 1.名义:名义表示定类变量,定类变量表示事物的类别,只能计算频数和频率,各类别之间没有大小.顺序. ...
- spss中如何处理极端值、错误值
spss中如何处理极端值.错误值 spss中录入数据以后,第一步不是去分析数据,而是要检验数据是不是有录入错误的,是不是有不合常理的数据,今天我们要做一个描述性统计,进而查看哪些数据是不合理的.下面是 ...
- pearson相关分析在R中的实现
三个相关性函数: cor():R自带的,输入数据可以是vector,matrix,data.frame,输出两两的相关系数R值 cor.test():R自带的,输入数据只能是两个vector,输出两个 ...
- SPSS数据分析—相关分析
相关系数是衡量变量之间相关程度的度量,也是很多分析的中的当中环节,SPSS做相关分析比较简单,主要是区别如何使用这些相关系数,如果不想定量的分析相关性的话,直接观察散点图也可以. 相关系数有一些需要注 ...
- SPSS统计分析过程包括描述性统计、均值比较、一般线性模型、相关分析、回归分析、对数线性模型、聚类分析、数据简化、生存分析、时间序列分析、多重响应等几大类
https://www.zhihu.com/topic/19582125/top-answershttps://wenku.baidu.com/search?word=spss&ie=utf- ...
- SPSS输出结果如何在word中设置小数点前面显示加0
SPSS输出结果如何在word中设置小数点前面显示加0 在用统计分析软件做SPSS分析时,其输出的结果中,如果是小于1(绝对值)的数,那么会默认输出不带小数点的数值.例如0.362和 -0.141被显 ...
- SPSS数据分析—信度分析
测量最常用的是使用问卷调查.信度分析主要就是分析问卷测量结果的稳定性,如果多次重复测量的结果都很接近,就可以认为测量的信度是高的.与信度相对应的概念是效度,效度是指测量值和真实值的接近程度.二者的区别 ...
- SPSS数据分析—卡方检验
t检验和方差分析主要针对于连续变量,秩和检验主要针对有序分类变量,而卡方检验主要针对无序分类变量(也可以用于连续变量,但需要做离散化处理),用途同样非常广泛,基于卡方统计量也衍生出来很多统计方法. 卡 ...
- SPSS简单使用
当我们的调查问卷在把调查数据拿回来后,我们该做的工作就是用相关的统计软件进行处理,在此,我们以spss为处理软件,来简要说明一下问卷的处理过程,它的过程大致可分为四个过程:定义变量.数据录入.统计分析 ...
随机推荐
- Golang重复Rails Devise gem密码加密
https://github.com/haimait/go-devise-encryptor package main import ( "fmt" //devisecrypto ...
- Golang 之 casbin(权限管理)
目录 1. 权限管理 官网 编辑器测试 1.1.1. 特征 Casbin的作用 Casbin不执行的操作 1.1.2. 怎么运行的 1.1.3. 安装 1. 示例代码 xormadapter 2. 示 ...
- 批量删除WordPress文章和页面的数据库命令和从后台直接删除
批量删除wordpress的方法有两种:1.从wp后台可以调整展示:最多999条 2.选择"Bulk"--"Apply" 通过批量删除wordpress文章和页 ...
- 在jeecg-boot中密码的使用
1.生成密码并入库保存 String id= SnowflakeIdUtil.nextValue();//生成id operatCompany.setId(id); String salt = oCo ...
- 2020版IDEA配置Tomcat 10出现卡主问题
问题描述 配置了2020版的IDE和Tomcat,但是产生了,日志打印中途,卡住了的问题,如图: 18-Aug-2021 00:46:09.763 信息 [main] org.apache.catal ...
- PAT 练习2-3 输出倒三角图案
结果: 本题要求编写程序,输出指定的由"*"组成的倒三角图案. 输入格式: 本题目没有输入. 输出格式: 按照下列格式输出由"*"组成的倒三角图案. 一般都用的 ...
- 通过 Wireshark 解密 Kerberos 票据
前言 在使用 Wireshark 分析 Active Directory 的 Kerberos 的流量时,会遇到加密票据的情况,这对进一步探究 AD 下的漏洞篡改事件的详细过程造成了影响.在查询资料时 ...
- 5款超好用的AI换脸软件,一键视频直播换脸(附下载链接)
随着AIGC的火爆,AI换脸技术也被广泛应用于娱乐.广告.电影制作等领域,本期文章系统介绍了市面上超火的5款AI软件 换脸整合包收录了全部5款AI工具,请按照需要选择下载: 百度网盘:https:// ...
- aspnetcore插件开发dll热加载 二
这一篇文章应该是个总结. 投简历的时候是不是有人问我有没有abp的开发经历,汗颜! 在各位大神的尝试及自己的总结下,还是实现了业务和主机服务分离,通过dll动态的加载卸载,控制器动态的删除添加. 项目 ...
- ReplayKit2 有线投屏项目-反向Socket实现
一.需求 我们在使用RTMP协议进行推流的时候,底层仍然采用的是TCP协议或者QUICK协议,有客户端主动发起请求.但是在有线投屏中,需要PC端向手机发起请求建立连接 二.实现 在客户端主动发起请求之 ...